
One of the things that makes humans so great at adapting to the world around us is our ability to understand entire categories of things all at once, and then use that general understanding to make sense of specific things that we’ve never seen before. For example, consider something like a lamp. We’ve all seen some lamps. Nobody has seen every single lamp there is. But in most cases, we can walk into someone’s house for the first time and easily identify all their lamps and how they work. Every once in a while, of course, there will be something incredibly weird that’ll cause you to have to ask, “Uh, is that a lamp? How do I turn it on?” But most of the time, our generalized mental model of lamps keeps us out of trouble.
It’s helpful that lamps, along with other categories of objects, have (by definition) lots of pieces in common with each other. Lamps usually have bulbs in them. They often have shades. There’s probably also a base to keep it from falling over, a body to get it off the ground, and a power cord. If you see something with all of those characteristics, it’s probably a lamp, and once you know that, you can make educated guesses about how to usefully interact with it.
This level of understanding is something that robots tend to be particularly bad at, which is a real shame because of how useful it is. You might even argue that robots will have to understand objects on a level close to this if we’re ever going to trust them to operate autonomously in unstructured environments. At the 2019 Conference on Computer Vision and Pattern Recognition (CVPR) this week, a group of researchers from Stanford, UCSD, SFU, and Intel are announcing PartNet, a huge database of common 3D objects that are broken down and annotated at the level required to, they hope, teach a robot exactly what a lamp is.

PartNet is a subset of ShapeNet, an even huger 3D database of over 50,000 common objects. PartNet has 26,671 objects in its database across 24 categories (like doors, tables, chairs, lamps, microwaves, and clocks), and each one of those objects has been broken down into labeled component parts. Here’s what that looks like for two totally different looking lamps:
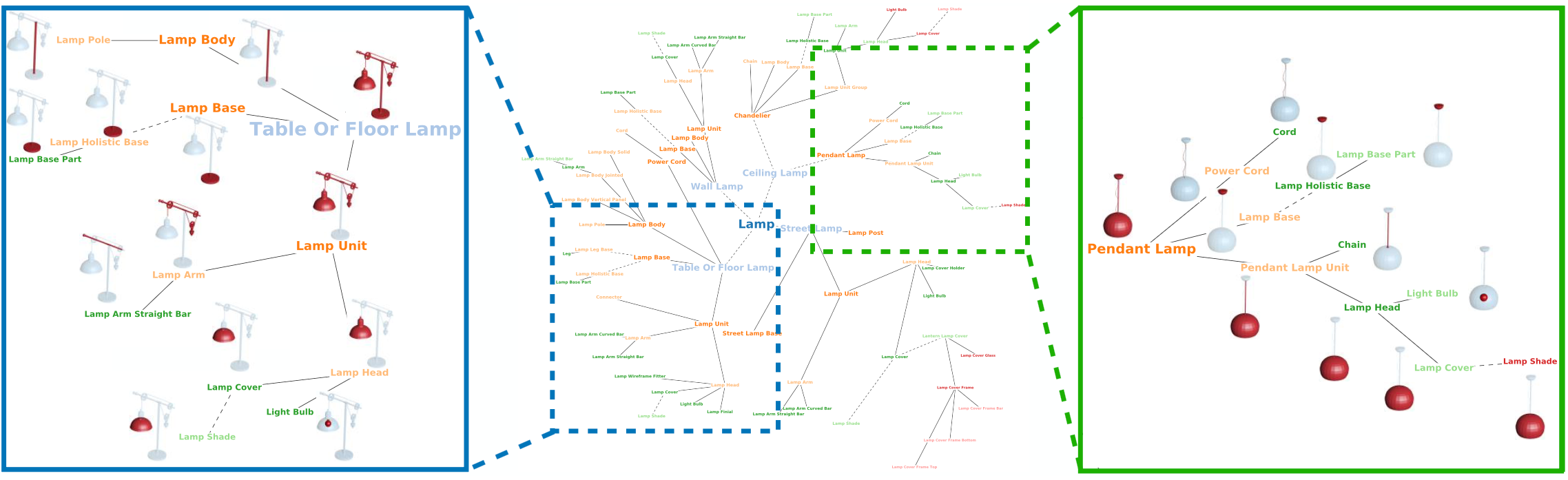
All that semantically labeled detail is what makes PartNet special. Databases like ShapeNet basically just say “here are a bunch of things that are lamps,” which has limited usefulness. PartNet, by contrast, is a way to much more fundamentally understand lamps: What parts they’re made of, where controls tend to be, and so on. Beyond just helping with a much more generalized identification of previously unseen lamps, it also makes it possible for an autonomous system (with the proper training) to make inferences about how to interact with those unseen lamps in productive ways.
As you might expect, creating PartNet was a stupendous amount of work. Nearly 70 “professional annotators” spent an average of 8 minutes annotating each and every one of those 26,671 3D shapes with a total of 573,585 parts, and then each annotation was verified at least once by another annotator. To keep things consistent, templates were created for each class of object, with the goal of minimizing the set of parts in a way that still comprehensively covered everything necessary to describe the entire object class. The parts are organized hierarchically, too, with small parts a subset of larger ones. Here’s how it all breaks down:
In order for this to be useful outside of PartNet itself, robots will have to be able to do the 3D segmentation step on their own, taking 3D models of objects (that the robot creates) and then breaking them down into pieces that can be identified and correlated with the existing object models. This is a tricky thing to do for a bunch of reasons: For example, you need to be able to identify individual parts from point clouds that may be small but also important (like drawer pulls and door knobs), and many parts that look visually similar may be semantically quite different.
The researchers have made some progress on this, but it’s still an area that needs more work. And that’s what PartNet is for, too—providing a dataset that can be used to develop better algorithms. At some point, PartNet may be part of a foundation for systems that can even annotate similar 3D models completely on their own, in the same way that we’ve seen autonomous driving datasets transition from human annotation to automatic annotation with human supervision. Bringing that level of semantic understanding to unfamiliar and unstructured environments will be key to those real-world adaptable robots that always seem to be right around the corner.
“PartNet: A Large-scale Benchmark for Fine-grained and Hierarchical Part-level 3D Object Understanding,” by Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Subarna Tripathi, Leonidas J. Guibas, and Hao Su from Stanford University, University of California San Diego, Simon Fraser University, and Intel AI Lab, was presented at the 2019 Conference on Computer Vision and Pattern Recognition.
[ PartNet ]