The Conversation (0)

Analysis of Leonardo da Vinci's Salvator Mundi required dividing a high-resolution image of the complete painting
into a set of overlapping square tiles. But only those tiles that contained sufficient visual information, such as the ones
outlined here, were input to the author's neural-network classifier.
PHOTO OF SALVATOR MUNDI: CORBIS/GETTY IMAGES
The sound must have been deafening—all those champagne corks popping atChristie's, the British auction house, on 15 November 2017. A portrait of Jesus, known asSalvator Mundi (Latin for "savior of the world"), had just sold at Christie's in New York for US $450.3 million, making it by far the most expensive painting ever to change hands.
But even as the gavel fell, a persistent chorus of doubters voiced skepticism. Was it really painted by Leonardo da Vinci, the towering Renaissance master, as a panel of experts had determined six years earlier? A little over 50 years before that, a Louisiana man had purchased the painting in London for a mere £45. And prior to the rediscovery of Salvator Mundi, no Leonardo painting had been uncovered since 1909.
Some of the doubting experts questioned the work's provenance—the historical record of sales and transfers—and noted that the heavily damaged painting had undergone extensive restoration. Others saw the hand of one of Leonardo's many protégés rather than the work of the master himself.
Is it possible to establish the authenticity of a work of art amid conflicting expert opinions and incomplete evidence? Scientific measurements can establish a painting's age and reveal subsurface detail, but they can't directly identify its creator. That requires subtle judgments of style and technique, which, it might seem, only art experts could provide. In fact, this task is well suited to computer analysis, particularly by neural networks—computer algorithms that excel at examining patterns. Convolutional neural networks (CNNs), designed to analyze images, have been used to good advantage in a wide range of applications, including recognizing faces and helping to pilot self-driving cars. Why not also use them to authenticate art?


 The author applied his neural network to this painting by Rembrandt [top], one formerly attributed to him [middle], and Leonardo's Salvator Mundi [bottom]. Hot colors show areas that the classifier determined with high probability to have been painted by the artist associated with the work.PROBABILITY MAPS: STEVEN AND ANDREA FRANK
The author applied his neural network to this painting by Rembrandt [top], one formerly attributed to him [middle], and Leonardo's Salvator Mundi [bottom]. Hot colors show areas that the classifier determined with high probability to have been painted by the artist associated with the work.PROBABILITY MAPS: STEVEN AND ANDREA FRANK
That's what I asked my wife, Andrea M. Frank, a professional curator of art images, in 2018. Although I have spent most of my career working as an intellectual-property attorney, my addiction to online education had recently culminated in a graduate certificate in artificial intelligence from Columbia University. Andrea was contemplating retirement. So together we took on this new challenge.
We started by reviewing the obstacles to analyzing paintings with neural networks and immediately recognized the biggest ones. The first is sheer size: A high-resolution image of a painting is much too large for a conventional CNN to handle. But smaller images, appropriately sized for CNNs, may lack the information to support the needed discriminations. The other obstacle is numbers. Neural networks require thousands of training samples, far more than the number of paintings that even the most prolific artist could produce in a lifetime. It's not surprising that computers had contributed little to resolving disputes over the authenticity of paintings.
The size problem is not unique to art images. Digitized biopsy slides, which pathologists scrutinize to diagnose cancer and other conditions, also contain vast numbers of pixels. Medical researchers have made these images tractable for CNNs by breaking them up into much smaller fragments—square tiles, for example. Doing so can also help with the numbers problem: You can generate a great many training tiles from a single image, especially if you allow them to overlap vertically and horizontally. Much of the information in each tile will then be redundant, of course, but it turns out this is less important than having lots of tiles. Often when training a neural network, quantity is quality.
If this approach could work for art, we thought, the next problem would be determining which tiles to use. Salvator Mundi has regions rich in pictorial information and also background areas that are of little visual interest. For training purposes, those low-information regions would seem to have scant relevance—or worse: If they lack the author's signature characteristics because Leonardo spent little time on them, or if many artists tend to render simple background regions indistinguishably, training based on these regions could mislead the CNN. Its ability to draw meaningful distinctions would then suffer.
We needed some sort of criterion to help us identify visually salient tiles, ones that a computer could apply automatically and consistently. I thought information theory might offer a solution or at least point the way. Andrea's eyes began to glaze over as I broached the math. But Claude Shannon, who pioneered the field, was a unicycle-riding maker of flame-throwing trumpets and rocket-powered Frisbees. How bad could it be?
