The Conversation (2)

A paralyzed man who hasn’t spoken in 15 years uses a brain-computer interface that decodes his intended speech, one word at a time.
University of California, San Francisco
Blue
A computer screen shows the question “Would you like some water?” Underneath, three dots blink, followed by words that appear, one at a time: “No I am not thirsty.”
It was brain activity that made those words materialize—the brain of a man who has not spoken for more than 15 years, ever since a stroke damaged the connection between his brain and the rest of his body, leaving him mostly paralyzed. He has used many other technologies to communicate; most recently, he used a pointer attached to his baseball cap to tap out words on a touchscreen, a method that was effective but slow. He volunteered for my research group’s clinical trial at the University of California, San Francisco in hopes of pioneering a faster method. So far, he has used the brain-to-text system only during research sessions, but he wants to help develop the technology into something that people like himself could use in their everyday lives.
In our pilot study, we draped a thin, flexible electrode array over the surface of the volunteer’s brain. The electrodes recorded neural signals and sent them to a speech decoder, which translated the signals into the words the man intended to say. It was the first time a paralyzed person who couldn’t speak had used neurotechnology to broadcast whole words—not just letters—from the brain.
That trial was the culmination of more than a decade of research on the underlying brain mechanisms that govern speech, and we’re enormously proud of what we’ve accomplished so far. But we’re just getting started. My lab at UCSF is working with colleagues around the world to make this technology safe, stable, and reliable enough for everyday use at home. We’re also working to improve the system’s performance so it will be worth the effort.
How neuroprosthetics work
 The first version of the brain-computer interface gave the volunteer a vocabulary of 50 practical words. University of California, San Francisco
The first version of the brain-computer interface gave the volunteer a vocabulary of 50 practical words. University of California, San Francisco
Neuroprosthetics have come a long way in the past two decades. Prosthetic implants for hearing have advanced the furthest, with designs that interface with the cochlear nerve of the inner ear or directly into the auditory brain stem. There’s also considerable research on retinal and brain implants for vision, as well as efforts to give people with prosthetic hands a sense of touch. All of these sensory prosthetics take information from the outside world and convert it into electrical signals that feed into the brain’s processing centers.
The opposite kind of neuroprosthetic records the electrical activity of the brain and converts it into signals that control something in the outside world, such as a robotic arm, a video-game controller, or a cursor on a computer screen. That last control modality has been used by groups such as the BrainGate consortium to enable paralyzed people to type words—sometimes one letter at a time, sometimes using an autocomplete function to speed up the process.
For that typing-by-brain function, an implant is typically placed in the motor cortex, the part of the brain that controls movement. Then the user imagines certain physical actions to control a cursor that moves over a virtual keyboard. Another approach, pioneered by some of my collaborators in a 2021 paper, had one user imagine that he was holding a pen to paper and was writing letters, creating signals in the motor cortex that were translated into text. That approach set a new record for speed, enabling the volunteer to write about 18 words per minute.
In my lab’s research, we’ve taken a more ambitious approach. Instead of decoding a user’s intent to move a cursor or a pen, we decode the intent to control the vocal tract, comprising dozens of muscles governing the larynx (commonly called the voice box), the tongue, and the lips.
 The seemingly simple conversational setup for the paralyzed man [in pink shirt] is enabled by both sophisticated neurotech hardware and machine-learning systems that decode his brain signals. University of California, San Francisco
The seemingly simple conversational setup for the paralyzed man [in pink shirt] is enabled by both sophisticated neurotech hardware and machine-learning systems that decode his brain signals. University of California, San Francisco
I began working in this area more than 10 years ago. As a neurosurgeon, I would often see patients with severe injuries that left them unable to speak. To my surprise, in many cases the locations of brain injuries didn’t match up with the syndromes I learned about in medical school, and I realized that we still have a lot to learn about how language is processed in the brain. I decided to study the underlying neurobiology of language and, if possible, to develop a brain-machine interface (BMI) to restore communication for people who have lost it. In addition to my neurosurgical background, my team has expertise in linguistics, electrical engineering, computer science, bioengineering, and medicine. Our ongoing clinical trial is testing both hardware and software to explore the limits of our BMI and determine what kind of speech we can restore to people.
The muscles involved in speech
Speech is one of the behaviors that sets humans apart. Plenty of other species vocalize, but only humans combine a set of sounds in myriad different ways to represent the world around them. It’s also an extraordinarily complicated motor act—some experts believe it’s the most complex motor action that people perform. Speaking is a product of modulated air flow through the vocal tract; with every utterance we shape the breath by creating audible vibrations in our laryngeal vocal folds and changing the shape of the lips, jaw, and tongue.
