

Come One, Come All: As part of a cervical cancer prevention campaign in six African countries, the nonprofit Pink Ribbon Red Ribbon works with local health clinics on special screening and education events, such as this one in Botswana.



In rural health clinics across Kenya, women have started showing up with a surprising request: They’ve come for their “cervical selfies.”
Their enthusiasm is a good omen for a public health campaign against cervical cancer now under way in six African countries. Using an optical accessory that snaps onto any Android smartphone and makes use of its camera, health workers are examining women and catching early signs of cancer, enabling them to get immediate treatment. And soon this diagnostic device will be better still. With the integration of artificial intelligence, this technology may serve as a model for smarter health care in Africa and beyond.
The screening campaign relies on a tool developed by the Israeli company MobileODT—the acronym stands for “optical detection technologies.” Health workers use a clip-on attachment, called the EVA (enhanced visual assessment) Scope, to turn a smartphone into a device similar to a colposcope, the tool gynecologists use to view a magnified image of a woman’s cervix. With an associated phone app, the screeners can analyze the image, show it to the patient, and store the data in the cloud.
The campaign’s organizers originally worried that women wouldn’t be willing to be examined in such an intimate way—but in fact, many women have been not only willing but also quite interested in seeing their photos. Instead, the big challenge is ensuring that health workers make accurate diagnoses from these images. That’s where AI comes into play.
 Expert Eye: The EVA Scope clips onto any Android smartphone and uses its camera. It acts as a cheap and user-friendly colposcope, the tool gynecologists use to view a magnified image of a woman’s cervix.Photo: MobileODT
Expert Eye: The EVA Scope clips onto any Android smartphone and uses its camera. It acts as a cheap and user-friendly colposcope, the tool gynecologists use to view a magnified image of a woman’s cervix.Photo: MobileODT
At Global Good, the innovation hub where two of us (Champlin and Bell) work, we want to use today’s ubiquitous mobile technologies to transform health care, particularly in parts of the world that lack medical infrastructure. As a test case, we partnered with MobileODT to integrate machine-learning technology into the EVA Scope. In late 2017 we’ll begin field trials in Ethiopia.
This initiative fits the mission of Global Good, a collaborative effort between Bill Gates and the Bellevue, Wash.–based company Intellectual Ventures: to develop technologies that improve people’s lives in poor parts of the world. In this case, we’re drawing from seemingly esoteric research in machine learning and taking advantage of what are called convolutional neural networks (CNNs). Intellectual Ventures’ founder Nathan Myhrvold pioneered the idea of applying these computer science tactics to medical diagnostics, arguing that we can use CNNs to transform mobile phones into supersmart diagnostic tools, and thus help save millions of lives. It may not be possible to send an expert doctor to every health clinic across Africa—but with AI, we can send their expertise.
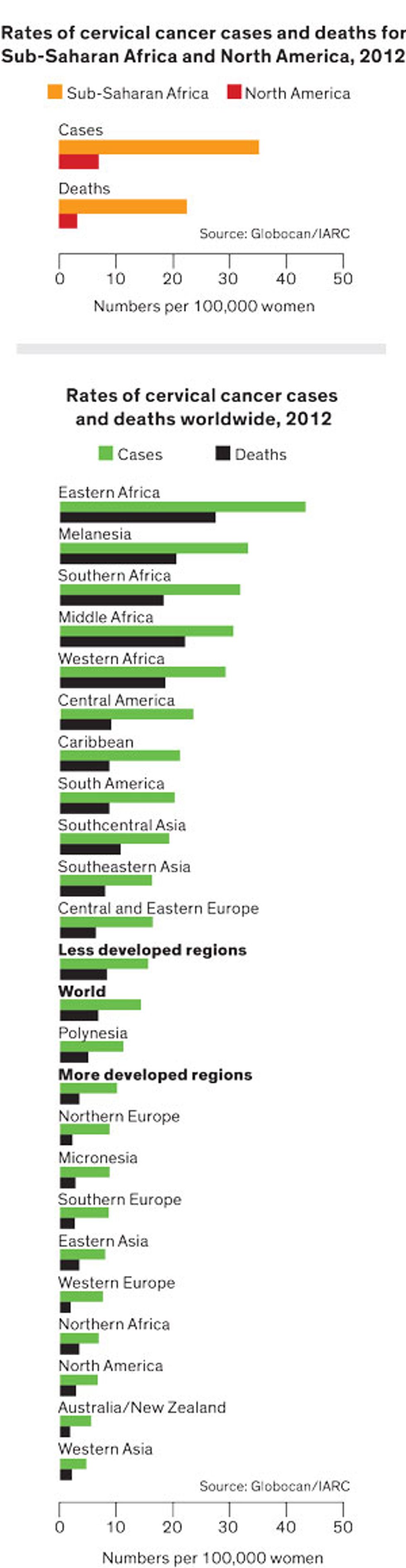
There’s good reason to focus on cervical cancer as a test case for this technology. About 270,000 women die from the disease every year, according to the World Health Organization, and 85 percent of those deaths occur in low-income countries. The disease strikes women in their prime adult years, when they’re raising families and earning money. That’s why the nonprofit Pink Ribbon Red Ribbon, which fights women’s cancers in countries where the need is greatest, has partnered with groups around the world to provide cervical cancer screening at local health clinics. (One of us, Schocken, is Pink Ribbon Red Ribbon’s CEO.)
