
Look under the hood of a car and you’ll see an efficient modular design with each component performing specific actions: The fuel injectors squirt fuel into the cylinders (or intake manifold); the coil packs send high-voltage pulses to the spark plugs, the catalytic converter removes problematic exhaust gases, and so forth. Look under the hood of a large deep neural network, the workhorse of modern AI, and you’ll see something that looks a lot more generic and disorganized: a mathematical model with billions of parameters whose inner workings are often mysterious even to its creators.
But allowing all that staggering complexity has been crucial for deep learning to achieve the amazing feats it has. Deep neural networks can detect cancer more accurately than do doctors. Such a network has beaten the world champion in the game of Go. And these networks can figure out appropriate tax policies when traditional economic models would be too complex to solve. The downside is that the enormous computational and energy costs needed to use these systems are making AI based on deep learning unsustainable.
But it is possible to lower these costs by changing when and how deep learning is used. Currently, people often use huge neural networks to learn about the world. The many parameters in these networks provide the flexibility needed to discover new patterns in how things work. But, once these underlying patterns have been unearthed, an overwhelming share of the parameters in the model are unnecessary. These extra parameters just impose overhead, which should be avoided whenever possible.
Practitioners already attempt to reduce overhead by “pruning” their networks. That can help reduce the amount of computation (and hence energy) used in operating deep networks because many calculations can be avoided. Pruning techniques can even be interjected into the training process to reduce costs there as well. But recent research that we’ve been involved in has introduced new techniques that have the potential to help shrink the environmental footprint of AI much more dramatically.
Modern deep neural networks were first popularized in 2012, when AlexNet shattered records in image recognition, identifying objects in pictures far more accurately than did other models. As the name implies, deep neural networks were inspired by the neural connections in brains. Just as bigger-brained animals can solve more complex problems, the ever-bigger neural networks that researchers have fashioned can solve increasingly complicated problems—these huge networks have set records in computer vision, natural-language understanding, and other domains.
The problem now is that deep neural networks are growing too fast. Today, deep neural networks for image recognition require almost 100,000 times as many calculations as AlexNet. The size of modern neural networks built for natural-language processing are similarly worrisome: Researchers have estimated that training the state-of-the-art language generation model GPT-3 took weeks and cost millions of dollars. It also required 190,000 kilowatt-hours of electricity, producing the same amount of CO2 as driving a car a distance roughly equivalent to a trip to the moon and back!
We want a two-step process: Use the flexibility of deep learning to discover things, and then jettison the unneeded complexity by distilling the insights back into concise, efficient equations.
Spending huge amounts of energy in return for the feats that deep neural networks can provide is a trade-off that people have made many times in the last 10 years. And that’s understandable, since deep learning often finds solutions that are better than those human ingenuity has produced. But the flexibility that makes this possible requires neural networks to be enormous and inefficient.
If we continue to develop ever bigger networks, as researchers are doing now, society will end up with major new sources of greenhouse gases. We’ll also end up with economic monopolies because only a few companies and organizations will be able to afford to create these systems.
One way that specialists could make their neural networks more efficient is to imitate what’s been done since the dawn of science, which is to turn large amounts of data (observations of the physical world) into equations that describe concisely how the world works. One of us (Udrescu) recently did this, as part of a team that worked out an algorithmic approach for iteratively distilling neural networks down to efficient computational nuggets. The result was exemplified in something called AI Feynman, which turns a set of input-output data into succinct equations that summarize how those data are related.
To better understand how this worked, imagine trying to model gravity using a neural network. To teach the network, you would show it many examples of gravity in action—apples falling from trees, cannon balls flying through the air, maybe satellites circling Earth.
Eventually, the network would become a gravity calculator, predicting with high accuracy how objects fall. But there is a catch. The “neural equation for gravity” found by the network would be voluminous, including those many parameters that make deep learning so flexible. Indeed, when the AI Feynman researchers modeled gravity this way, the resulting equation would have filled 32,000,000 chalkboards!
