With some limited exceptions, robots are terrible at doing almost everything that humans take for granted. For people who work with robots, this is normal and expected, but for everyone else, it’s not immediately clear just how terrible robots are, especially if the robot in question looks human-like enough to generate expectations of human-like capability. Bimanual mobile manipulators like PR2 are particularly bad, because with heads and bodies and arms, it’s easy to look at them and think that they should have no problem doing all kinds of things. And then, of course, comes the inevitable disappointment when you realize that (among other things) round doorknobs make for an impassable obstacle.
At the ACM/IEEE International Conference on Human Robot Interaction (HRI) earlier this month, researchers from Cornell and UC Berkeley presented some work on how robots can effectively express themselves when they’re incapable of doing a task. Rather than just failing to do something and then sitting there helpless and immobile, it would be much more useful if the robot could communicate what it’s trying to accomplish along with why it’s unable to accomplish it in simple, gestural terms that anyone can understand.
As the researchers explain in their HRI paper:
Our key insight is that a robot can express both what it wants to do and why it is incapable of doing it by solving an optimization problem: That of executing a trajectory similar to the trajectory it would have executed had it been capable, subject to constraints capturing the robot’s limitations.
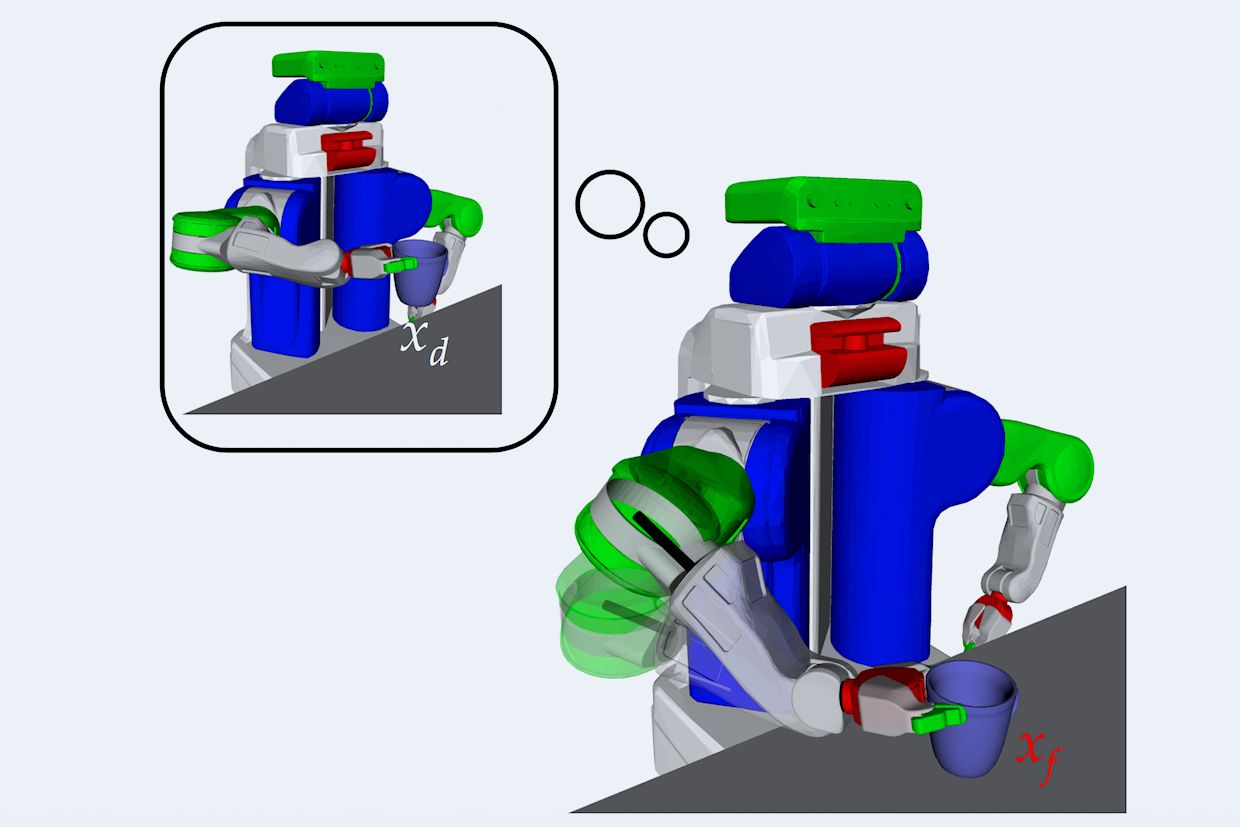
Take lifting a cup that is too heavy as an example, or turning a valve that is stuck. Once the robot realizes that it is incapable of completing the task, the robot would find some motion that still conveys what the task is and sheds light on the cause of incapability, all without actually making any more progress on lifting the cup or turning the valve.
A motion that “sheds light on the cause of incapability” is one that intuitively communicates to an untrained observer both what the robot intends to do, and why it’s failing. Basically, the robot turns itself into a mime, making exaggerated expressive motions that convey intent.
The video associated with the paper has a bunch of examples, and you can see that a useful and accurate expressive motion isn’t necessarily that easy to come by:
The really cool thing here is that these expressive motions are generated completely automatically, rather than being scripted by hand in advance. Essentially, this is an optimization problem, where the robot searches for a motion that’s as close as possible to the motion that it would be making if it were successful, while also keeping in mind that there’s a thing that’s causing the motion to fail. To use the very heavy cup as an example, the robot finds a trajectory where its arm tries to make a successful “lifting cup” motion, while constrained by the failure point, which is that the cup doesn’t move.
To test how well this works, the researchers conducted a study where participants were asked to watch videos of the robot making motions expressing incapability and attempt to identify both what the robot was trying to achieve, and why it wasn’t able to. They compared these motions with a more conventional “repeated failure” motion—to use the heavy cup as an example, the robot would simply go from a rest position to grasping the cup and back to a rest position.
It won’t surprise you to learn that motions expressing incapability improved both goal recognition and cause of incapability recognition, but what might be more surprising is just how much of a positive improvement these motions made to the overall perception of the robot:

This is certainly a significant improvement in how the users felt about the robot, and with some grasping and manipulation tasks, the generation of expressive motions like these can now be done automatically. The technique only works for this limited subset of tasks, though, and can't (yet) effectively address all of the other reasons for robot failures. There are lots and lots (and lots) of those, we know, but that's exactly why research like this is so important.