There’s also good reason to think this campaign will make a real difference: Unlike so many forms of cancer, cervical cancer is largely preventable, treatable, and curable. Screening exams can reveal the early warning signs of the disease, which typically takes 10 to 15 years to progress to a dangerous stage. So health professionals have a tremendous opportunity to diagnose and treat this potential killer.
Up until now, though, the costs of wide-scale screening have been prohibitive in developing countries. Pink Ribbon Red Ribbon, based in Washington, D.C., estimates that only 5 percent of women in Africa have been checked.
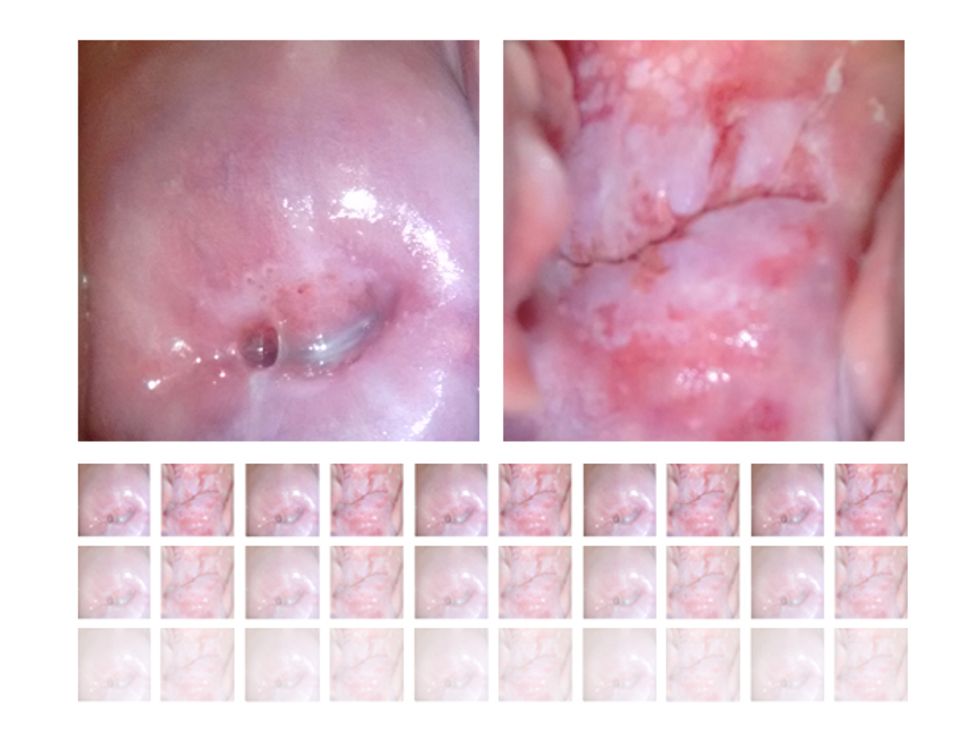
For the traditional screening protocol that’s been used around the world for decades, a health worker takes a sample of cervical cells (a Pap test), sends the sample to a lab for analysis, and then waits for results. This process is not only expensive; it can also take weeks in places with rough roads and few labs. Despite the slow-growing nature of cervical cancer, delay has serious consequences. Without same-day screening and treatment, many women never get the care they need. Women don’t follow up for many reasons: They may not be able to travel to the clinic again, their husbands may raise objections, or they may not understand the need to return.
A lifesaving breakthrough came in the 1990s when researchers realized that applying acetic acid—the basis of simple household vinegar—to the cervix causes precancerous lesions to turn white. A health worker can then destroy those abnormal cells in much the same way dermatologists remove a wart, with either heat or cold. This fast and relatively painless treatment stops cancer from developing—for a total cost of less than US $20. (In wealthier countries, women may opt for long-term monitoring of precancerous lesions or a more thorough surgery, but these options aren’t usually feasible in places like rural Kenya.)
Clinics in many developing countries are adopting visual screening programs, which have probably saved hundreds of thousands of lives already. However, the procedure isn’t perfect. Frontline health workers need training and supervision to differentiate between lesions that are truly signs of impending cancer and the many suspicious-looking conditions that are actually benign. Screeners may also miss evidence of advanced cancer that requires referral to a specialist.