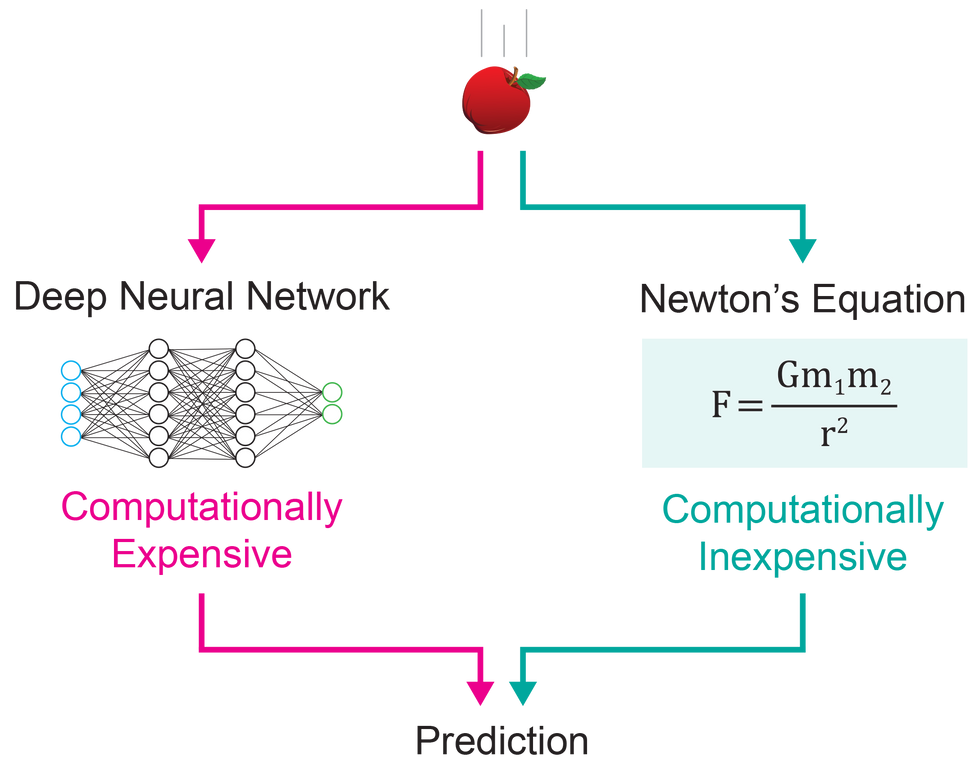 While deep networks are immensely flexible in what they can model, they are more expensive to run than are systems that use equations, which are preferable when the phenomenon at hand is amenable to being described by them.Alison Walsh
While deep networks are immensely flexible in what they can model, they are more expensive to run than are systems that use equations, which are preferable when the phenomenon at hand is amenable to being described by them.Alison Walsh
The irony, of course, is that we know that there is a simple and efficient way to model gravity: Newton’s equation, which is taught in high school physics. All the rest of the complexity in the neural-network version came from having to discover this formula using deep learning. That is overhead you’d like to shed so you don’t have to pay the computational costs of running it.
What we are suggesting is a two-step process: First, use the flexibility of deep learning to discover things; then jettison the unneeded complexity by distilling the insights gained from the network back into concise, efficient equations.
The AI Feynman team did that exact experiment, wherein 120 neural networks were taught to predict various natural phenomena, including gravity. In 118 of the 120 cases, it was possible to use this “symbolic distillation” technique to cut those oversized networks all the way down from the millions-of-parameter models to the underlying (extremely efficient) physics equation.
Symbolic distillation is more sophisticated than pruning because of how it learns from data and deduces the overall relationship between inputs and outputs. So, in our gravity example, the algorithm would analyze how particular inputs, like the mass of an object, affect the answer the network predicts. Whole parts of the network can then be simplified based on a variety of telltale signs, such as when two variables don’t interact. Even better, as the network gets simpler, it becomes feasible to test whether whole sections can be replaced with mathematical equations, which are easier to calculate and are more interpretable than what’s normally inside these networks.
