The Conversation (0)

This is part of IEEE Spectrum's special report: Always On: Living in a Networked World.
If you greeted the latest announcements of 1-GHz-plus PC processors from Intel Corp. and Advanced Micro Devices Inc. with a smothered yawn and are wondering where the action is, take a look at what could be the hottest area in processors today--networking and communications. With data traffic more than doubling every year for the past five years, new approaches to handling all those bits are sorely needed and chip developers are not about to disappoint.
Fiber availability is not a problem. More than enough is around to transport the bits. The crunch comes at the router and switches that must, at the least, determine the packets' next destinations, find their Internet-protocol (IP) addresses in huge lookup tables, and send them on as quickly as they arrived.
So to handle the increased traffic, network data rates are speeding up. From typical rates of only 155 Mb/s (Sonet standard OC-3) a few years ago, the fastest so-called wire speeds today are 10 Gb/s (OC-192), and many networks will move to 40 Gb/s (OC-768) within two or three years.
At the slower data rates of a few years ago, there was not much need for dedicated network processors: general-purpose processors were well able to keep up with the data flow. "But," recalled Mario Nemirovsky, founder and chief technical officer of XStream Logic Inc., "when the rates had increased [to the point that these microprocessors couldn't handle the job], designers switched to ASICs [application-specific ICs]." His company, which is located in Los Gatos, Calif., is developing a network processor for 10-Gb/s data rates.
With data traffic more than doubling every year, new approaches to handling all those bits are needed
ASICs are hard-wired to perform specific tasks superbly, but they have two shortcomings. First, designing and manufacturing a complex ASIC can take up to two years--too long for the manufacturers of routers and switches to wait for a new feature to be added to their systems. Second, they are not programmable; so once designed, they cannot be modified without another design and manufacturing cycle.
Built to process data packets
Enter network processors. In contrast to general-purpose devices, which are designed to run a wide variety of programs, network processors are optimized to process data packets and send them on to the next node at wire speed--dispatching them at the same rate as they arrive. Also, if a new feature is needed, or a new standard is developed, the processors can be reprogrammed to perform the tasks involved. In fact, they all are versatile enough to address a wide range of networking applications.
The computational power required to do the job depends not only on the data rate, but also on what the processor must do to the data. The simplest tasks involve determining where to send the packet, based on information in the packet header. This is generally referred to as processing at the layer 2-4 levels. The level designations relate to the seven-layer open systems interconnection (OSI) model developed (but never adopted) as a framework for protocol standards by the International Organization for Standardization (ISO), in Geneva.
More complex operations, like usage-based accounting or load balancing, need the processor to know what is contained in the packet payload. This type of operation is done in levels 5-7 of the OSI model, which manage and manipulate data and interact with application programs. For example, usage-based accounting collects information about user sessions for billing or network-analysis. In this capacity, the processor monitors the login session to identify the user, extracts login information, matches file names to users and to program policy tables, and detects keywords in the payload, among other functions.
Network processors are just beginning to show up in the marketplace. Only a few were shipped last year, according to Linley Gwennap, an independent consultant (and former publisher and editorial director of Microprocessor Report, published in Sunnyvale, Calif.). He told attendees of the Network Processors seminar given at the 2000 Microprocessor Forum, held in October in San Jose, Calif., that Intel's IXP1200 and MMC's nP7120 for 1-Gb/s Ethernet were in full production.
Vitesse's IQ2000, for 1-Gb/s Ethernet, and IBM's PowerNP NP4GS3 and Agere System's Payload Plus--both OC-48 or 2.5-Gb/s processors--also went into production in the fourth quarter of 2000.
Aiming for the stratosphere
Among designs currently under development are three that are aiming to process all seven protocol layers at 10-Gb/s data rates. They are XStream Logic's dynamic multistreaming (DMS) processor core, the NP-1 from EZchip Technologies Ltd., in Migdal Haemek, Israel, and NetVortex from Lexra Inc., San Jose, Calif.