One bulwark of information theory is the notion of entropy. When most people think of entropy, if they think about it at all, they picture things flying apart into disorder. Shannon, though, thought of it in terms of how efficiently you can send information across a wire. The more redundancy a message contains, the easier it is to compress, and the less bandwidth you need to send it. Messages that can be highly compressed have low entropy. High-entropy messages, on the other hand, can't be compressed as much because they possess more uniqueness, more unpredictability, more disorder.
Claude Shannon, who pioneered information theory, was a unicycle-riding maker of flame-throwing trumpets and rocket-powered Frisbees.
Images, like messages, carry information, and their entropies similarly indicate their level of complexity. A fully white (or fully black) image has zero entropy—it is entirely redundant to record some huge number of 1s or 0s when you could equally well just say, "all black" or "all white." Although a checkerboard appears busier visually than a single diagonal bar, it isn't really much more complex in the sense of predictability, meaning that it has only a little more entropy. A still-life painting, though, has vastly more entropy than either.
But it would be a mistake to think of entropy as indicating the amount of information in an image—even very small images can have high entropies. Rather, entropy reflects the diversity of the pictorial information. It occurred to me, as the half of the team who is not allergic to math, that we might exclude tiles with low entropies in our efforts to eliminate background and other visually monotonic regions.
We began our adventure with portraits by the Dutch master Rembrandt (Rembrandt Harmenszoon van Rijn), whose work has been the subject of centuries-long attribution controversies. Training a CNN to identify true Rembrandts would clearly require a data set that includes some paintings by Rembrandt and some by others. But assembling that data set presented a conundrum.
Were we to choose 50 Rembrandt portraits and 50 portraits by other artists selected at random, we could train a system to distinguish Rembrandt from, say, Pablo Picasso but not from Rembrandt's students and admirers (much less forgers). But if all the non-Rembrandt images in our training set looked too much like Rembrandts, the CNN would overfit. That is, it wouldn't generalize well beyond its training. So Andrea set to work compiling a data set with non-Rembrandt entries ranging from some that were very close to Rembrandt's work to ones that were evocative of Rembrandt but readily distinguishable from the real thing.
We then had some additional choices to make. If we were going to slice up Rembrandt paintings into tiles and keep only those with sufficiently high entropies, what should our entropy cutoff be? I suspected that a tile should have at least as much entropy as the entire image for it to contribute reliably to classification. This hunch, which proved correct in practice, ties the entropy threshold to the character of the painting, which obviously will vary from one work to another. And it's a high bar—usually fewer than 15 percent of the tiles qualify. But if that resulted in too few, we could increase the overlap between adjacent tiles to achieve a sufficient tile population for training purposes.
Low-probability regions do not definitively signal the work of another hand. They could result from a bold, out-of-character experiment by the artist—or even just a bad day.
The results of this entropy-based selection make sense intuitively—indeed, the tiles that pass muster are the ones you'd probably pick yourself. Typically, they capture features that experts rely on when judging a painting's authorship. In the case of Salvator Mundi, the selected tiles cover Jesus's face, side curls, and blessing hand—the very same attributes contested most fiercely by scholars debating the painting's authorship.
The next consideration was tile size. Commonly used CNNs running on standard hardware can comfortably handle image dimensions ranging from 100 × 100 pixels to 600 × 600 pixels. We realized that using small tiles would confine analysis to fine detail while using larger tiles would risk overfitting the CNN to the training data. But only through training and testing could we determine the optimal tile size for a particular artist. For Rembrandt portraits, our system worked best using tiles of 450 × 450 pixels—about the size of the subject's face—with all painting images scaled to the same resolution.
We also found that simple CNN designs work better than more complex (and more common) ones. So we settled on using a CNN with just five layers. Andrea's well-chosen data set consisted of 76 images of Rembrandt and non-Rembrandt paintings, which we shuffled four different ways into separate sets of 51 training and 25 test images. This allowed us to "cross-validate" our results to ensure consistency across the data set. Our five-layer CNN learned to distinguish Rembrandt from his students, imitators, and other portraitists with an accuracy of more than 90 percent.
Encouraged by thissuccess, we whimsically dubbed our doughty little CNN "The A-Eye" and put it to work on landscapes painted by another Dutch genius,Vincent van Gogh. We chose van Gogh because his work is so different from Rembrandt's—emotional rather than studied, his strokes daring and expressive. This time our data set consisted of 152 van Gogh and non–van Gogh paintings, which we divided four different ways into sets of 100 training and 52 test images.
The A-Eye acquitted itself well on van Gogh's work, once again achieving high accuracy on our test sets, but only with much smaller tiles. The best performers were just 100 x 100 pixels, about the size of a brushstroke. It seems that the "signature" scale of an artist's work—the distinctive feature size that facilitates accurate CNN-based classification—is particular to that artist, at least within a genre such as portraits or landscapes.