Many of the muscles of the vocal tract are quite unlike the joint-based muscles such as those in the arms and legs, which can move in only a few prescribed ways. For example, the muscle that controls the lips is a sphincter, while the muscles that make up the tongue are governed more by hydraulics—the tongue is largely composed of a fixed volume of muscular tissue, so moving one part of the tongue changes its shape elsewhere. The physics governing the movements of such muscles is totally different from that of the biceps or hamstrings.
Because there are so many muscles involved and they each have so many degrees of freedom, there’s essentially an infinite number of possible configurations. But when people speak, it turns out they use a relatively small set of core movements (which differ somewhat in different languages). For example, when English speakers make the “d” sound, they put their tongues behind their teeth; when they make the “k” sound, the backs of their tongues go up to touch the ceiling of the back of the mouth. Few people are conscious of the precise, complex, and coordinated muscle actions required to say the simplest word.
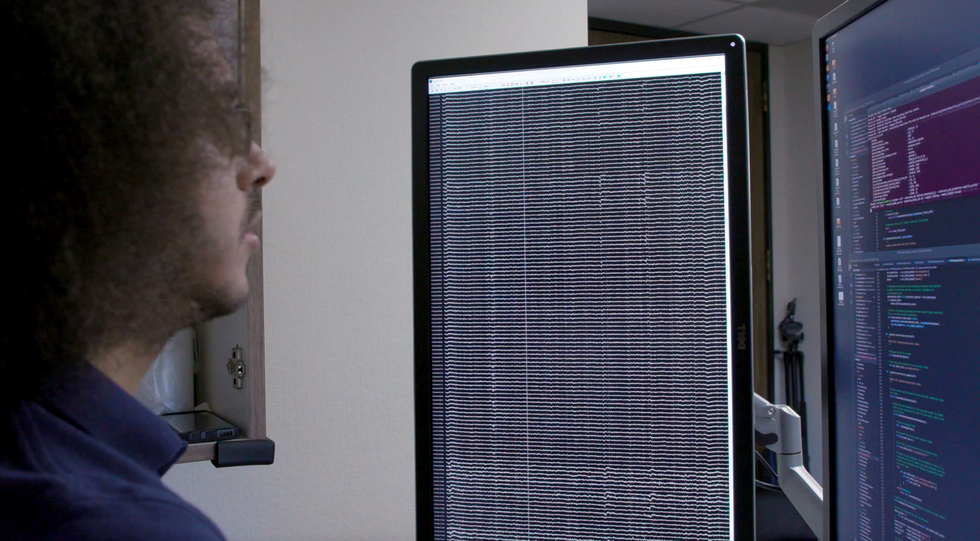 Team member David Moses looks at a readout of the patient’s brain waves [left screen] and a display of the decoding system’s activity [right screen].University of California, San Francisco
Team member David Moses looks at a readout of the patient’s brain waves [left screen] and a display of the decoding system’s activity [right screen].University of California, San Francisco
My research group focuses on the parts of the brain’s motor cortex that send movement commands to the muscles of the face, throat, mouth, and tongue. Those brain regions are multitaskers: They manage muscle movements that produce speech and also the movements of those same muscles for swallowing, smiling, and kissing.
Studying the neural activity of those regions in a useful way requires both spatial resolution on the scale of millimeters and temporal resolution on the scale of milliseconds. Historically, noninvasive imaging systems have been able to provide one or the other, but not both. When we started this research, we found remarkably little data on how brain activity patterns were associated with even the simplest components of speech: phonemes and syllables.
Here we owe a debt of gratitude to our volunteers. At the UCSF epilepsy center, patients preparing for surgery typically have electrodes surgically placed over the surfaces of their brains for several days so we can map the regions involved when they have seizures. During those few days of wired-up downtime, many patients volunteer for neurological research experiments that make use of the electrode recordings from their brains. My group asked patients to let us study their patterns of neural activity while they spoke words.
The hardware involved is called electrocorticography (ECoG). The electrodes in an ECoG system don’t penetrate the brain but lie on the surface of it. Our arrays can contain several hundred electrode sensors, each of which records from thousands of neurons. So far, we’ve used an array with 256 channels. Our goal in those early studies was to discover the patterns of cortical activity when people speak simple syllables. We asked volunteers to say specific sounds and words while we recorded their neural patterns and tracked the movements of their tongues and mouths. Sometimes we did so by having them wear colored face paint and using a computer-vision system to extract the kinematic gestures; other times we used an ultrasound machine positioned under the patients’ jaws to image their moving tongues.
