One of the most disconcerting things about artificial intelligence is that it transcends the power of nation states to control, contain, or regulate it. Yet it can yield frightening results, such as the drug-discovery AI that recently took a wrong turn into discovering deadly toxins that could be used as chemical weapons.
And there is no better example today of AI’s unfettered nature than EleutherAI, a loose association of computer scientists who have built a giant AI system to rival some of the most powerful machine-learning models on the planet. (The group take their name from the ancient Greek word for liberty, eleutheria.)
“We’re basically a bunch of weirdos hanging out in a chat room doing research for fun,” says Connor Leahy, one of the group’s founders. While EleutherAI is focused on AI safety, he said that their efforts clearly demonstrate that a small group of unorthodox actors can build and use potentially dangerous AI. “A bunch of hackers in a cave, figuring this out, is definitely doable,” he says.
The group’s latest effort is GPT-NeoX-20B, a 20-billion-parameter, pretrained, general-purpose, autoregressive dense language model. If you don’t know what that is, think of OpenAI’s GPT-3, the large language model that stunned the world nearly two years ago with its abilities that include writing everything from computer code to poetry—and fake news stories indistinguishable in style and tone from authoritative sources.
“It really was at first just a fun hobby project during lockdown times when we didn’t have anything better to do, but it quickly gained quite a bit of traction.”
—Connor Leahy, EleutherAI
OpenAI was also founded on the premise that AI should be open to all—thus the name. But when the research lab created GPT-2, the second iteration of its generative pretrained transformer model, the power of the model so disturbed OpenAI that they delayed its release. GPT-3 is now available only to select researchers and has been licensed exclusively by Microsoft for commercial application.
OpenAI’s model is, of course, larger than EleutherAI, with 175 billion parameters—the nodes or numbers inside the model that encode information. The more parameters, the greater and more granular the information that the model absorbs and, thus, the “smarter” the model is.
But EleutherAI’s is the largest and best performing model of its kind in the world that is freely and publicly available. About the only thing separating EleutherAI from OpenAI is the computing power needed to train the massive models.
OpenAI trained GPT-3 on an unspecified number of Nvidia V100 Tensor Core GPUs, some of the fastest chips ever built to accelerate AI. And OpenAI’s partner Microsoft has since developed a single system for large-model training with more than 285,000 CPU cores, 10,000 GPUs, and 400 gigabits per second of network connectivity for each GPU server.
That hasn’t stopped EleutherAI. They initially built a large language model with 6 billion parameters, using hardware provided by Google as part of its TPU Research Cloud Program. For GPT-NeoX-20B, the group received help from CoreWeave, a specialized cloud-services provider for GPU-based workloads.
“The current dominant paradigm of private models developed by tech companies beyond the access of researchers is a huge problem,” argues Stella Biderman, a mathematician and artificial-intelligence researcher of the EleutherAI consortium. “We—scientists, ethicists, society at large—cannot have the conversations we need to have about how this technology should fit into our lives if we do not have basic knowledge of how it works."
EleutherAI came together in July 2020 with a group of “mostly self-taught hackers” chatting on the social media platform Discord.
“It literally started with me half-jokingly saying we should try to mess around and see if we can build our own GPT-3-like thing,” Leahy said, “It really was at first just a fun hobby project during lockdown times when we didn’t have anything better to do, but it quickly gained quite a bit of traction.”