From Paintings to Pathology
Lessons learned from analyzing artwork also apply in the medical realm
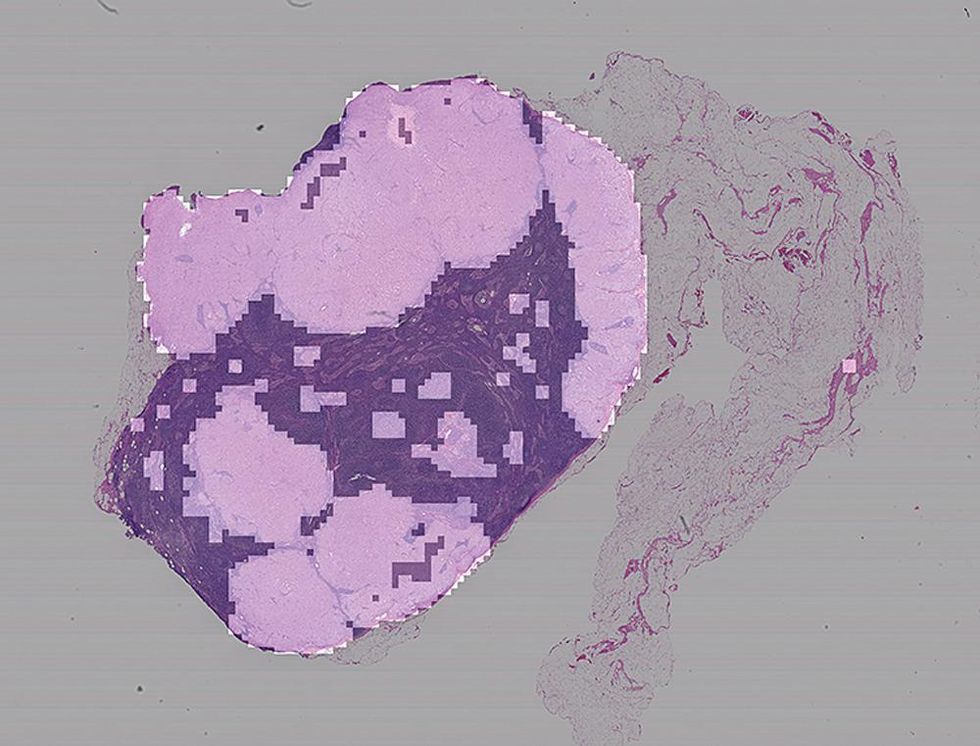 Pink indicates what the neural network determined is likely diseased tissue on this microscope slide.STEVEN FRANK
Pink indicates what the neural network determined is likely diseased tissue on this microscope slide.STEVEN FRANK
The challenges of using convolutional neural networks (CNNs) to analyze artwork also plague efforts to automate analysis of medical images—particularly the enormous whole-slide images (WSIs) of histology samples that pathologists analyze for signs of cancer and other diseases. These images, which may be billions of pixels in size, are commonly viewed on powerful workstations that may be integrated directly with the slide scanner. Current efforts to bring artificial intelligence to bear also start with full-size images and require even more specialized hardware, such as a powerful graphics-processing unit, to handle the analysis. These efforts may also suffer from the "black box" problem: If the computer merely classifies the biopsy slide, can the pathologist be confident it was looking in the right places?
Relative to a huge WSI, even the largest tiles suited to CNN analysis are tiny. How can the pathologist be sure they capture the anatomy critical to a diagnosis? Tumor cells can adeptly disguise themselves, and clues to disease progression may lurk outside them in the form of changes in the makeup of surrounding tissue or unusual patterns of nearby immune cells. Predictive features are not always predictable.
Image entropy and a different mindset can help. Image scaling and tile size can serve as "knobs" to be turned until peak classification accuracy is reached. Training and testing over a range of image and tile sizes, as we have done for paintings, can allow a CNN to distinguish between diseased and normal tissue and even among various forms of a disease. While we have used image entropy to determine the most predictive tiles to use to train our neural network, in the medical realm tiles identified in this way may collectively provide a pretty good approximation of, say, a tumor region even before the CNN has done any work. – S.J.F.Exactly how a CNN finds the key details—what it "sees" when it makes a prediction—is not readily ascertained. The business end of a CNN (actually its midsection) is a sequence of convolutional layers that progressively digest an image into details that somehow, unfathomably, produce a classification. The black-box nature of our tool is a well-known challenge with artificial neural networks, particularly those that analyze images. What we do know is that, when properly trained on tiles of the right size, the CNN reliably estimates the probability that the canvas region corresponding to each tile was painted by the subject artist. And we can classify the painting as a whole based on the probabilities determined for the various individual tiles that span it—most simply, by finding their overall average.