Lexra will not manufacture or sell chips based on NetVortex. Instead it will license its architecture as intellectual property (IP) to be incorporated by customers into larger networking systems on chip. This arrangement gives customers the flexibility to design their systems to meet specific price and performance goals and to add proprietary circuitry to the chip.
The foundation of the NetVortex architecture is Lexra's LX8000 packet-processing core--a 32-bit MIPS 3000 reduced-instruction-set computing (RISC) processor. Up to 16 cores can be hooked up on a high-speed bus to run as a multiprocessor. In this configuration, a prototype system has processed seven networking protocol layers at 10-Gb/s data rates, and one customer is working on an OC-768 (40-Gb/s) system, according to Jonah McLeod Jr., Lexra's corporate marketing director.
Your clocks are numbered
Seven-layer processing at a wire speed of 10 Gb/s is no easy task, according to Eli Fruchter, president and CEO of EZchip. At 10 Gb/s, a 64-B packet arrives about every 60 ns (allowing a few nanoseconds for overhead). So for a processor running at 200 MHz, a packet arrives every 12th clock period--"and that's not a lot of clocks," he emphasized.
In devising an architecture able to keep up with a 10-Gb/s data rate, EZchip engineers identified the four main tasks that a network processor must perform and then custom-designed four processor cores, each one optimized for one of the tasks. They arranged the four cores in a four-stage superpipeline, meaning that each stage has many copies of the appropriate core. The NP-1 has 64 cores altogether. Then they made the datapaths very wide. Instead of the 32- or 64-bit data paths typical of general-purpose processors, EZchip cores have data paths that range from 256 to 512 bits wide.
But even with the highly optimized architecture of the processor cores, an extremely narrow bottleneck remains: memory access. Processing packets at the higher OSI levels involves constantly moving data in and out of memory, both to store and retrieve packets and to search lookup tables. "We need a memory bandwidth of about 500 Gb/s in order to meet 10-Gb/s wire speed," explained Fruchter. The chips also need to have access to a rather large memory, of at least 128MB.
So EZchip engineers devised a memory architecture with both an embedded dynamic RAM of a few megabytes for high bandwidth and an off-chip double data-rate DRAM for large capacity. They also developed their own patented search techniques that reduce the number of clock periods required to retrieve data from memory by about two-thirds.
EZchip has not yet announced when it will have chips available. But IBM recently signed on as EZchip's foundry and will build NP-1's with its advanced 0.13-µm ASIC process when the chips go into full production.
The tried and true
Rather than develop entire new architectures, as EZchip has done, XStream's engineers have started out from the MIPS architecture, developed in the early 1980s at Stanford University in California. It has since become the basis for many processor designs. All the same, the many new features they have added will have to prove themselves useful in real-world applications.
The reason for using MIPS, in fact, may have less to do with any inherent advantages of the architecture and more to do with its pervasiveness. "MIPS instruction sets are used frequently in the present routers and switches and people are familiar with it. There are also a lot of available tools for MIPS, such as compilers and assemblers," explained Joe Salvador, XStream's director of product marketing.
To achieve seven-layer 10-Gb/s processing in their design, XStream architects turned to a technique they call dynamic multistreaming--also called simultaneous multithreading.
"With DMS, you can simultaneously issue instructions from multiple threads in a single cycle," explained Salvador. "For our first core, we built an 8-way multithreaded processor. Up to 8 threads can execute simultaneously. Each thread can issue up to four instructions in a clock cycle, for a total of 32 eligible instructions. From those 32, up to eight are issued." The instruction queues and execution units are arranged into two clusters of four threads and four execution units each [see figure]. Clustering simplifies the design with little impact on performance.
