
Elon Musk's brain tech company, Neuralink, is subject to rampant speculation and misunderstanding. Just start a Google search with the phrase “can Neuralink..." and you'll see the questions that are commonly asked, which include “can Neuralink cure depression?" and “can Neuralink control you?" Musk hasn't helped ground the company's reputation in reality with his public statements, including his claim that the Neuralink device will one day enable “AI symbiosis" in which human brains will merge with artificial intelligence.
It's all somewhat absurd, because the Neuralink brain implant is still an experimental device that hasn't yet gotten approval for even the most basic clinical safety trial.
But behind the showmanship and hyperbole, the fact remains that Neuralink is staffed by serious scientists and engineers doing interesting research. The fully implantable brain-machine interface (BMI) they've been developing is advancing the field with its super-thin neural “threads" that can snake through brain tissue to pick up signals and its custom chips and electronics that can process data from more than 1000 electrodes.
In August 2020 the company demonstrated the technology in pigs, and this past April it dropped a YouTube video and blog post showing a monkey using the implanted device, called a Link, to control a cursor and play the computer game Pong. But the BMI team hasn't been public about its current research goals, and the steps it's taking to achieve them.
In this exclusive Q&A with IEEE Spectrum, Joseph O'Doherty, a neuroengineer at Neuralink and head of its brain signals team, lays out the mission.
Aiming for a World Record
IEEE Spectrum: Elon Musk often talks about the far-future possibilities of Neuralink; a future in which everyday people could get voluntary brain surgery and have Links implanted to augment their capabilities. But whom is the product for in the near term?
Joseph O'Doherty: We're working on a communication prosthesis that would give back keyboard and mouse control to individuals with paralysis. We're pushing towards an able-bodied typing rate, which is obviously a tall order. But that's the goal. We have a very capable device and we're aware of the various algorithmic techniques that have been used by others. So we can apply best practices engineering to tighten up all the aspects. What it takes to make the BMI is a good recording device, but also real attention to detail in the decoder, because it's a closed-loop system. You need to have attention to that closed-loop aspect of it for it to be really high performance. We have an internal goal of trying to beat the world record in terms of information rate from the BMI. We're extremely close to exceeding what, as far as we know, is the best performance. And then there's an open question: How much further beyond that can we go? My team and I are trying to meet that goal and beat the world record. We'll either nail down what we can, or, if we can't, figure out why not, and how to make the device better.
The Hardware
Spectrum: The Neuralink system has been through some big design changes over the years. When I was talking to your team in 2019, the system wasn't fully implantable, and there was still a lot in flux about the design of the threads, how many electrodes per thread, and the implanted chip. What's the current design?
O'Doherty: The threads are often referred to as the neural interface itself; that's the physical part that actually interfaces with the tissue. The broad approach has stayed the same throughout the years: It's our hypothesis that making these threads extremely small and flexible is good for the long-term life of the device. We hope it will be something that the immune system likes, or at least dislikes less. That approach obviously comes with challenges because we have very, very small things that need to be robust over many years. And a lot of the techniques that are used to make things robust have to do with adding thickness and adding layers and having barriers.
Spectrum: I imagine there are a lot of trade-offs between size and robustness.
O'Doherty: There are other flexible and very cool neural interfaces out in the world that we read about in academic publications. But those demonstrations often only have to work for the one hour or one day that the experiment is done. Whereas we need to have this working for many, many, many, many days. It's a totally different solution space.
