People Who Read This Article Also Read...
The recommendation systems that suggest books at Amazon and movies at Netflix will soon bring you personalized news

The newspaper, that daily chronicle of human events, is undergoing the most momentous transformation in its centuries-old history. The familiar pulp-paper product still shows up on newsstands and porches every morning, but online versions are proliferating, attracting young readers and generally carving out a sizable swath of the news business. In the United States alone, 34 million people have made a daily habit of reading an online newspaper, according to the Newspaper Association of America.
It’s just the beginning. Online news will inevitably grow at the expense of its traditional counterpart because the Web not only lowers production and distribution costs, it also opens up newspapers to entirely new formats. Even run-of-the mill Web servers with access to a reasonable supply of news stories can generate thousands of different versions of a newspaper. Yet so far, few newspaper sites look different from the pulp-and-ink papers that spawned them. Editors still manually choose and lay out news stories. Often, the front page changes only once a day, just like the print version, and it shows the same news to all readers.
There’s no need for that uniformity. Every time a Web server generates a news page, for example, in response to a reader’s clicking on a link, it can create that page from scratch. An online news site can change minute by minute. And it can even generate different front pages, essentially producing millions of distinct editions, each one targeting just one person—you. Unless and until they do so, online newspapers will become increasingly irrelevant as the stories that are important to you get buried in an Internet already filled with absurdly more information than any one person can use.
The most interesting and important way to customize a site is to create a page of stories based on your unique interests culled from information about your past reading behavior. There’s already a model for that—the recommendation systems used by Amazon, TiVo, and Netflix. Using information on past purchases, movie ratings, or items viewed, these systems steer consumers to items from among the thousands or millions they have on offer. Newspapers can and should borrow this idea.
It could transform the industry. Based on articles viewed, these systems could highlight the ones they think a reader would find most interesting, even presenting them in order, with the most interesting article first. No longer would readers have to skim pages of news to find what they needed. No longer would reporters have to battle for the limited space on the front page.
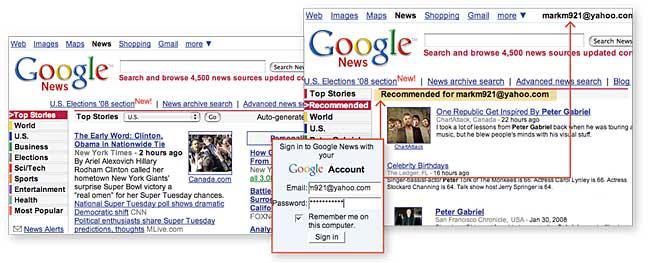
In their uphill battle to stay relevant, newspapers will first have to catch up with other news sites that already customize their front pages in one way or another. Aggregators such as Google News, My Yahoo, and Netvibes allow a reader to configure the layout of his or her personal page so that it highlights the most popular or highly regarded news. These sites also cluster news by topic or category and let readers focus on the articles that interest them the most. Such innovations are useful, but they still fall short of what’s needed. My Yahoo, for example, requires users to configure the page themselves and to make changes when their interests do, instead of accurately inferring those changes from whatever has attracted the user’s attention lately.
Google News is the best of the bunch, a popular news site that does use software to automate the prioritizing and laying out of stories. It changes rapidly, clusters stories that focus on the same event, allows users to customize the site, and recommends news based on past reading habits. But news sites could do even better by automatically learning what news stories each reader wants and using that knowledge to “print” millions of personalized editions of the newspaper.
Such features aren’t far off—they were actually part of a news aggregation Web site called Findory.com, which I ran between 2004 and 2007. Findory built a unique, personalized front page for each reader, based on what he or she had read in the past. In so doing it showed a way by which newspapers could recommend information much as Amazon recommends books.
Newspapers constitute a US $55 billion business in the United States, yet that business is invariably described as troubled. Many readers still feel loyalty to their hometown newspaper and know it is likely to contain news relevant to them, but they are increasingly reluctant to wade through all its articles to find the few that matter to them. Personalized news recommendations can be a lifesaver to newspapers that are drowning in the sea of information that washes over us all.
IT MAY SEEM A SMALL STEP from recommending products to recommending information. In fact, doing so is actually quite complex. Stand at the entrance of a Wal-Mart or look at Amazon’s home page and the shiny world of each one’s wares seems limitless. But it’s not. It is firmly bounded by the constraints of time and warehouse space. A sprawling Wal-Mart store typically has about 100 000 items; Amazon carries a few million. The world of information, on the other hand, is measured in billions of pages and petabytes of data. Processing data on this scale can require a supercomputer-scale infrastructure well beyond the means of a city newspaper.