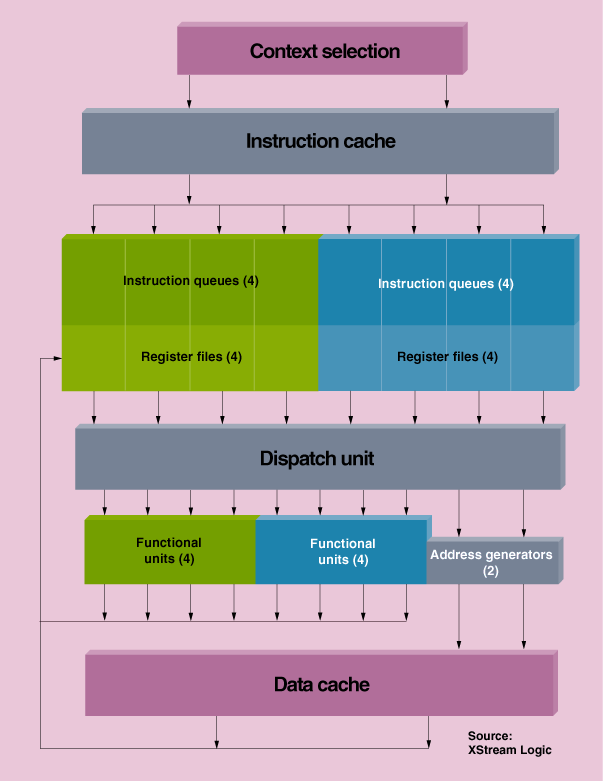
Image: Source
Dynamic Multistreaming Design Speeds Instructions per Clock: XStream Logic Inc.'s network processor core supports eight threads, or ordered sequences of instructions. Each thread has its own instruction queue and register file. The core is divided into two clusters of four threads each. Every clock cycle, each cluster can issue up to 16 instructions--four from each thread--and four of the 16 are selected and dispatched to one of the four functional units in that cluster for execution. If network traffic is slow, one active thread can supply all four functional units with instructions. In general, instructions can come from any combination of the four threads.
With the DMS approach, the processor can sustain an instruction per clock (IPC) rate of more than 6. "Traditional superscalar architectures such as the PowerPC or Pentium processors can issue multiple instructions per cycle, but their sustained IPC rate is just a little above 1, if they are lucky," said Salvador.
[Network processors] "will soon reside in every piece of networking or communications equipment"
The design also includes a packet management unit that takes care of storing packets into memory and loading the pieces of the packets that require processing back into the processor. It also handles I/O operations and it frees memory space of data that is no longer needed--a process known as garbage collection. "So the core can spend its time just doing packet processing," explained Salvador.
Get 'em while they're hot
One indicator of the interest in network processors is the number of start-ups that have been bought up by larger communications companies. Last year Vitesse Semiconductor bought Sitera, the developer of the Prisma processor, and Broadcom agreed to acquire SiByte, a leading provider of highly integrated processors for the network market. Lucent Microelectronics bought Agere (pronounced "aGEARie"), based in Austin, Tex., last spring for the latter's Payload Plus design. But Lucent Technologies is now spinning off its microelectronics business, including Payload Plus, and has (confusingly) named the new company Agere (pronounced "aGEAR") Systems.
An addition to Motorola Inc.'s communications arsenal is C-Port Corp., which developed the C-5 network processor. Motorola has incorporated the C-5 with its other communications and digital signal-processing capabilities into a platform for designing network systems. The platform also includes software and development tools from third parties. Clint Ramsey, director of strategic marketing for Motorola's Networking and Computing Systems Group, based in Austin, Texas, cites the platform's advantages:
"Network systems builders like Cisco, Ericsson, and Nortel can develop routers, switches, and other network products in a horizontal manner. They can mix and match their components. They can take a processor from Motorola, software from a third-party vendor, blend in their own magic special sauce in terms of software and features, and build a product from various sources, rather than have to develop the product completely internally."
Where will network processors be found? Certainly in routers, switches, servers, and gateways. Claimed EZchip's Fruchter, "I believe they will soon reside in every piece of networking or communications equipment."
To Probe Further
Anyone with a serious need for the latest information on all announced network processors will find it in "A Guide to Network Processors," by Linley Gwennap and Bob Wheeler, published by Cahners Microdesign Resources, Sunnyvale Calif. For excerpts and a complete table of contents, see https://www.linleygroup.com/npu.
From Your Site Articles