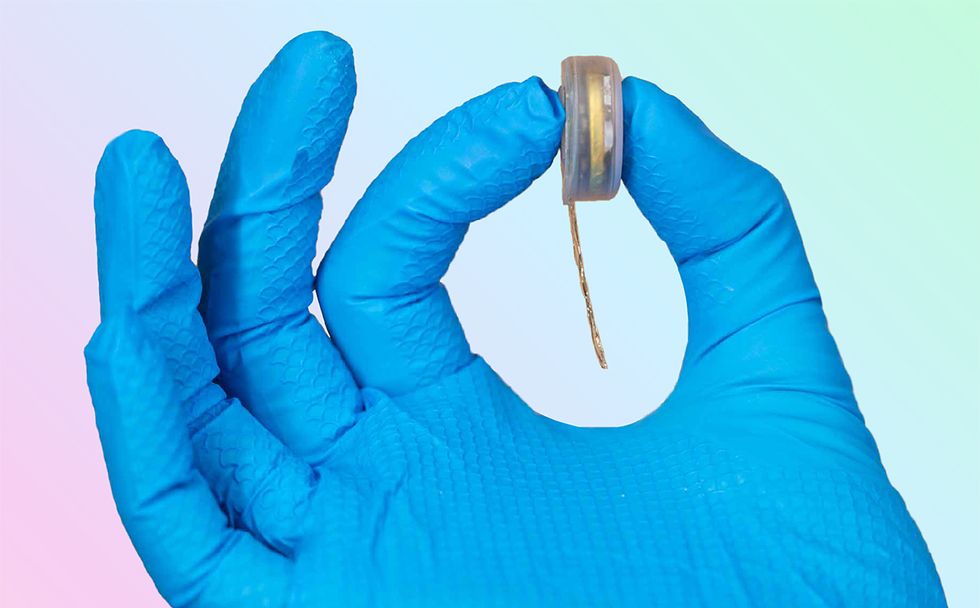 Neuralink
Neuralink
Spectrum: When I was talking to your team in 2019, there were 128 electrodes per thread. Has that changed? O'Doherty: Right now we're doing 16 contacts per thread, spaced out by 200 microns. The earlier devices were denser, but it was overkill in terms of sampling neurons in various layers of the cortex. We could record the same neurons on multiple adjacent channels when the contacts were something like 20 microns apart. So we could do a very good job of characterizing the individual neurons we were recording from, but it required a lot of density, a lot of stuff packed in one spot, and that meant more power requirements. That might be great if you're doing neuroscience, perhaps with less good if you're trying to make a functional product. That's one reason why we changed our design to spread out our contacts in the cortex, and to distribute them on many threads across the cortical area. That way we don't have redundant information. The current design is 16 channels per thread, and we have 64 of these threads that we can place wherever we want within the cortical region, which adds up to 1,024 channels. Those threads go to a single tiny device that's smaller than a quarter, which has the algorithms, the spike detection, battery, telemetry, everything. In addition to 64x16, we're also testing 128x8 and 256x4 configurations to see if there are performance gains. We ultimately have the flexibility to do any configuration of 1024 electrodes we'd like.
Spectrum: Does each Link device have multiple chips?
O'Doherty: Yes. The actual hardware is a 256-channel chip, and there are four of them, which adds up to 1,024 channels. The Link acts as one thing, but it is actually made up of four chips.
Spectrum: I imagine you're continually upgrading the software as you push toward your goal, but is the hardware fixed at this point? O'Doherty: Well, we're constantly working on the next thing. But it is the case that we have to prove the safety of a particular version of the device so that we can translate that to humans. We use what are called design controls, where we fix the device so we can describe what it is very well and describe how we are testing its safety. Then we can make changes, but we do it under an engineering control framework. We describe what we're changing and then we can either say this change is immaterial to safety or we have to do these tests.
The Software
Spectrum: It sounds like a lot of the spike detection is being done on the chips. Is that something that's evolved over time? I think a few years back it was being done on an external device.
O'Doherty: That's right. We have a slightly different approach to spike detection. Let me first give a couple of big picture comments. For neuroscience, you often don't just want to detect spikes. You want to detect spikes and then sort spikes by which neurons generated them. If you detect a spike on a channel and then realize, Oh, I can actually record five different neurons here. Which neuron did it come from? How do I refer each spike to the neuron that generated it? That's a very difficult computational problem. That's something that's often done in post-processing—so after you record a bunch of data, then you do a bunch of math. There's another extreme where you simply put a threshold on your voltage, and you say that every time something crosses that threshold, it's a spike. And then you just count how many of those happen. That's all. That's all the information you can use.
Both extremes are not great for us. In the first one, you're doing a lot of computation that's perhaps infeasible to do in a small package. With the other extreme, you're very sensitive to noise and artifacts because many things can cause a threshold crossing that are not neurons firing. So we're using an approach in the middle, where we're looking for shapes that look like the signals that neurons generate. We transmit those events, along with a few extra bits of information about the spike, like how tall it is, how wide it is, and so on. That's something that we were previously doing on the external part of the device. At the time we validated that algorithm, we had much higher bandwidth, because it was a wired system. So we were able to stream a lot of data and develop this algorithm. Then the chip team took that algorithm and implemented it in hardware. So now that's all happening automatically on the chip. It's automatically tuning its parameters—it has to learn about the statistical distribution of the voltages in the brain. And then it just detects spikes and sends them out to the decoder.
