
If you're on Facebook, click on “Why am I seeing this ad?" The answer will look something like “[Advertiser] wants to reach people who may be similar to their customers" or “[Advertiser] is trying to reach people ages 18 and older" or “[Advertiser] is trying to reach people whose primary location is the United States." Oh, you'll also see “There could also be more factors not listed here." Such explanations started appearing on Facebook in response to complaints about the platform's ad-placing artificial intelligence (AI) system. For many people, it was their first encounter with the growing trend of explainable AI, or XAI.
But something about those explanations didn't sit right with Oana Goga, a researcher at the Grenoble Informatics Laboratory, in France. So she and her colleagues coded up AdAnalyst, a browser extension that automatically collects Facebook's ad explanations. Goga's team also became advertisers themselves. That allowed them to target ads to the volunteers they had running AdAnalyst. The result: “The explanations were often incomplete and sometimes misleading," says Alan Mislove, one of Goga's collaborators at Northeastern University, in Boston.
When advertisers create a Facebook ad, they target the people they want to view it by selecting from an expansive list of interests. “You can select people who are interested in football, and they live in Cote d'Azur, and they were at this college, and they also like drinking," Goga says. But the explanations Facebook provides typically mention only one interest, and the most general one at that. Mislove assumes that's because Facebook doesn't want to appear creepy; the company declined to comment for this article, so it's hard to be sure.
Google and Twitter ads include similar explanations. All three platforms are probably hoping to allay users' suspicions about the mysterious advertising algorithms they use with this gesture toward transparency, while keeping any unsettling practices obscured. Or maybe they genuinely want to give users a modicum of control over the ads they see—the explanation pop-ups offer a chance for users to alter their list of interests. In any case, these features are probably the most widely deployed example of algorithms being used to explain other algorithms. In this case, what's being revealed is why the algorithm chose a particular ad to show you.
The world around us is increasingly choreographed by such algorithms. They decide what advertisements, news, and movie recommendations you see. They also help to make far more weighty decisions, determining who gets loans, jobs, or parole. And in the not-too-distant future, they may decide what medical treatment you'll receive or how your car will navigate the streets. People want explanations for those decisions. Transparency allows developers to debug their software, end users to trust it, and regulators to make sure it's safe and fair.
The problem is that these automated systems are becoming so frighteningly complex that it's often very difficult to figure out why they make certain decisions. So researchers have developed algorithms for understanding these decision-making automatons, forming the new subfield of explainable AI.
In 2017, the Defense Advanced Research Projects Agency launched a US $75 million XAI project. Since then, new laws have sprung up requiring such transparency, most notably Europe's General Data Protection Regulation, which stipulates that when organizations use personal data for “automated decision-making, including profiling," they must disclose “meaningful information about the logic involved." One motivation for such rules is a concern that black-box systems may be hiding evidence of illegal, or perhaps just unsavory, discriminatory practices.
 Think Globally, Act Locally: People sometimes seek global explanations (black), which describe how an AI “black box" works in general. Moreoften, though, they seek only local explanations, ones that describe why one particular set of inputs leads to a certain output (red, blue, green).Illustration: Spectrum Staff
Think Globally, Act Locally: People sometimes seek global explanations (black), which describe how an AI “black box" works in general. Moreoften, though, they seek only local explanations, ones that describe why one particular set of inputs leads to a certain output (red, blue, green).Illustration: Spectrum Staff
As a result, XAI systems are much in demand. And better policing of decision-making algorithms would certainly be a good thing. But even if explanations are widely required, some researchers worry that systems for automated decision-making may appear to be fair when they really aren't fair at all.
For example, a system that judges loan applications might tell you that it based its decision on your income and age, when in fact it was your race that mattered most. Such bias might arise because it reflects correlations in the data that was used to train the AI, but it must be excluded from decision-making algorithms lest they act to perpetuate unfair practices of the past.
The challenge is how to root out such unfair forms of discrimination. While it's easy to exclude information about an applicant's race or gender or religion, that's often not enough. Research has shown, for example, that job applicants with names that are common among African Americans receive fewer callbacks, even when they possess the same qualifications as someone else.
A computerized résumé-screening tool might well exhibit the same kind of racial bias, even if applicants were never presented with checkboxes for race. The system may still be racially biased; it just won't “admit" to how it really works, and will instead provide an explanation that's more palatable.
Regardless of whether the algorithm explicitly uses protected characteristics such as race, explanations can be specifically engineered to hide problematic forms of discrimination. Some AI researchers describe this kind of duplicity as a form of “fairwashing": presenting a possibly unfair algorithm as being fair.
Whether deceptive systems of this kind are common or rare is unclear. They could be out there already but well hidden, or maybe the incentive for using them just isn't great enough. No one really knows. What's apparent, though, is that the application of more and more sophisticated forms of AI is going to make it increasingly hard to identify such threats.
