
Training the large neural networks behind many modern AI tools requires real computational might: For example, OpenAI’s most advanced language model, GPT-3, required an astounding million billion billions of operations to train, and cost about US $5 million in compute time. Engineers think they have figured out a way to ease the burden by using a different way of representing numbers.
Back in 2017, John Gustafson, then jointly appointed at A*STAR Computational Resources Centre and the National University of Singapore, and Isaac Yonemoto, then at Interplanetary Robot and Electric Brain Co., developed a new way of representing numbers. These numbers, called posits, were proposed as an improvement over the standard floating-point arithmetic processors used today.
Now, a team of researchers at the Complutense University of Madrid have developed the first processor core implementing the posit standard in hardware and showed that, bit-for-bit, the accuracy of a basic computational task increased by up to four orders of magnitude, compared to computing using standard floating-point numbers. They presented their results at last week’s IEEE Symposium on Computer Arithmetic.
“Nowadays it seems that Moore’s law is starting to fade,” says David Mallasén Quintana, a graduate researcher in the ArTeCS group at Complutense. “So, we need to find some other ways of getting more performance out of the same machines. One of the ways of doing that is changing how we encode the real numbers, how we represent them.”
The Complutense team isn’t alone in pushing the envelope with number representation. Just last week, Nvidia, Arm, and Intel agreed on a specification for using 8-bit floating-point numbers instead of the usual 32-bit or 16-bit for machine-learning applications. Using the smaller, less-precise format improves efficiency and memory usage, at the cost of computational accuracy.
Real numbers can’t be perfectly represented in hardware simply because there are infinitely many of them. To fit into a designated number of bits, many real numbers have to be rounded. The advantage of posits comes from the way the numbers they represent exactly are distributed along the number line. In the middle of the number line, around 1 and -1, there are more posit representations than floating point. And at the wings, going out to large negative and positive numbers, posit accuracy falls off more gracefully than floating point.
“It’s a better match for the natural distribution of numbers in a calculation,” says Gustafson. “It’s the right dynamic range, and it’s the right accuracy where you need more accuracy. There’s an awful lot of bit patterns in floating-point arithmetic no one ever uses. And that’s waste.”
Posits accomplish this improved accuracy around 1 and -1 thanks to an extra component in their representation. Floats are made up of three parts: a sign bit (0 for positive, 1 for negative), several “mantissa” (fraction) bits denoting what comes after the binary version of a decimal point, and the remaining bits defining the exponent (2 exp).
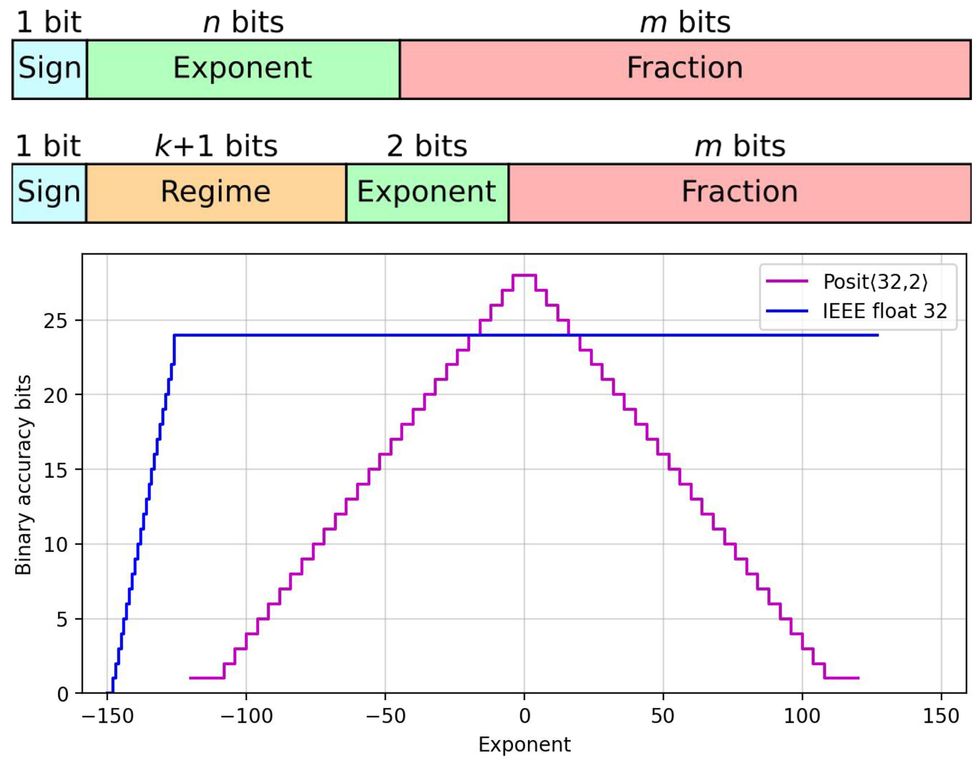 This graph shows components of floating-point-number representation [top] and posit representation [middle]. The accuracy comparison shows posits’ advantage when the exponent is close to 0. Complutense University of Madrid/IEEE
This graph shows components of floating-point-number representation [top] and posit representation [middle]. The accuracy comparison shows posits’ advantage when the exponent is close to 0. Complutense University of Madrid/IEEE
Posits keep all the components of a float but add an extra “regime” section, an exponent of an exponent. The beauty of the regime is that it can vary in bit length. For small numbers, it can take as few as two bits, leaving more precision for the mantissa. This allows for the higher accuracy of posits in their sweet spot around 1 and -1.
Deep neural networks usually work with normalized parameters called weights, making them the perfect candidate to benefit from posits’ strengths. Much of neural-net computation is comprised of multiply-accumulate operations. Every time such a computation is performed, each sum has to be truncated anew, leading to accuracy loss. With posits, a special register called a quire can efficiently do the accumulation step to reduce the accuracy loss. But today’s hardware implements floats, and so far, computational gains from using posits in software have been largely overshadowed by losses from converting between the formats.
With their new hardware implementation, which was synthesized in a field-programmable gate array (FPGA), the Complutense team was able to compare computations done using 32-bit floats and 32-bit posits side by side. They assessed their accuracy by comparing them to results using the much more accurate but computationally costly 64-bit floating-point format. Posits showed an astounding four-order-of-magnitude improvement in the accuracy of matrix multiplication, a series of multiply-accumulates inherent in neural network training. They also found that the improved accuracy didn’t come at the cost of computation time, only a somewhat increased chip area and power consumption.
Although the numerical accuracy gains are undeniable, how exactly this would impact the training of large AIs like GPT-3 remains to be seen.
“It’s possible that posits will speed up training because you’re not losing as much information on the way,” says Mallasén “But these are things that that we don’t know. Some people have tried it out in software, but we also want to try that in hardware now that we have it.”
Other teams are working on their own hardware implementations to advance posit usage. “It’s doing exactly what I hoped it would do; it’s getting adopted like crazy,” Gustafson says. “The posit number format caught fire, and there are dozens of groups, both companies and universities, that are using it.”
This article appears in the December 2022 print issue as “A New Type of Number Improves the Math of AI.”
- Top Programming Languages 2022 - IEEE Spectrum ›
- The Future of Cybersecurity Is the Quantum Random Number ... ›
- Machine Learning’s New Math - IEEE Spectrum ›