Spectrum: How much data is coming off the device these days?
O'Doherty: To address this in brain-machine interface terms, we are detecting spikes within a 25-millisecond window or “bin." So the vectors of information that we use in our algorithms for closed-loop control are factors of spike counts: 1,024 by 25 milliseconds. We count how many spikes occur per channel and that's what we send out. We only need about four bits per bin, so that's four bits times forty bins per second times 1,024 channels, or about 20 kilobytes each second. That degree of compression is made possible by the fact that we're spike detecting with our custom algorithm on the chip. The maximum bandwidth would be 1,024 channels times 20,000 samples per second, which is a pretty big number. That's if we could send everything. But the compressed version is just the number of spike events that occur—zero one, two, three, four, whatever—times 1,024 channels. For our application, which is controlling our communications prosthesis, this data compression is a good way to go—and we still have usable signals for closed-loop control.
Spectrum: When you say closed-loop control, what does that mean in this context?
O'Doherty: Most machine learning is open-loop. Say you have an image and you analyze it with a model and then produce some results, like detecting the faces in a photograph. You have some inference you want to do, but how quickly you do it doesn't generally matter. But here the user is in the loop—the user is thinking about moving and the decoder is, in real time, decoding those movement intentions, and then taking some action. It has to act very quickly because if it's too slow, it doesn't matter. If you throw a ball to me and it takes my BMI five seconds to infer that I want to move my arm forward—that's too late. I'll miss the ball. So the user changes what they're doing based on visual feedback about what the decoder does: That's what I mean by closed loop. The user makes a motor intent; it's decoded by the Neuralink device; the intended motion is enacted in the world by physically doing something with a cursor or a robot arm; the user sees the result of that action; and that feedback influences what motor intent they produce next. I think the closest analogy outside of BMI is the use of a virtual reality headset—if there's a big lag between what you do and what you see on your headset, it's very disorienting, because it breaks that closed-loop system.
What He's Working on Right Now
Spectrum: What has to happen to get from where you are right now to best-in-world?
O'Doherty: Step one is to find the sources of latency and eliminate all of them. We want to have low latency throughout the system. That includes detecting spikes; that includes processing them on the implant; that includes the radio that has to transmit them—there's all kinds of packetization details with Bluetooth that can add latency. And that includes the receiving side, where you do some processing in your model inference step, and that even includes drawing pixels on the screen for the cursor that you're controlling. Any small amount of lag that you have there adds delay and that affects closed-loop control.
Spectrum: OK, so let's imagine all latency has been eliminated. What next?
O'Doherty: Step two is the decoder itself, and the model that it uses. There's great flexibility in terms of the model—it could be very simple, very complex, very nonlinear, or very deep in terms of deep learning—how many layers your entire network has. But we have particular constraints. We need our decoder model to work fast, so we can't use a sophisticated decoder that's very accurate but takes too long to be useful. We're also potentially interested in running the decoder on the implant itself, and that requires both low memory usage, so we don't have to store a lot of parameters in a very constrained environment, and also compute efficiency so we don't use a lot of clock cycles. But within that space, there's some clever things we can do in terms of mapping neural spikes to movement. There are linear models that are very simple and nonlinear models that give us more flexibility in capturing the richness of neural dynamics. We want to find the right sweet spot there. Other factors include the speed at which you can calibrate the decoder to the user. If we have to spend a long time training the decoder, that's not a great user experience. We want something that can come online really quickly and give the subject a lot of time to practice with the device. We're also focusing on models that are robust. So from day one to day two to day three, we don't want to have to recalibrate or re-tune the decoder. We want one that works on day one and that works reliably for a long time. Eventually, we want decoders that calibrate themselves, even without the user thinking about it. So the user is just going about their day doing things that cause the model to stay calibrated.
Spectrum: Are there any decoder tricks or hacks you've figured out that you can tell me about?
O'Doherty: One thing we find particularly helpful is decoding click intention. When a BMI user moves a cursor to a target, they typically need to dwell on that target for a certain amount of time, and that is considered a click. The user dwelled for 200 milliseconds, so they selected it. Which is fine, but it adds delay because the user has to wait that amount of time for the selection to happen. But if we decode click intention directly, that lets the user make selections that much faster.