No company would want to be perceived as perpetuating antiquated thinking or deep-rooted societal injustices. So a company might hesitate to share exactly how its decision-making algorithm works to avoid being accused of unjust discrimination. Companies might also hesitate to provide explanations for decisions rendered because that information would make it easier for outsiders to reverse engineer their proprietary systems. Cynthia Rudin, a computer scientist at Duke University, in Durham, N.C., who studies interpretable machine learning, says that the “explanations for credit scores are ridiculously unsatisfactory." She believes that credit-rating agencies obscure their rationales intentionally. “They're not going to tell you exactly how they compute that thing. That's their secret sauce, right?"
And there's another reason to be cagey. Once people have reverse engineered your decision-making system, they can more easily game it. Indeed, a huge industry called “search engine optimization" has been built around doing just that: altering Web pages superficially so that they rise to the top of search rankings.
Why then are some companies that use decision-making AI so keen to provide explanations? Umang Bhatt, a computer scientist at the University of Cambridge and his collaborators interviewed 50 scientists, engineers, and executives at 30 organizations to find out. They learned that some executives had asked their data scientists to incorporate explainability tools just so the company could claim to be using transparent AI. The data scientists weren't told whom this was for, what kind of explanations were needed, or why the company was intent on being open. “Essentially, higher-ups enjoyed the rhetoric of explainability," Bhatt says, “while data scientists scrambled to figure out how to implement it."
The explanations such data scientists produce come in all shapes and sizes, but most fall into one of two categories: explanations for how an AI-based system operates in general and explanations for particular decisions. These are called, respectively, global and local explanations. Both can be manipulated.
Ulrich Aïvodji at the Université du Québec, in Montreal, and his colleagues showed how global explanations can be doctored to look better. They used an algorithm they called (appropriately enough for such fairwashing) LaundryML to examine a machine-learning system whose inner workings were too intricate for a person to readily discern. The researchers applied LaundryML to two challenges often used to study XAI. The first task was to predict whether someone's income is greater than $50,000 (perhaps making the person a good loan candidate), based on 14 personal attributes. The second task was to predict whether a criminal will re-offend within two years of being released from prison, based on 12 attributes.
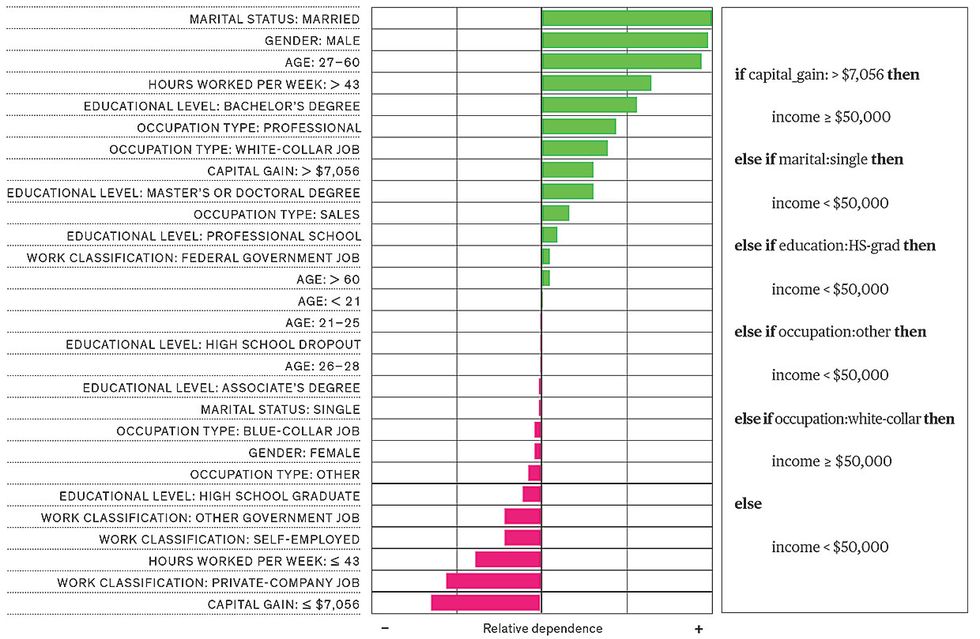
Unlike the algorithms typically applied to generate explanations, LaundryML includes certain tests of fairness, to make sure the explanation—a simplified version of the original system—doesn't prioritize such factors as gender or race to predict income and recidivism. Using LaundryML, these researchers were able to come up with simple rule lists that appeared much fairer than the original biased system but gave largely the same results. The worry is that companies could proffer such rule lists as explanations to argue that their decision-making systems are fair.
Another way to explain the overall operations of a machine-learning system is to present a sampling of its decisions. Last February, Kazuto Fukuchi, a researcher at the Riken Center for Advanced Intelligence Project, in Japan, and two colleagues described a way to select a subset of previous decisions such that the sample would look representative to an auditor who was trying to judge whether the system was unjust. But the craftily selected sample met certain fairness criteria that the overall set of decisions did not.
Organizations need to come up with explanations for individual decisions more often than they need to explain how their systems work in general. One technique relies on something XAI researchers call attention, which reflects the relationship between parts of the input to a decision-making system (say, single words in a résumé) and the output (whether the applicant appears qualified). As the name implies, attention values are thought to indicate how much the final judgment depends on certain attributes. But Zachary Lipton of Carnegie Mellon and his colleagues have cast doubt on the whole concept of attention.