Recommender systems also face what is known as the cold-start problem, which stems from the difficulty of rating any item that either has not yet attracted the notice of recommenders or has attracted only those about whom nothing is known. For example, before a new movie is previewed by critics, no one at all has seen it, so no one can recommend it. Within weeks, though, enough people will have contributed opinions to help many others decide whether to see it. But a news article doesn’t have weeks to attract attention, only hours. Often, by the time a fair number of people have read the article, it may well have faded into irrelevance. As we’ll see, one of Findory’s goals was to ameliorate the cold-start problem.
To understand how a really successful recommendation system for news might work, first consider those being used now at sites like Amazon and Netflix. One of the fundamental characteristics of these systems is that they learn not just from your behavior but also from that of other customers. The underlying assumption is that there are other people out there who are like you and that those people have found and enjoyed things you haven’t yet seen. These algorithms search over Web-site logs, ratings, and purchase transactions to discover people with interests similar to your own. Then the algorithms look up the items those people liked and recommend them to you.
Suppose that many people who buy the textbook Managing Gigabytes also buy Lucene in Action; the algorithm will conclude that the books may be similar, particularly if the people who buy Managing Gigabytes buy Lucene in Action much more frequently than the general population does. Even if the books are on different topics and the texts of the books are not similar, purchases in common reveal books with similar appeal. People who buy books on information technology may, for instance, also tend to buy science fiction.
More generally, if the recommendation system can find users who have bought many things you have bought, then it will bring to your attention things these other people have bought that you have not. This kind of algorithm is often referred to as collaborative or social filtering because it uses the preferences of like-minded people in the community to filter and prioritize what you see.
Because it’s so difficult to apply recommendation algorithms to information, sites have tried to personalize news in other ways. One of the largest customizable news sites, My Yahoo, launched in July of 1996. A user chooses from hundreds of modules—including news, weather, sports scores, and stock prices—and picks the layout of these modules on the page. User-customized sites are simple to build, easy for readers to understand, and take advantage of the ability of online news sites to show a different front page to each reader. By customizing, readers can emphasize the news most important to them.
Unfortunately, most readers don’t. Research at Yahoo has found that most users do not customize their front pages and that most who do don’t bother to update those pages to reflect their changing interests.
GOOGLE NEWS, arguably the leading site when it comes to personalized news, goes several steps further, automating things as much as possible. For example, it uses a technique called implicit personalization to recommend different content to each reader, based on the reader’s past behavior. It’s an innovation that suggests a way forward for the news business. But first, consider how Google News accomplishes two other seemingly simple automation chores: ranking and clustering stories.
{kind=link}
Google is, of course, famous for its method of ranking search results. In the case of news, it forms an understanding of which stories are generally the most interesting and important and continually updates a reader’s personal home page with that in mind. Google News collects millions of articles from thousands of sources, so it would be out of the question to use a staff of editors to lay out the front page, as most news sites do. Krishna Bharat, who led the development of Google News, says that its algorithm ranks stories according to the authority of the news source, the timeliness of the article, whether the article is an original piece, where the article was originally placed by the editors on the source Web site, the apparent scope and impact on readers, and the popularity of the article.
Google News also clusters stories on the same news event. Clustering gives readers the benefit of diversity, which is particularly useful to readers of international news. For example, a French paper might take a profarmer stance when covering a trade dispute on European Union farming subsidies, while a British newspaper might have a very different view. Another advantage of clustering is that it can either eliminate or call explicit attention to duplicate articles, such as when two newspapers run the same Associated Press wire story.
But the task of clustering news stories on the same event encompasses several subchores, some of them fairly difficult. One of them is simply defining what we mean by “same event”—an ill-defined, surprisingly hard problem. For instance, stories about the escape of a tiger from the San Francisco Zoo last December included articles on how the animal may have gotten free, how it killed a visitor, how it mauled two other people, how it was itself killed by police officers. Are they all the same event?
Google News tackles this problem by using a technique called hierarchical agglomerative clustering. Basically, it puts news articles with similar phrasing together into distinct piles. It starts by analyzing the content of articles to find those that share keywords or key phrases; articles that have enough language in common are assumed to be covering similar topics. The articles in each pile are connected based on the strength of their similarity. To visualize these connections, imagine a treelike structure where the articles are the leaves. If we grab a branch from the tree, the many leaves on that branch are all similar articles—that is, articles about the same general event. Thus a group of leaves near one another on a branch of the tree constitutes a cluster.
This tree is constantly changing. As more and more stories accrue on a general event, the threshold for determining whether any two of those stories are about the same aspect of that event becomes higher. The clusters may shift, with articles jumping out to new groups or old groups that are splitting or combining. The groupings adapt to the news available, which is always changing.
If the ideal result is a newspaper featuring the news you want to see, these clustering and ranking strategies can take you only so far. They can determine whether a new development in a story you’ve been following is something that might interest you. But they can’t make a logical leap—for example, recognizing from your previous interest in articles on the search for extraterrestrial intelligence that you would be fascinated by the discovery of an Earth-like planet in another solar system.