Of course, this technique won’t always be as effective as it is for gravity. For example, some phenomena may be inherently complex—for example, the turbulent flow of fast-moving water or natural language—and simple underlying equations may not emerge. But where it does work, this technique promises to reduce the computational cost (and hence environmental cost) of these models by many orders of magnitude.
Thus far what we’ve described only helps with deployment of a deep-learning system, because the full network must still be trained normally in the first place. But symbolic distillation can also help with future training costs by taking advantage of modularity. Already, trainable or premade modules are being used in network design. For example, researchers have designed networks with separate modules so that each can become an expert in a particular subtask. Convolutions and attention layers can also be seen as trained modules and are in widespread use in image recognition.
The problem is that you can’t build an efficient module that you haven’t yet discovered. This limits the ability of traditional neural networks to build on the results of similar networks that came before them. But symbolic distillation suggests an alternative: You could learn concepts, transform these into modules, and then use them as premade building blocks for subsequent networks. Indeed, you can even create these modules as part of the training process.
How does this work? Imagine a neural network that predicts where a baseball will land once it has been hit. It will clearly need to understand concepts like gravity and air resistance, either explicitly or implicitly. With symbolic distillation, these two concepts could be first learned as modules, and the number of calculations could then be drastically reduced by replacing these network modules by equations. What’s more, these modules could then be reused as part of future networks that predict where meteorites, say, will land, which would save the cost of training such functionality over and over.
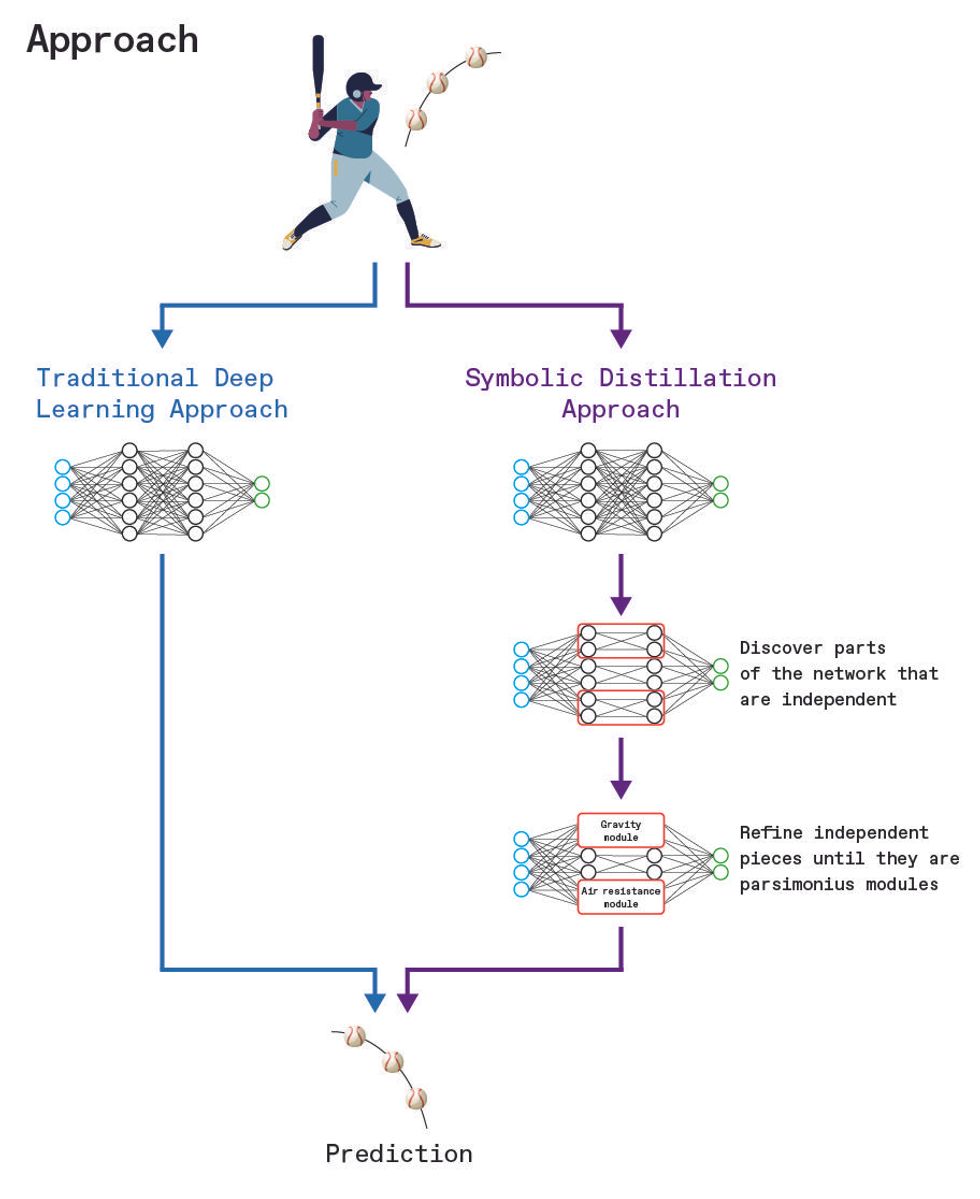 The authors suggest a new approach to deep learning, called network distillation, by which parts of an otherwise complicated deep network are replaced by modules based on concise equations.Alison Walsh
The authors suggest a new approach to deep learning, called network distillation, by which parts of an otherwise complicated deep network are replaced by modules based on concise equations.Alison Walsh
We believe that such a modular approach will lessen the cost of AI based on deep learning. It requires three distinct steps:
First, test whether existing systems can be modularized and simplified without losing accuracy, robustness, or other desirable features. If so, use these streamlined systems for implementations. If the system (or a part of it) can be represented by a simple formula, you also learn what aspect of the world the neural network was modeling. This may help develop an understanding of the fundamental properties of complex systems, something not possible with the current black-box approach.
Second, use the new streamlined modules to help train subsequent neural networks. For example, include a module that calculates the simple formula for gravity in a system designed to detect planetary systems from astronomical measurements. This strategy would help reduce the cost of future training as researchers develop more and more such modules.
Finally, build replicable machine-learning modules and systems by expanding in the emerging area of machine-learning operations (MLOps). This area applies best practices from software engineering to machine-learning models. This effort could include version control and continuous integration to build large machine-learning systems around reusable modules and trainable parts.
The pressure to change how we do machine learning is growing rapidly. Already, many companies cannot innovate in important areas for which deep learning could be applied because they cannot afford the price tag. Even for those that can stomach the expense, expanding carbon footprints threaten to make deep learning environmentally unsustainable.
But deep learning can become more benign by using the complexity of neural networks only to learn about new aspects of the world, while invoking efficient, pretrained modules elsewhere. Streamlining modules, ideally down to simple mathematical equations, could slash the cost of running many AI systems and, we hope, reduce the training cost for these future systems as well.
Ultimately, we see the biggest benefit of symbolic distillation coming from its ability to address Canadian computer scientist Richard Sutton’s bitter lesson—that the history of AI is one of people trying to incorporate their expertise into systems, but then more-powerful computers overtake these efforts. We believe that a hybrid approach may provide some sweetener for Sutton’s bitter lesson by using AI systems first to learn new results, but then also to find an efficient way to implement them. Such an approach can help us make the AI enterprise sustainable.
- Deep Learning's Diminishing Returns - IEEE Spectrum ›
- Making Information Tech Greener Can Help Address the Climate ... ›
- Can Electronics Become Compostable? - IEEE Spectrum ›