These researchers trained various neural networks to read short biographies of physicians and predict which of these people specialized in surgery. The investigators made sure the networks would not allocate attention to words signifying the person's gender. An explanation that considers only attention would then make it seem that these networks were not discriminating based on gender. But oddly, if words like “Ms." were removed from the biographies, accuracy suffered, revealing that the networks were, in fact, still using gender to predict the person's specialty.
“What did the attention tell us in the first place?" Lipton asks. The lack of clarity about what the attention metric actually means opens space for deception, he argues.
Johannes Schneider at the University of Liechtenstein and others recently described a system that examines a decision it made, then finds a plausible justification for an altered (incorrect) decision. Classifying Internet Movie Database (IMDb) film reviews as positive or negative, a faithful model categorized one review as positive, explaining itself by highlighting words like “enjoyable" and “appreciated." But Schneider's system could label the same review as negative and point to words that seem scolding when taken out of context.
Another way of explaining an automated decision is to use a technique that researchers call input perturbation. If you want to understand which inputs caused a system to approve or deny a loan, you can create several copies of the loan application with the inputs modified in various ways. Maybe one version ascribes a different gender to the applicant, while another indicates slightly different income. If you submit all of these applications and record the judgments, you can figure out which inputs have influence.
That could provide a reasonable explanation of how some otherwise mysterious decision-making systems work. But a group of researchers at Harvard University led by Himabindu Lakkaraju have developed a decision-making system that detects such probing and adjusts its output accordingly. When it is being tested, the system remains on its best behavior, ignoring off-limits factors like race or gender. At other times, it reverts to its inherently biased approach. Sophie Hilgard, one of the authors on that study, likens the use of such a scheme, which is so far just a theoretical concern, to what Volkswagen actually did to detect when a car was undergoing emissions tests, temporarily adjusting the engine parameters to make the exhaust cleaner than it would normally be.
Another way of explaining a judgment is to output a simple decision tree: a list of if-then rules. The tree doesn't summarize the whole algorithm, though; instead it includes only the factors used to make the one decision in question. In 2019, Erwan Le Merrer and Gilles Trédan at the French National Center for Scientific Research described a method that constructs these trees in a deceptive way, so that they could explain a credit rating in seemingly objective terms, while hiding the system's reliance on the applicant's gender, age, and immigration status.
Whether any of these deceptions have or ever will be deployed is an open question. Perhaps some degree of deception is already common, as in the case for the algorithms that explain how advertisements are targeted. Schneider of the University of Liechtenstein says that the deceptions in place now might not be so flagrant, “just a little bit misguiding." What's more, he points out, current laws requiring explanations aren't hard to satisfy. “If you need to provide an explanation, no one tells you what it should look like."
Despite the possibility of trickery in XAI, Duke's Rudin takes a hard line on what to do about the potential problem: She argues that we shouldn't depend on any decision-making system that requires an explanation. Instead of explainable AI, she advocates for interpretable AI—algorithms that are inherently transparent. “People really like their black boxes," she says. “For every data set I've ever seen, you could get an interpretable [system] that was as accurate as the black box." Explanations, meanwhile, she says, can induce more trust than is warranted: “You're saying, 'Oh, I can use this black box because I can explain it. Therefore, it's okay. It's safe to use.' "
What about the notion that transparency makes these systems easier to game? Rudin doesn't buy it. If you can game them, they're just poor systems, she asserts. With product ratings, for example, you want transparency. When ratings algorithms are left opaque, because of their complexity or a need for secrecy, everyone suffers: “Manufacturers try to design a good car, but they don't know what good quality means," she says. And the ability to keep intellectual property private isn't required for AI to advance, at least for high-stakes applications, she adds. A few companies might lose interest if forced to be transparent with their algorithms, but there'd be no shortage of others to fill the void.
Lipton, of Carnegie Mellon, disagrees with Rudin. He says that deep neural networks—the blackest of black boxes—are still required for optimal performance on many tasks, especially those used for image and voice recognition. So the need for XAI is here to stay. But he says that the possibility of deceptive XAI points to a larger problem: Explanations can be misleading even when they are not manipulated.
Ultimately, human beings have to evaluate the tools they use. If an algorithm highlights factors that we would ourselves consider during decision-making, we might judge its criteria to be acceptable, even if we didn't gain additional insight and even if the explanation doesn't tell the whole story. There's no single theoretical or practical way to measure the quality of an explanation. “That sort of conceptual murkiness provides a real opportunity to mislead," Lipton says, even if we humans are just misleading ourselves.
In some cases, any attempt at interpretation may be futile. The hope that we'll understand what some complex AI system is doing reflects anthropomorphism, Lipton argues, whereas these systems should really be considered alien intelligences—or at least abstruse mathematical functions—whose inner workings are inherently beyond our grasp. Ask how a system thinks, and “there are only wrong answers," he says.
And yet explanations are valuable for debugging and enforcing fairness, even if they're incomplete or misleading. To borrow an aphorism sometimes used to describe statistical models: All explanations are wrong—including simple ones explaining how AI black boxes work—but some are useful.
This article appears in the February 2021 print issue as “Lyin' AIs."


