
On 18 April 2024, Meta released the next big thing in “open” AI models: Llama 3. It’s the latest AI model to be offered by Meta free of charge and with a relatively open (though not open-source) license that lets developers deploy it in most commercial apps and services.
Announced less than a year after Llama 2, the new model in many ways repeats its predecessor’s playbook. Llama 3’s release provides models with up to 70 billion parameters, the same as its predecessor. It was also released under a similar license which, although not fully open source, allows commercial use in most circumstances.
Look closer, however, and Llama 3’s advancements come into focus. Meta’s new model scores significantly better than its predecessor in benchmarks without an increase in model size. The secret is training data—and lots of it.
“What I found most appealing was that at 15 trillion tokens [of training data], there was no stopping. The model was not getting worse,” said Rishi Yadav, founder and CEO of Roost.ai. “Not stopping at 15 trillion is profound. It means the sky’s the limit, at least as of today.”
For AI, more data is king
Meta has yet to release a paper on the details of Llama 3 (it’s promised to do so “in the coming months”), but its announcement revealed it was trained on 15 trillion tokens of data from publicly available sources. That’s over seven times as much data as Llama 2, which was trained on 2 trillion tokens. It may even rival GPT-4: OpenAI hasn’t revealed the number of tokens used to train GPT-4, but estimates put the number at around 13 trillion.
Llama 3’s vast training data translates to improved performance. The pretrained 70-billion-parameter model’s score in the Massive Multitask Language Understanding (MMLU) benchmark leapt from 68.9 with Llama 2 to 79.5 with Llama 3. The smallest model showed even greater improvement, rising from 45.3 with Llama 2 7B to 66.6 with Llama 3 8B. The MMLU benchmark, first put forward by a 2020 preprint paper, measures a model’s ability to answer questions across a range of academic fields.
Llama 3 also defeats competing small and midsize models, like Google Gemini and Mistral 7B, across a variety of benchmarks, including MMLU. These results prove that, at least for the moment, there’s no limit to the volume of training data that can prove useful.
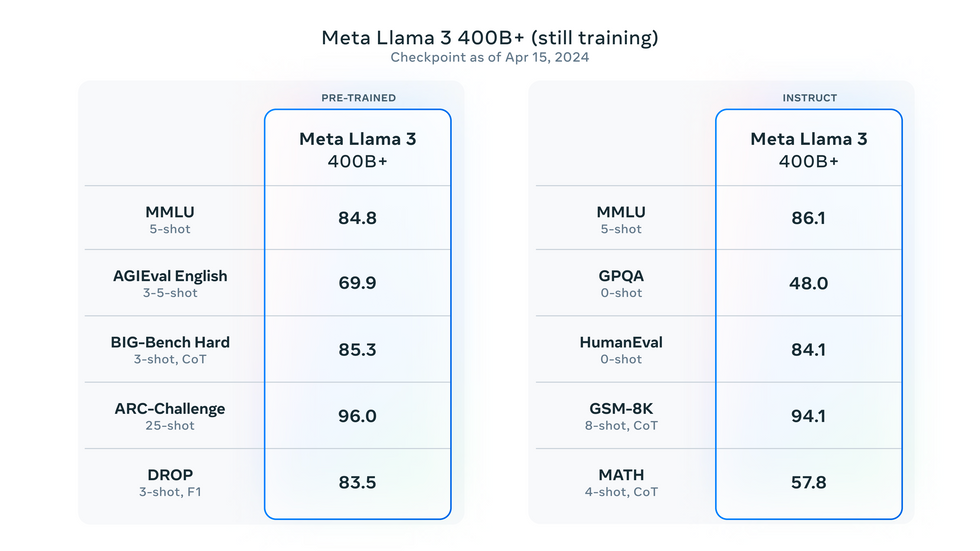 Llama 3 400B is still in training, but it already posts impressive benchmark results.Meta
Llama 3 400B is still in training, but it already posts impressive benchmark results.Meta
Meta also announced plans to push open models forward in another key metric: model size. A version of Llama 3 with 400 billion parameters is slated for release later this year. Meta stated the model is still in training but, as of 15 April, it claimed an MMLU benchmark score of 86.1. That’s only a hair behind GPT-4, which scored 86.4.
That achievement, if borne out in the final release, would easily leapfrog other large open models, like Falcon 180B and Grok-1. Llama 3 400B could become the first open LLM to match the quality of larger closed models like GPT-4, Claude 3 Opus, and Gemini Ultra.
Llama 3 is the open AI to beat
Meta’s ability to squeeze more performance out of a particular model size isn’t all that’s changed since Llama 2’s release in June of 2023. The company’s consistent pace and relatively open license has encouraged an enthusiastic response from the broader tech industry. Intel and Qualcomm immediately announced support for Llama 3 on their respective hardware; AMD made an announcement a day later.
“It’s gone from reactive to proactive,” said Ryan Shrout, president of the technical marketing company Signal 65 and former senior director of client strategy at Intel. “The idea of having some kind of prepared response, some kind of data, some kind of proactive announcement shows to me that the [hardware] vendors are maturing, and that the industry is maturing.”
Open-source developers have embraced Llama 3 with similar speed. Llama 3 8B tops the list of trending models on the AI developer hub Hugging Face, with over 275,000 downloads in its first five days. That far outpaces other recent releases: Mistral AI’s Mixtral-8x22B, which achieved benchmark scores only a hair behind Llama 3 70B, was downloaded fewer than 100,000 times in its first month.
Meta has drawn criticism over its approach to “open” AI. The license attached to Llama 3 doesn’t conform to any accepted open-source license, and some aspects of the model, such as the training data used, are not revealed in detail. Yet that criticism hasn’t halted Meta’s ascent and, with Llama 3, the company has entrenched its lead over competitors.
“In the open weights, what is going to happen is that if Llama 3 works out to be the standard, then everyone will use that. [...] I don’t think that anything else comes even close,” said Yadav. Shrout believes hardware manufacturers are lining up behind Llama for similar reasons. “Intel and AMD know that Llama is the largest mindshare model behind GPT. [...] They would be optimizing for it, because nothing else is going to get that kind of attention,” he said.
But while Meta has clearly established a lead in the open AI community, closed models, like GPT 4, are a different story. Llama 3 400B will narrow the gap, but the release of GPT 5—speculated to drop this summer—could steal Meta’s thunder if it once again raises the bar on quality.
Still, Yadav is optimistic that Llama 3 will assert itself as the leading model among developers looking to explore and experiment with AI. Cost remains a concern, too, and Llama should remain the most appealing option for anyone looking to dabble in AI with existing hardware resources.
“Let’s say you want to do this [AI] exploration, and it’s extensive. You don’t want your boss to come and say, why do I see this [US] $800,000 [API] bill from last month?” said Yadav. “Basically, for the Wild West, I think Llama 3 is a gift.”


