
In 1997 the IBM Deep Blue supercomputer defeated world chess champion Garry Kasparov. It was a groundbreaking demonstration of supercomputer technology and a first glimpse into how high-performance computing might one day overtake human-level intelligence. In the 10 years that followed, we began to use artificial intelligence for many practical tasks, such as facial recognition, language translation, and recommending movies and merchandise.
Fast-forward another decade and a half and artificial intelligence has advanced to the point where it can “synthesize knowledge.” Generative AI, such as ChatGPT and Stable Diffusion, can compose poems, create artwork, diagnose disease, write summary reports and computer code, and even design integrated circuits that rival those made by humans.
Tremendous opportunities lie ahead for artificial intelligence to become a digital assistant to all human endeavors. ChatGPT is a good example of how AI has democratized the use of high-performance computing, providing benefits to every individual in society.
All those marvelous AI applications have been due to three factors: innovations in efficient machine-learning algorithms, the availability of massive amounts of data on which to train neural networks, and progress in energy-efficient computing through the advancement of semiconductor technology. This last contribution to the generative AI revolution has received less than its fair share of credit, despite its ubiquity.
Over the last three decades, the major milestones in AI were all enabled by the leading-edge semiconductor technology of the time and would have been impossible without it. Deep Blue was implemented with a mix of 0.6- and 0.35-micrometer-node chip-manufacturing technology. The deep neural network that won the ImageNet competition, kicking off the current era of machine learning, was implemented with 40-nanometer technology. AlphaGo conquered the game of Go using 28-nm technology, and the initial version of ChatGPT was trained on computers built with 5-nm technology. The most recent incarnation of ChatGPT is powered by servers using even more advanced 4-nm technology. Each layer of the computer systems involved, from software and algorithms down to the architecture, circuit design, and device technology, acts as a multiplier for the performance of AI. But it’s fair to say that the foundational transistor-device technology is what has enabled the advancement of the layers above.
If the AI revolution is to continue at its current pace, it’s going to need even more from the semiconductor industry. Within a decade, it will need a 1-trillion-transistor GPU—that is, a GPU with 10 times as many devices as is typical today.
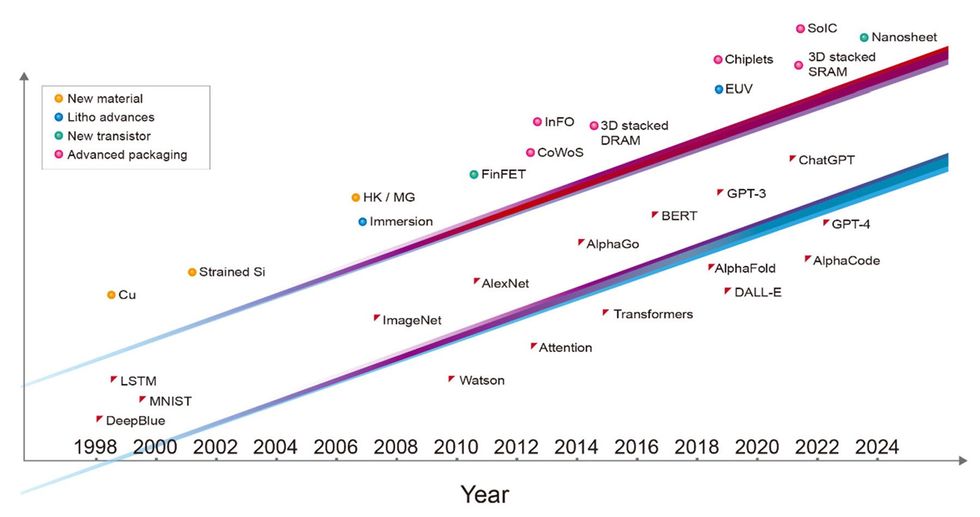 Advances in semiconductor technology [top line]—including new materials, advances in lithography, new types of transistors, and advanced packaging—have driven the development of more capable AI systems [bottom line]
Advances in semiconductor technology [top line]—including new materials, advances in lithography, new types of transistors, and advanced packaging—have driven the development of more capable AI systems [bottom line]
Relentless Growth in AI Model Sizes
The computation and memory access required for AI training have increased by orders of magnitude in the past five years. Training GPT-3, for example, requires the equivalent of more than 5 billion billion operations per second of computation for an entire day (that’s 5,000 petaflops-days), and 3 trillion bytes (3 terabytes) of memory capacity.
Both the computing power and the memory access needed for new generative AI applications continue to grow rapidly. We now need to answer a pressing question: How can semiconductor technology keep pace?
From Integrated Devices to Integrated Chiplets
Since the invention of the integrated circuit, semiconductor technology has been about scaling down in feature size so that we can cram more transistors into a thumbnail-size chip. Today, integration has risen one level higher; we are going beyond 2D scaling into 3D system integration. We are now putting together many chips into a tightly integrated, massively interconnected system. This is a paradigm shift in semiconductor-technology integration.