To make this kind of inference requires figuring out an individual reader’s interests and accurately recommending new articles based on those interests, just as Amazon and Netflix recommend books and movies. Toward this end, rather than showing top stories of general interest, the Google News recommendation engine attempts to figure out what each reader’s top stories should be. The recommender analyzes the past clicks of all readers, the past clicks of the current reader on the Web site, and the currently available news stories and then generates a list of news stories that may be of interest.
Because of the enormous number of articles and users on Google News, traditional clustering methods were impractical. So Google tested three more advanced algorithms for generating news recommendations: MinHash clustering, Probabilistic Latent Semantic Indexing (PLSI), and covisitation counts.
MinHash and PLSI are both essentially clustering methods. That is, they try to group similar items or users. MinHash works by randomizing a numbered list of all possible articles. It then finds the first of those articles the reader has seen and gives it a numerical value, called the index, which is simply its position in the randomized list. As it turns out, the probability that two users will have the same index is equal to a statistical measure of their commonality—the items they have viewed in common—which is called the Jaccard similarity coefficient. Given two sets of things (say, magazine articles that two people have read), the Jaccard coefficient equals the size of their intersection (here, the articles both people have read) divided by the size of their union (the articles that either of them has read). The upshot is that by grouping users with the same index value, MinHash can find clusters of similar users.
PLSI is another clustering technique that determines the similarity between users. To visualize its operation, imagine a massive, largely unpopulated matrix where the rows are articles and the columns are readers. You as a reader will have an entry in this matrix on every row that contains an article you’ve read. PLSI attempts to reduce this matrix to a form that can concisely, albeit approximately, model all combinations of possible users and items. The technique introduces a variable that captures the relationships between items and users. This variable allows you to capture in an algebraic formula the co-occurrences between items and users—the articles they have in common—and in effect forms groups of like-minded users and groups of similar items. These groupings produce the clusters.
The third method that Google News uses, covisitation, is a collaborative filtering algorithm that looks at all the people who’ve read a given article and then computes the chances that they will also have looked at other articles. This is similar to the well-known “Customers who bought X also bought...” feature on the Amazon Web site.
For each news story and for each reader who clicked on it, Google looks at all the other news stories that the reader has clicked on. Pairs of stories that have a lot of readers in common are considered covisited. Because all the covisited articles are precomputed from historical data, computation on the Web site’s database—massive though it is—turns out to be relatively quick and efficient.
Once all the users are lumped into clusters and the list of covisited articles is built, the job of finding articles of interest to any one user is mostly a matter of data lookups. Google News first looks up the clusters for that reader and his or her recently clicked articles and then creates a list of candidate recommendations by using the most popular stories in the clusters and the covisited articles. It then ranks the candidates to determine which will be used for the recommendations.
In a presentation at the 2007 International World Wide Web Conference, Abhinandan Das and two of his colleagues at Google reported that they were able to generate 38 percent more click-throughs with such news recommendations than with a standard list of popular news stories. In other words, the recommendations very clearly helped readers find news of interest to them.
GOOGLE WAS NOT ALONE in coming up with a system for implicit news personalization. A number of companies have worked on the problem, including my own (which proved to be more successful as a research project than as a commercial operation). Findory built a unique front page of news for each reader. We aggregated news and blog articles from thousands of sources around the world and learned each reader’s interests from past behavior. Unlike other sites, Findory completely automated the routing of news articles to individual readers; there was no manual customization. A user could change his or her Findory profile only by reading news articles on the site.
When a reader first came to Findory, the Web site started by showing a generic, or default, front page of news, mostly the popular news stories of the day. At the first click on an article, Findory started to change. Reading an article was treated as an expression of interest in that news event. As the clicks continued, the front page drifted further away from the default, quickly filling with articles picked for that reader and building a personalized front page.
For example, if a reader came to Findory and clicked on an article on the U.S. dollar, Findory might add articles on the stock market, oil prices, and the Japanese yen to his or her front page. If the user then clicked on a news article about the value of the U.S. dollar, related articles would be added to the Findory front page, perhaps an article on the euro, another on the Chinese export market, and a third on the price of oil.
Findory’s software learned which categories of news and which news sources each reader frequented. For example, if a reader often looked at business stories from The New York Times, not only would a prominent link to the Times appear but the business section would also be moved to the top of the page, pushing down other categories, such as entertainment or health news.
Findory’s software also made it easy to relocate information that the user had found once before. A 2007 study by Jaime Teevan and three other researchers showed that as many as 40 percent of Web search queries are repeats. So Findory kept a history of articles that a user had read recently. It took only a couple of clicks to return to a story a reader had seen a week before.