To take a closer look at predictions across an image, we can assign the probability associated with a tile to each of the pixels it contains. Usually more than one tile intercepts a pixel, so we can average the relevant tile-level probabilities to determine the value to give that pixel. The result is a probability map showing regions more or less likely to have been painted by the artist in question.
The distribution of probabilities across a canvas can be instructive, particularly for artists known (or suspected) to have worked with assistants or for those whose paintings were damaged and later restored. Rembrandt's portrait of his wife Saskia van Uylenburgh, for example, has areas of doubt in our probability map, particularly in the face and background. This accords with the view of Rembrandt scholars that these regions were later overpainted by someone other than Rembrandt.
Suggestive as such findings are, low-probability regions do not definitively signal the work of another hand. They could result from a bold, out-of-character experiment by the artist—or even just a bad day. Or maybe some of these regions arise from simple classification errors. After all, no system is perfect.
We put our system to the test by evaluating 10 works by Rembrandt and van Gogh that have been the subject of heated attribution debate among experts. In all but one case, our classifications matched the current scholarly consensus. Thus emboldened, we felt ready for the much bigger challenge of evaluating the Salvator Mundi—I say bigger because the number of paintings firmly attributed to Leonardo is so small (fewer than 20).
Ultimately, we were able to obtain plausible tile-level classifications and produce a telling probability map. Our results cast doubt on Leonardo's authorship of the background and blessing hand of Salvator Mundi. That accords with the painting's extensive restoration, which involved complete repainting of the background. And as noted, experts disagree sharply over who painted the blessing hand.

Having established a degree of credibility for our approach, we nurse one extravagant ambition. This involves the sole case where our system departs from today's attribution consensus, a painting called The Man With the Golden Helmet. Long beloved as a particularly striking Rembrandt, it was de-attributed by its owner, the Staatliche Museum in Berlin, in 1985. The museum's scholars cited inconsistencies in paint handling, concluding they did not conform to Rembrandt's known way of working.
Now regarded as the work of an unknown "Circle of Rembrandt" painter, its luster has faded considerably in the public mind, if not on the somber soldier's spectacular helmet. But our neural network strongly classifies the painting as a Rembrandt (perhaps with a small area of rework or assistance). Moreover, our overall findings caution against basing Rembrandt attributions on fine surface features, because narrowing our CNN's analysis to such features makes its predictions no better than a guess. We hope that, one day, the old warrior's demotion will be reconsidered.
Image entropy is a versatile helper. It can identify the parts of a complex image that best stand for the whole, making even the largest images—including medical images [see "From Paintings to Pathology," above]—amenable to computer analysis and classification. With training simplified and the need for large data sets reduced, small CNNs can now punch above their weight.
This article appears in the September 2021 print issue as "State of the Art."
Portrait of the Portrait Sleuths
 STEVEN AND ANDREA FRANK
STEVEN AND ANDREA FRANK
In 2011, Marc Andreessen famously wrote that software is eating the world. Nowadays, the globe is being devoured by a particular kind of software: deep learning, which allows machines to tackle tasks that a short time ago would have seemed inconceivable for a computer to handle, including driving cars and making medical diagnoses. Prepare to add another surprising feat to this list—identifying forged paintings.
That a computer can help experts authenticate artwork is the result of efforts by a husband-and-wife team, Steven and Andrea Frank, who developed a convolutional neural network that can assess the probability that a painting, or even parts of a painting, were painted by the supposed creator. They recently applied this neural network to assess the authenticity of Leonardo da Vinci's Salvator Mundi, which was auctioned at Christie's in 2017 for US $450 million, making it the most expensive painting ever sold.
That Steven took on the challenge to create a neural network that could authenticate artwork is especially surprising given that he is not a computer scientist—he's an attorney. But in 2012, after completing EdX's Introduction to Electronics, he found he couldn't stop taking such online courses. "It turned into kind of an addiction," says Steven, who through e-learning later earned a graduate certificate in artificial intelligence from Columbia University.
Armed with a good understanding of neural networks, Steven, an IEEE member, sought to apply this knowledge to a real-world problem. Andrea, an art historian who has spent most of her career curating art imagery, was contemplating retirement and had some time on her hands. So they waded in. It's hard to imagine a better team to tackle this particular challenge.
From Your Site Articles
- Amateurs' Al Tells Real Rembrandts From Fakes - IEEE Spectrum ›
- Stop Calling Everything AI, Machine-Learning Pioneer Says - IEEE ... ›
Related Articles Around the Web