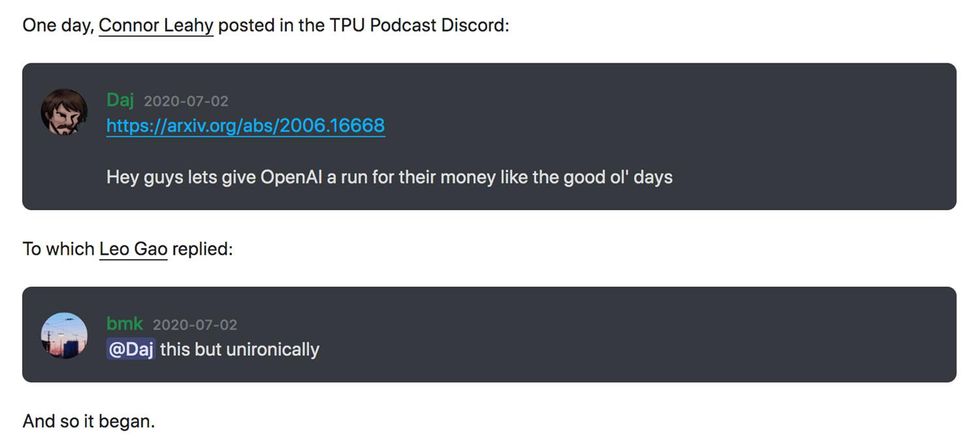 The origins of EleutherAI trace back to a Discord chat in the summer of 2020.
The origins of EleutherAI trace back to a Discord chat in the summer of 2020.
Together with fellow independent hobbyist hackers Sid Black and Leo Gao, Leahy founded the EleutherAI Discord server in July 2020. “We consider ourselves descendants of the classic hacker culture of a few decades before, just in new fields, experimenting with technology out of curiosity and love of the challenge.”
The Discord server now has about 10,000 members, though only about 100 or 200 people are regularly active. A core group of 10 to 20 people work on new applications such as GPT-NeoX-20B. There is no formal legal structure.
The group’s stated mission is to further research toward the safe use of AI systems by making models of this size accessible. In fact, unlike GPT-3, GPT-NeoX-20B, with the full model weights, is downloadable for free under a permissive Apache 2.0 license.
“We want more safety researchers to have access to this technology,” says Leahy, adding that it is shocking how little researchers understand the algorithms they are playing with. He said that after much debate, the group is “quite certain that the construction and release of such a model is net good for society because it will enable more safety-relevant research.”
In fact, EleutherAI’s work has already enabled research into the interpretability, security, and ethics of large language models. Nicholas Carlini, a major figure in the field of machine-learning security, said in a recent paper that “our research would not have been possible without EleutherAI’s complete public release of The Pile data set and their GPT-Neo family of models.” The Pile data set is an 825-gigabyte English text corpus for training large-scale language models.
Leahy believes the biggest risk of AI is not some person using it to do evil, but rather building a very powerful AI system that no one knows how to control.
“We have to think of AIs as weird aliens that don’t think like us,” he says, adding that AI is good at optimizing goals, but if given a stupid goal, the results could be unpredictable. He worries that researchers will be overconfident in the race to create increasingly powerful AIs, cutting corners in the process. “We need to study these systems to understand how we can control them.”
In 2019, Richard Sutton, regarded as the father of reinforcement learning, wrote an essay called “The Bitter Lesson,” which argued that “the only thing that matters in the long run is the leveraging of computation.” The real progress in AI, he argued, has come from the increasing availability of powerful computers applied to simple learning and search algorithms.
OpenAI has pursued just that strategy, beating Dota 2 world champions, creating a robotic hand controller dexterous enough to solve a Rubik’s cube, and finally its series of generative pretrained models, culminating so far in GPT-3.
Transformer algorithms used in large language models such as GPT-3 and EleutherAI’s GPT-NeoX-20B, have proved particularly suitable to improving with scale.
“What's really incredible is just making the model larger, just giving it more data, unlocks wholly new sets of skills without any human labeling or teaching,” says Leahy. A group at Tsinghua University has created a transformer-based model with 100 trillion parameters—comparable to the number of synapses in a human brain—although they have so far failed to train it to completion.
Leahy says that any group of like-minded computer scientists can build a large language model, but that because of the computing power required it would be hard to hide and potentially prohibitively expensive.
“It’s actually very difficult to get the right hardware to train a large language model,” he said, adding that it requires very high capital investment and there are only a few hundred companies that have that hardware today. “Right now, it’s not something you could do anonymously.”