The core of Findory’s implicit personalization of the site was its recommendation engine. We used a hybrid algorithm that combined statistics on what people read with analyses of the content of articles. The first part of the algorithm looked at correlations in reader behavior. Like the Google News covisitation algorithm, Findory’s algorithm built a database of “Readers who clicked on X also clicked on Y.” When a reader came to the site, Findory retrieved all the articles that the reader had read, looked up other articles that tended to interest the readers who read those same articles, and then reranked and recommended those articles.
Unlike Google News covisitation, Findory’s hybrid algorithm didn’t ignore the content of an article. The second part of the hybrid collaborative filtering supplemented the data on what articles readers click on with an analysis that primarily looked at sources, keywords, and key phrases to find articles with similar content, on similar topics, or about similar events. For example, if a new reader came to Findory and read an article on a new DSL technology, an article on wireless broadband might be shown because other readers who read that article on DSL also found the wireless broadband article interesting. An article on cable modems might be featured, just because it was new and matched on broadband during content analysis, and a story on Internet movie downloading could be shown, both because of reader behavior and because it mentioned broadband.
Such content analysis addresses the cold-start problem. Without it, there is no way to tell who might want to read an article on that tiger that escaped from the San Francisco Zoo; with it, you could make the educated guess that it would appeal to people who live in the Bay Area who have a penchant for animal stories, police stories, and so forth.
Here’s how it worked. When a news story first entered Findory, of course no one had read it yet. So Findory fell back to analyzing the content in order to find related articles. In addition, to further acquire click data, Findory would randomly show new articles to some readers to gather more information about them, a process known as exploration.
The goal of Findory’s recommendation engine was to use readers to help other readers. When a reader had read an article, Findory automatically shared that article with other readers—that is, Findory interpreted clicking on an article as an expression of interest in it. Readers with interests similar to those of the current reader may thus have been interested in it too. As more people clicked on that same article, the evidence that the article was useful and interesting grew, and Findory would recommend it more broadly.
Findory could be thought of as a social network. Each reader was joined to others by common interests. When a reader found interesting news, the article was shared with just those other readers.
Findory, unlike explicit social networks, did all connections and sharing implicitly. Readers were matched to other readers quietly, behind the scenes. There are two benefits to this scheme. The first is that it maintains privacy—you don’t know which readers the system considers similar to you. The second is the way the system is able to reach beyond your network, beyond people you know, to find experts in the community whom you have never met.
NEWSPAPERS WILL HARDLY be the last step in personalization. The ultimate goal will be to all information. We are deluged by information; we are saturated in it and overwhelmed by it. It is a problem that will only get worse.
In a world of personalized information, incoming messages would be prioritized by the importance of the contact and the cost of an interruption. All sites, not just newspapers, would organize and order articles according to your interests. Search engines would learn from your behavior, adapt to your interests, and focus on what you need. Ordinary programs, such as e-mail and spreadsheets, would bring to the surface relevant information just when you need it, even without an explicit query. Even advertising would be helpful and relevant.
Building this world of personalized information will require solving problems in machine learning that are particularly hard, given the crushing amounts of data. Computer software will have to scour billions of documents, petabytes of data, and billions of actions by users, learning not only what each person may want but also how and when to bring helpful information to the surface. This software may reside on our desktops, living beside us like a friendly and knowledgeable assistant, burning spare processor cycles in the background to seek out and bring back information we need. Or the software may be located on the Internet cloud, tearing across the supercomputing clusters owned by Google and others, digging through vast volumes of data and ferreting out the knowledge buried there. Either way, the computing power needed will be staggering.
All information sources—including news, messages, advertising, contacts, and Web documents—should be prioritized based on relevance and need. Recommendations and personalization can help by learning from your behavior, adapting to your interests, and providing relevant information instead of leaving you to make a tedious search on your own.
About the Author
GREG LINDEN lives in Seattle and works at Microsoft Live Labs. In 2004, he formed Findory.com, which sought to personalize the flow of information. He worked at Amazon.com from 1997 to 2002, first writing its recommendation engine and then leading the software team that developed Amazon’s personalization systems. Linden makes the case for recommender systems in “People Who Read This Article Also Read…”.
To Probe Further
The paper by Abhinandan Das and his colleagues, “Google News Personalization: Scalable Online Collaborative Filtering,” is available at https://www2007.org/paper570.php. Also worth reading is another paper from the same conference, “A Large-scale Evaluation and Analysis of Personalization Search Strategies,” by Z. Dou et al., at https://www2007.org/program/paper.php?id=495.
Two noteworthy papers from other conferences are L. Shih and D. Karger’s “Using URLs and Table Layout for Web Classification Tasks” (https://citeseer.ist.psu.edu/shih04using.html) and “Information Re-Retrieval: Repeat Queries in Yahoo’s Logs,” by J. Teevan et al. (https://people.csail.mit.edu/teevan/work/publications/papers/sigir07.pdf).