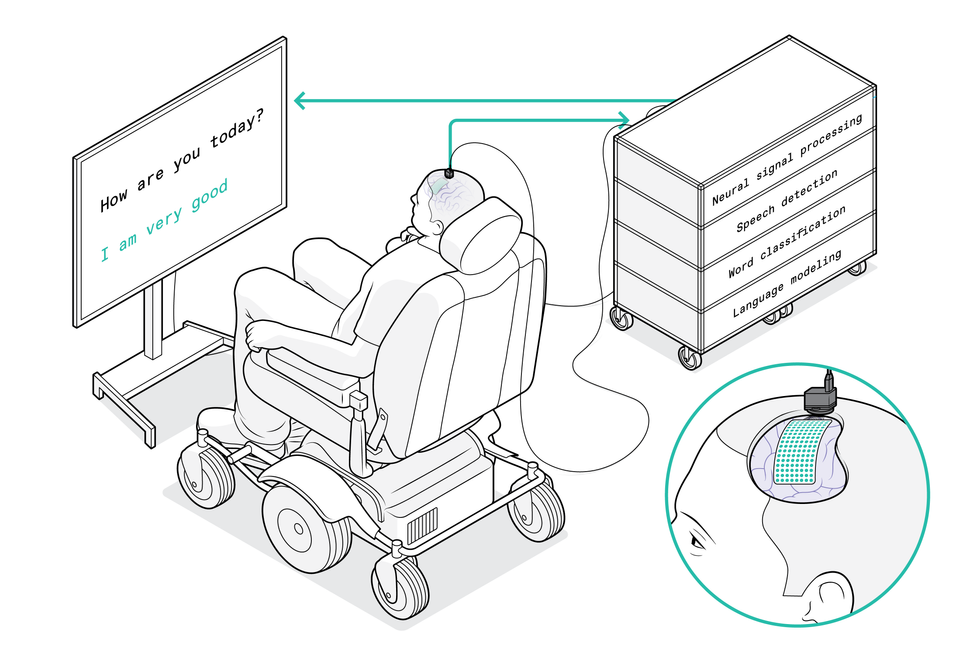 The system starts with a flexible electrode array that’s draped over the patient’s brain to pick up signals from the motor cortex. The array specifically captures movement commands intended for the patient’s vocal tract. A port affixed to the skull guides the wires that go to the computer system, which decodes the brain signals and translates them into the words that the patient wants to say. His answers then appear on the display screen.Chris Philpot
The system starts with a flexible electrode array that’s draped over the patient’s brain to pick up signals from the motor cortex. The array specifically captures movement commands intended for the patient’s vocal tract. A port affixed to the skull guides the wires that go to the computer system, which decodes the brain signals and translates them into the words that the patient wants to say. His answers then appear on the display screen.Chris Philpot
We used these systems to match neural patterns to movements of the vocal tract. At first we had a lot of questions about the neural code. One possibility was that neural activity encoded directions for particular muscles, and the brain essentially turned these muscles on and off as if pressing keys on a keyboard. Another idea was that the code determined the velocity of the muscle contractions. Yet another was that neural activity corresponded with coordinated patterns of muscle contractions used to produce a certain sound. (For example, to make the “aaah” sound, both the tongue and the jaw need to drop.) What we discovered was that there is a map of representations that controls different parts of the vocal tract, and that together the different brain areas combine in a coordinated manner to give rise to fluent speech.
The role of AI in today’s neurotech
Our work depends on the advances in artificial intelligence over the past decade. We can feed the data we collected about both neural activity and the kinematics of speech into a neural network, then let the machine-learning algorithm find patterns in the associations between the two data sets. It was possible to make connections between neural activity and produced speech, and to use this model to produce computer-generated speech or text. But this technique couldn’t train an algorithm for paralyzed people because we’d lack half of the data: We’d have the neural patterns, but nothing about the corresponding muscle movements.
The smarter way to use machine learning, we realized, was to break the problem into two steps. First, the decoder translates signals from the brain into intended movements of muscles in the vocal tract, then it translates those intended movements into synthesized speech or text.