In the era of AI, the capability of a system is directly proportional to the number of transistors integrated into that system. One of the main limitations is that lithographic chipmaking tools have been designed to make ICs of no more than about 800 square millimeters, what’s called the reticle limit. But we can now extend the size of the integrated system beyond lithography’s reticle limit. By attaching several chips onto a larger interposer—a piece of silicon into which interconnects are built—we can integrate a system that contains a much larger number of devices than what is possible on a single chip. For example, TSMC’s chip-on-wafer-on-substrate (CoWoS) technology can accommodate up to six reticle fields’ worth of compute chips, along with a dozen high-bandwidth-memory (HBM) chips.
HBMs are an example of the other key semiconductor technology that is increasingly important for AI: the ability to integrate systems by stacking chips atop one another, what we at TSMC call system-on-integrated-chips (SoIC). An HBM consists of a stack of vertically interconnected chips of DRAM atop a control logic IC. It uses vertical interconnects called through-silicon-vias (TSVs) to get signals through each chip and solder bumps to form the connections between the memory chips. Today, high-performance GPUs use HBMextensively.
Going forward, 3D SoIC technology can provide a “bumpless alternative” to the conventional HBM technology of today, delivering far denser vertical interconnection between the stacked chips. Recent advances have shown HBM test structures with 12 layers of chips stacked using hybrid bonding, a copper-to-copper connection with a higher density than solder bumps can provide. Bonded at low temperature on top of a larger base logic chip, this memory system has a total thickness of just 600 µm.
With a high-performance computing system composed of a large number of dies running large AI models, high-speed wired communication may quickly limit the computation speed. Today, optical interconnects are already being used to connect server racks in data centers. We will soon need optical interfaces based on silicon photonics that are packaged together with GPUs and CPUs. This will allow the scaling up of energy- and area-efficient bandwidths for direct, optical GPU-to-GPU communication, such that hundreds of servers can behave as a single giant GPU with a unified memory. Because of the demand from AI applications, silicon photonics will become one of the semiconductor industry’s most important enabling technologies.
Toward a Trillion Transistor GPU
As noted already, typical GPU chips used for AI training have already reached the reticle field limit. And their transistor count is about 100 billion devices. The continuation of the trend of increasing transistor count will require multiple chips, interconnected with 2.5D or 3D integration, to perform the computation. The integration of multiple chips, either by CoWoS or SoIC and related advanced packaging technologies, allows for a much larger total transistor count per system than can be squeezed into a single chip. We forecast that within a decade a multichiplet GPU will have more than 1 trillion transistors.
We’ll need to link all these chiplets together in a 3D stack, but fortunately, industry has been able to rapidly scale down the pitch of vertical interconnects, increasing the density of connections. And there is plenty of room for more. We see no reason why the interconnect density can’t grow by an order of magnitude, and even beyond.
Energy-Efficient Performance Trend for GPUs
So, how do all these innovative hardware technologies contribute to the performance of a system?
We can see the trend already in server GPUs if we look at the steady improvement in a metric called energy-efficient performance. EEP is a combined measure of the energy efficiency and speed of a system. Over the past 15 years, the semiconductor industry has increased energy-efficient performance about threefold every two years. We believe this trend will continue at historical rates. It will be driven by innovations from many sources, including new materials, device and integration technology, extreme ultraviolet (EUV) lithography, circuit design, system architecture design, and the co-optimization of all these technology elements, among other things.
In particular, the EEP increase will be enabled by the advanced packaging technologies we’ve been discussing here. Additionally, concepts such as system-technology co-optimization (STCO), where the different functional parts of a GPU are separated onto their own chiplets and built using the best performing and most economical technologies for each, will become increasingly critical.
A Mead-Conway Moment for 3D Integrated Circuits
In 1978, Carver Mead, a professor at the California Institute of Technology, and Lynn Conway at Xerox PARC invented a computer-aided design method for integrated circuits. They used a set of design rules to describe chip scaling so that engineers could easily design very-large-scale integration (VLSI) circuits without much knowledge of process technology.
That same sort of capability is needed for 3D chip design. Today, designers need to know chip design, system-architecture design, and hardware and software optimization. Manufacturers need to know chip technology, 3D IC technology, and advanced packaging technology. As we did in 1978, we again need a common language to describe these technologies in a way that electronic design tools understand. Such a hardware description language gives designers a free hand to work on a 3D IC system design, regardless of the underlying technology. It’s on the way: An open-source standard, called 3Dblox, has already been embraced by most of today’s technology companies and electronic design automation (EDA) companies.
The Future Beyond the Tunnel
In the era of artificial intelligence, semiconductor technology is a key enabler for new AI capabilities and applications. A new GPU is no longer restricted by the standard sizes and form factors of the past. New semiconductor technology is no longer limited to scaling down the next-generation transistors on a two-dimensional plane. An integrated AI system can be composed of as many energy-efficient transistors as is practical, an efficient system architecture for specialized compute workloads, and an optimized relationship between software and hardware.
For the past 50 years, semiconductor-technology development has felt like walking inside a tunnel. The road ahead was clear, as there was a well-defined path. And everyone knew what needed to be done: shrink the transistor.
Now, we have reached the end of the tunnel. From here, semiconductor technology will get harder to develop. Yet, beyond the tunnel, many more possibilities lie ahead. We are no longer bound by the confines of the past.


