
Human languages have much in common with proteins, at least in terms of computational modeling. This has led research teams to apply novel methods from natural-language processing (NLP) to protein design. One of these—Birte Höcker’s protein design lab at Bayreuth University, in Germany—describes ProtGPT2, a language model based on OpenAI’s GPT-2, to generate novel protein sequences based on the principles of natural ones.
Just as letters from the alphabet form words and sentences, naturally occurring amino acids combine in different ways to form proteins. And protein sequences, just like natural languages, store structure and function in their amino-acid sequence with extreme efficiency.
ProtGPT2 is a deep, unsupervised model that takes advantage of advances in transformer architecture that have also caused rapid progress in NLP technologies. The architecture has two modules, explains Noelia Ferruz, a coauthor of the paper and the person who trained ProtGPT2: one module to understand input text, and another that processes or generates new text. It was the second one, the decoder module that generates new text, that went into the development of ProtGPT2.
Researchers have used GPT-2 to train a model to learn the protein “language,” generate stable proteins, and explore “dark” regions of protein space.
“At the time we created this model, there were many others that were using the first module,” she says, such as ESM, ProtTrans, and ProteinBERT. “Ours was the first one publicly released at a time that was a decoder.” It was also the first time someone had directly applied GPT-2, she adds.
Ferruz herself is a big fan of GPT-2. “I find it very impressive that there was a model capable of writing English,” she says. This is a well-known transformer model that was pretrained on 40 gigabytes of Internet text in English in an unsupervised manner—that is, it used raw text with no human labeling—to generate the next word in sentences. The GPT-x series has been shown to efficiently produce long, coherent text, often indistinguishable from something written by a human—to the extent that potential misuse is a concern.
Given the capabilities of GPT-2, the Bayreuth researchers were optimistic about using it to train a model to learn the protein language, generate stable proteins, and also explore “dark” regions of the protein space. Ferruz trained ProtGPT2 on a data set of about 50 million nonannotated sequences across the whole protein space. To evaluate the model, the researchers compared a data set of 10,000 sequences generated by ProtGPT2 with a random set of 10,000 sequences from the training data set.
“We could add labels, and potentially in the future start generating sequences with a specific function.”
—Noelia Ferruz, University of Bayreuth, Germany
They found the sequences predicted by the model to be similar in secondary structure to naturally occurring proteins. ProtGPT2 can predict proteins that are stable and functional, although, Ferruz says, this will be verified by laboratory experiments on a set of 30 or so proteins in the coming months. ProtGPT2 also models proteins that do not occur in nature, opening up possibilities in the protein design space.
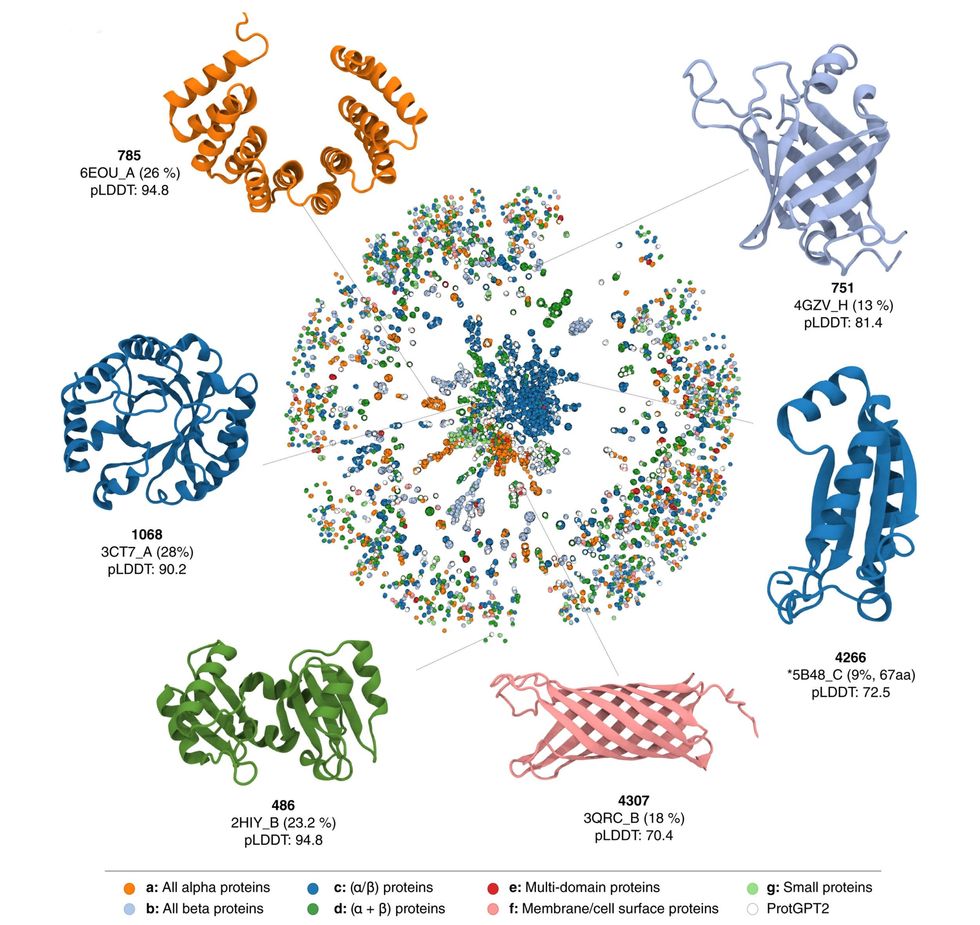 Each node represents a sequence. Two nodes are linked when they have an alignment of at least 20 amino acids and 70 percent HHsearch probability. Colors depict the different SCOPe classes, and ProtGPT2 sequences are shown in white.University of Bayreuth/Nature Communications
Each node represents a sequence. Two nodes are linked when they have an alignment of at least 20 amino acids and 70 percent HHsearch probability. Colors depict the different SCOPe classes, and ProtGPT2 sequences are shown in white.University of Bayreuth/Nature Communications
The model can generate millions of proteins in minutes, says Ferruz. “Without further improvements, people could take the model, which is freely available, and fine-tune a set of sequences to produce more sequences in this region,” such as for antibiotics or vaccines. But also, she adds, with small modifications in the training process “we could add labels, and potentially in the future start generating sequences with a specific function.” This in turn has potential for uses in not just medical and biomedical fields but also in environmental sciences and more.
Ferruz acknowledges the rapid developments in the NLP space for the success of ProtGPT2, but also points out that this is an ever-changing space—“It’s crazy, all the things that have happened in the last 12 months.” At the moment, she and her colleagues are already writing a review of their work. “I trained this model over Christmas [2021],” she says, “and at the time, there was another model that had been described...but it wasn’t available.” Yet by this spring, she says, other models had been released.
ProtGPT2’s predicted sequences spanned new, rarely explored regions of protein structure and function. However, a few weeks ago, DeepMind released structures of over 200 million proteins. “So I guess we don’t have that much of a dark proteome anymore,” Ferruz says. “But still, there are regions…that haven’t been explored.”
There is plenty of work ahead, though. “I would like to have control over the design process,” Ferruz adds. “We will need to take the sequence, predict the structure, and maybe predict the function if it has any….That will be very challenging.”
- OpenAI's GPT-3 Speaks! (Kindly Disregard Toxic Language) - IEEE ... ›
- For Centuries, People Dreamed of a Machine That Could Produce ... ›
- GPT Protein Models Speak Fluent Biology - IEEE Spectrum ›