We call this a biomimetic approach because it copies biology; in the human body, neural activity is directly responsible for the vocal tract’s movements and is only indirectly responsible for the sounds produced. A big advantage of this approach comes in the training of the decoder for that second step of translating muscle movements into sounds. Because those relationships between vocal tract movements and sound are fairly universal, we were able to train the decoder on large data sets derived from people who weren’t paralyzed.
A clinical trial to test our speech neuroprosthetic
The next big challenge was to bring the technology to the people who could really benefit from it.
The National Institutes of Health (NIH) is funding our pilot trial, which began in 2021. We already have two paralyzed volunteers with implanted ECoG arrays, and we hope to enroll more in the coming years. The primary goal is to improve their communication, and we’re measuring performance in terms of words per minute. An average adult typing on a full keyboard can type 40 words per minute, with the fastest typists reaching speeds of more than 80 words per minute.
 Edward Chang was inspired to develop a brain-to-speech system by the patients he encountered in his neurosurgery practice. Barbara Ries
Edward Chang was inspired to develop a brain-to-speech system by the patients he encountered in his neurosurgery practice. Barbara Ries
We think that tapping into the speech system can provide even better results. Human speech is much faster than typing: An English speaker can easily say 150 words in a minute. We’d like to enable paralyzed people to communicate at a rate of 100 words per minute. We have a lot of work to do to reach that goal, but we think our approach makes it a feasible target.
The implant procedure is routine. First the surgeon removes a small portion of the skull; next, the flexible ECoG array is gently placed across the surface of the cortex. Then a small port is fixed to the skull bone and exits through a separate opening in the scalp. We currently need that port, which attaches to external wires to transmit data from the electrodes, but we hope to make the system wireless in the future.
We’ve considered using penetrating microelectrodes, because they can record from smaller neural populations and may therefore provide more detail about neural activity. But the current hardware isn’t as robust and safe as ECoG for clinical applications, especially over many years.
Another consideration is that penetrating electrodes typically require daily recalibration to turn the neural signals into clear commands, and research on neural devices has shown that speed of setup and performance reliability are key to getting people to use the technology. That’s why we’ve prioritized stability in creating a “plug and play” system for long-term use. We conducted a study looking at the variability of a volunteer’s neural signals over time and found that the decoder performed better if it used data patterns across multiple sessions and multiple days. In machine-learning terms, we say that the decoder’s “weights” carried over, creating consolidated neural signals.
University of California, San Francisco
Because our paralyzed volunteers can’t speak while we watch their brain patterns, we asked our first volunteer to try two different approaches. He started with a list of 50 words that are handy for daily life, such as “hungry,” “thirsty,” “please,” “help,” and “computer.” During 48 sessions over several months, we sometimes asked him to just imagine saying each of the words on the list, and sometimes asked him to overtly try to say them. We found that attempts to speak generated clearer brain signals and were sufficient to train the decoding algorithm. Then the volunteer could use those words from the list to generate sentences of his own choosing, such as “No I am not thirsty.”
We’re now pushing to expand to a broader vocabulary. To make that work, we need to continue to improve the current algorithms and interfaces, but I am confident those improvements will happen in the coming months and years. Now that the proof of principle has been established, the goal is optimization. We can focus on making our system faster, more accurate, and—most important— safer and more reliable. Things should move quickly now.
Probably the biggest breakthroughs will come if we can get a better understanding of the brain systems we’re trying to decode, and how paralysis alters their activity. We’ve come to realize that the neural patterns of a paralyzed person who can’t send commands to the muscles of their vocal tract are very different from those of an epilepsy patient who can. We’re attempting an ambitious feat of BMI engineering while there is still lots to learn about the underlying neuroscience. We believe it will all come together to give our patients their voices back.
This article appears in the February 2023 print issue.
From Your Site Articles
- Fixing the Brain-Computer Interface - IEEE Spectrum ›
- Here's How Facebook's Brain-Computer Interface Development is ... ›
- Brain-Computer Interface Smashes Previous Record for Typing ... ›
- Growing Electronics Inside the Brain - IEEE Spectrum ›
- Dry EEG Sensors Control Army Robots - IEEE Spectrum ›
- Neurotech Overhears Songs from Listener’s Brainwaves - IEEE Spectrum ›
- Record Broken: Decoding Words From Brain Signals - IEEE Spectrum ›
- New Neurotech Eschews Electricity for Ultrasound - IEEE Spectrum ›
- UC Davis Hosts BCI Speech Prediction Contest - IEEE Spectrum ›
Related Articles Around the Web
{"imageShortcodeIds":[]}