And this is something that we're working on—we don't have a result yet. But we can potentially look into the future. Imagine you're making a movement with the brain-controlled cursor, and I know where you are now… but maybe I also know where you're going to want to go in a second. If I know that, I can do some tricks, I can just teleport you there and get you there faster. And honestly, practice is a component. These neuroprosthetic skills have to be learned by the user, just like learning to type or any other skill. We've seen this with non-human primates, and I've heard it's also true of human participants in BrainGate trials. So we want a decoder that doesn't pose too much of a learning burden. Beyond that, I can speculate on cool stuff that could be done. For example, you type faster with two fingers than one finger, or text faster with two thumbs versus one pointer finger. So imagine decoding movement intention for two thumbs to control your brain-controlled keyboard and mouse. That could potentially be a way to boost performance.
Spectrum: What is the current world record for BMI rate? O'Doherty: Krishna Shenoy of Stanford has been keeping track of this in some tables of BCI performance, which includes the paper that recently came out from his group. That paper set the record with a maximum bit rate of 6.18 bits per second with human participants. For non-human primates, the record is 6.49 bits per second.
Spectrum: And can you prove best-in-world BMI with non-human primates, or do you need to get into humans for that?
O'Doherty: That's a good question. Non-human primates can't talk or read English, so to some extent we have to make inferences. With a human participant you might say, here's a sentence we'd like you to copy, please type it as best you can. And then we can look at performance there. For the monkey, we can create a string of sequences and ask them to do it quickly and compute performance rates that way. Monkeys are motivated and they'll do those tasks. So I don't see any reason, in principle, why one is superior to the other for this. For linguistic and semantic tasks like decoding speech or decoding text directly from your brain we'll have to prototype in humans, of course. But until we get to that point, and even after that, non-human primates and other animal models are really important for proving out the technology.
What the Limits Are, Where the Ceiling Is
Spectrum: You said earlier that your team will either achieve a new world record or find out the reason why you can't. Are there reasons why you think it might not work? O'Doherty: The 2D cursor control is not a very high-dimension task. There are probably limits that have to do with intention and speed. Think about how long it takes to move a cursor around and hit targets: It's the time it takes the user to go from point A to point B, and the time it takes to select when they're at point B. Also if they make a mistake and click the wrong button, that's really bad. So they have to go faster between A and B, they have to click there more reliably, and they can't make mistakes.
At some point, we're going to hit a limit, because the brain can't keep up. If the cursor is going too fast, the user won't even see it moving. I think that's where the limits will come from—not the neural interfacing, but what it means to move a cursor around. So then we'll have to think about other interesting ways to interface with the brain to get beyond that. There are other ways of communicating that might be better—maybe it will involve ten-finger typing. I think it's an open question where that ceiling is.
Spectrum: Both the games that the monkey played were basically just cursor control: finding targets and using a cursor to move the paddle in Pong. Can you imagine any tests that would go beyond that for non-human primates?
O'Doherty: Non-human primates can learn other more complicated tasks. The training can be lengthy, because we can't tell them what to do; we have to show them and take small steps toward more complicated things. To pick a game out of a hat: Now we know that monkeys can play Pong, but can they play Fruit Ninja? There's a training burden, but I think it's within their capability.
Spectrum: Is there anything else you want to emphasize about the technology, the work you're doing, or how you're doing it?
O'Doherty: I first started working on BMI in an academic environment. The concerns that we have at Neuralink are different from the concerns involved with making a BMI for an academic demonstration. We're really interested in the product, the experience of the user, the robustness, and having this device be useful across a long period of time. And those priorities necessarily lead to slightly different optimizations than I think we would choose if we were doing this for a one-off demonstration. We really enjoyed the Pong demo, but we're not here to make Pong demos. That's just a teaser for what will be possible when we bring our product to market.
This article appears in the September 2021 print issue as "Elon Musk's Mind Games."
- How Do Neural Implants Work? - IEEE Spectrum ›
- What the Media Missed About Elon Musk's $150 Million Augmented ... ›
- Elon Musk Announces Neuralink Advance Toward Syncing Our ... ›
- Neuralink’s FDA Troubles Are Just the Beginning - IEEE Spectrum ›
- Worldwide Campaign for Neurorights Notches Its First Win - IEEE Spectrum ›


