
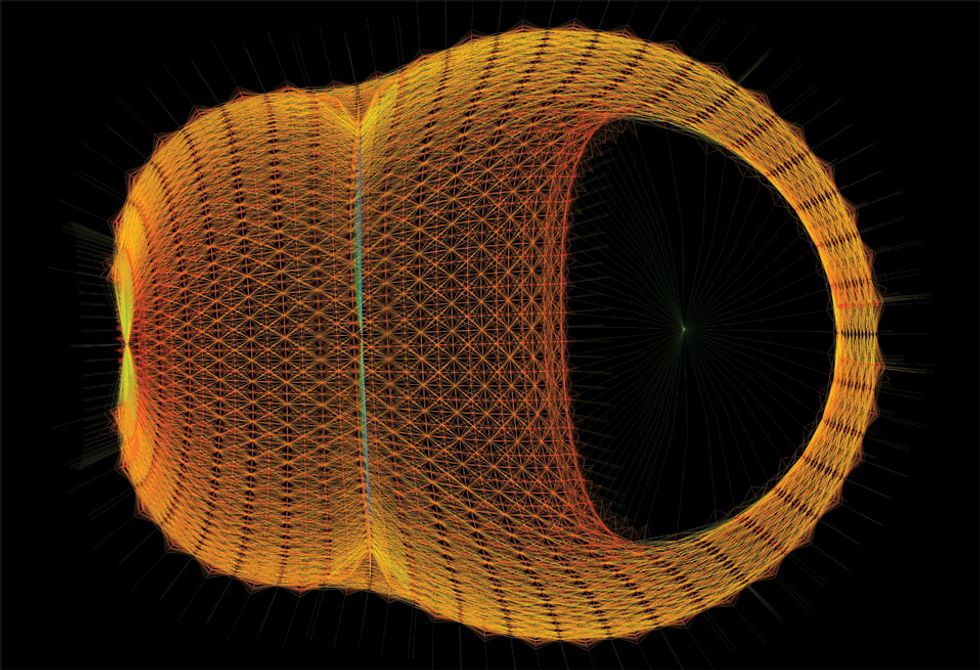
Image: Yifan Hu/AT&T Labs Visualization Group
Click on image to enlarge.
You're looking at the solution to a computational fluid dynamics problem. It is one of thousands of math-based artistic renderings stored in a database maintained by computer scientists from the University of Florida, in Gainesville, and AT&T Labs Research, in Florham Park, N.J. But what you don't see makes all the difference. The matrix, or table of values, is sparse, meaning that the number of zeros it contains far outweighs the number of nonzero values. This sparsity allows for a type of data compression that lets engineers working on a simulation store the data without taking up too big a chunk of memory.
The Conversation (0)