The team at Global Good saw this situation not as a medical challenge but as a software engineering challenge. Where human eyes needed help, we would bring computer vision backed up by artificial intelligence.
We started by reviewing images of the cervix obtained by colposcopes. We quickly realized that typical computer vision software couldn’t handle this large and complex data set because the images had too many features with too much variability. We simply couldn’t design algorithms with detailed and exhaustive procedures for distinguishing between a healthy cervix and one with signs of trouble.
The situation called for machine learning—the branch of computer science in which the computer is given an objective, a software framework, and a large training data set, and is then left to create its own solution for carrying out the task at hand.
A common type of machine learning relies on deep neural networks (DNNs), so named because the computing scheme loosely mimics the brain’s interconnected neurons. Each computing node can be thought of as a neuron with many inputs. The artificial neuron performs some function based on those inputs and then outputs a single signal, which can serve as one of the inputs for other neurons. By arranging many layers of connected neurons, computer scientists enable these networks to handle tremendously complex tasks.
While the architecture of neural networks is inspired by the human brain, this brand of AI is far removed from human ways of thought. If somebody is explaining how to visually identify a bottle of beer in a store that also stocks bottles of wine, juice, and water, that person would likely describe its distinguishing features in terms of height, diameter, shape, texture, color, and patterns. Some descriptors might include analogies such as “satin finish” or “orange-peel texture.” Every feature would be based on, and limited by, our human senses and perception. Yet that list wouldn’t include all the factors that our brains use to distinguish one object from another, because much of the process is subconscious.
If we used a human list of features as the basis of an algorithm for recognizing beer bottles, we’d likely get poor results. So instead we’d feed a DNN thousands and thousands of highly variable images of bottles, with metadata indicating whether each image does in fact show a beer bottle. Through a complicated series of training runs, the network can eventually determine, on its own, the relevant distinguishing features. Many similar experiments have shown that neural networks can identify features quite unlike those any person would come up with. And their lists of salient features, cryptic as they are, often enable superb performance.

A convolutional neural network (CNN) is a type of machine learning program that’s well-suited for image classification tasks—like spotting the early signs of cervical cancer. Here’s a simplified account of how a CNN works.
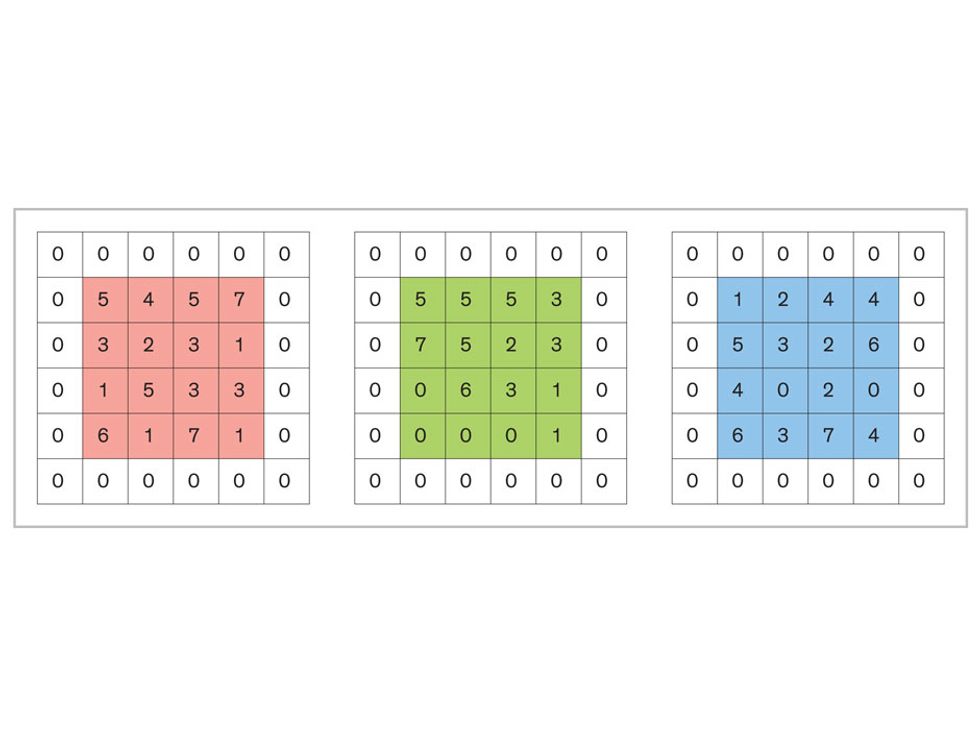
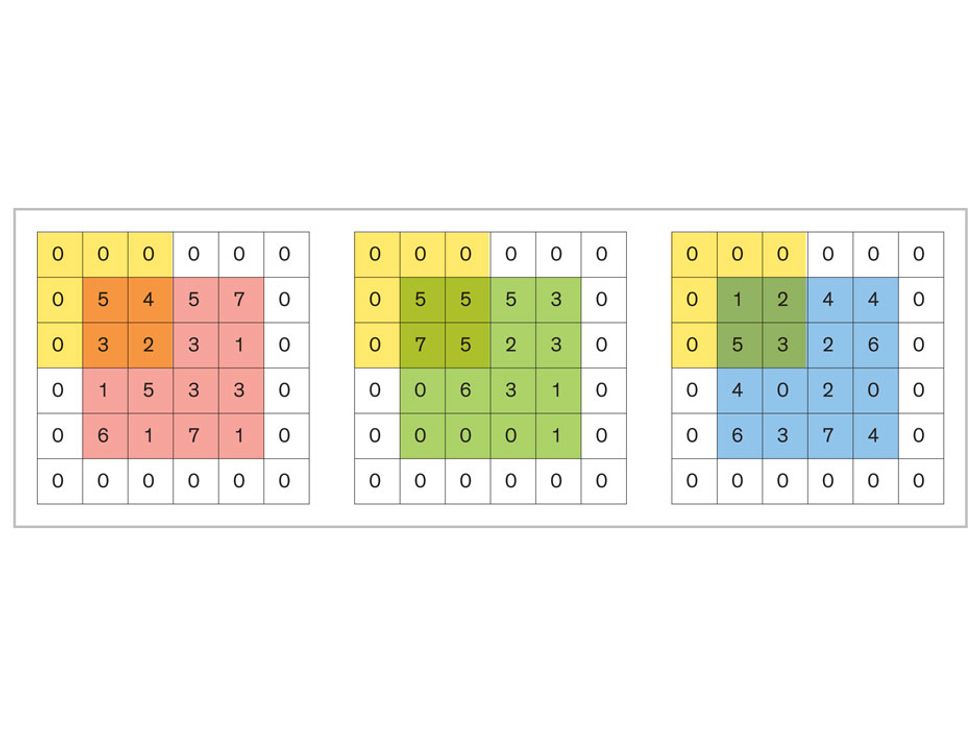
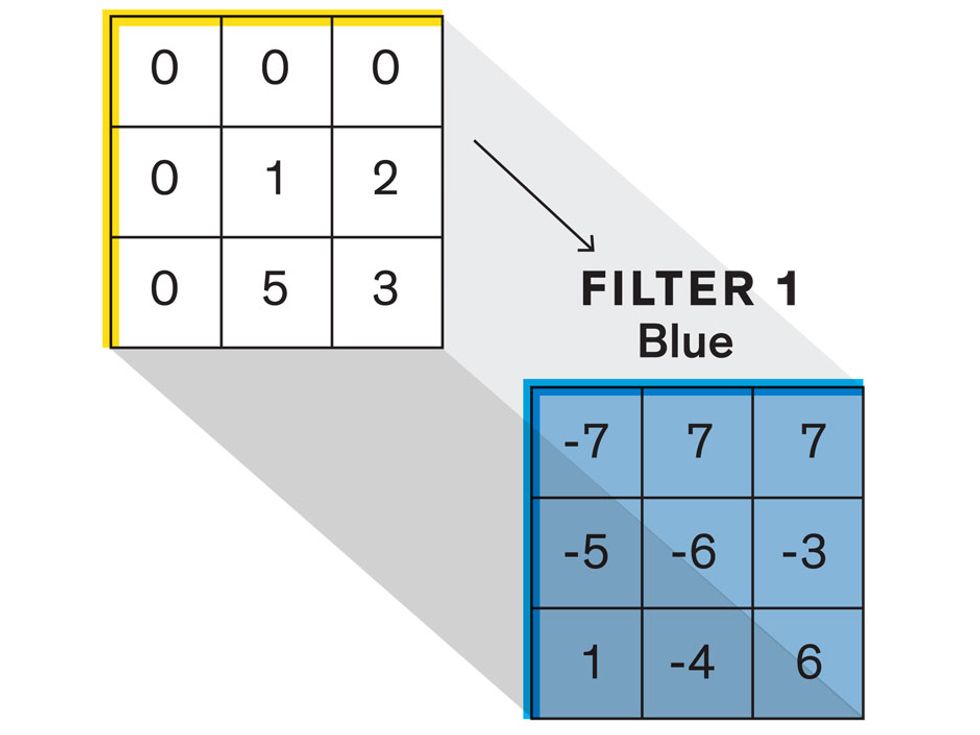
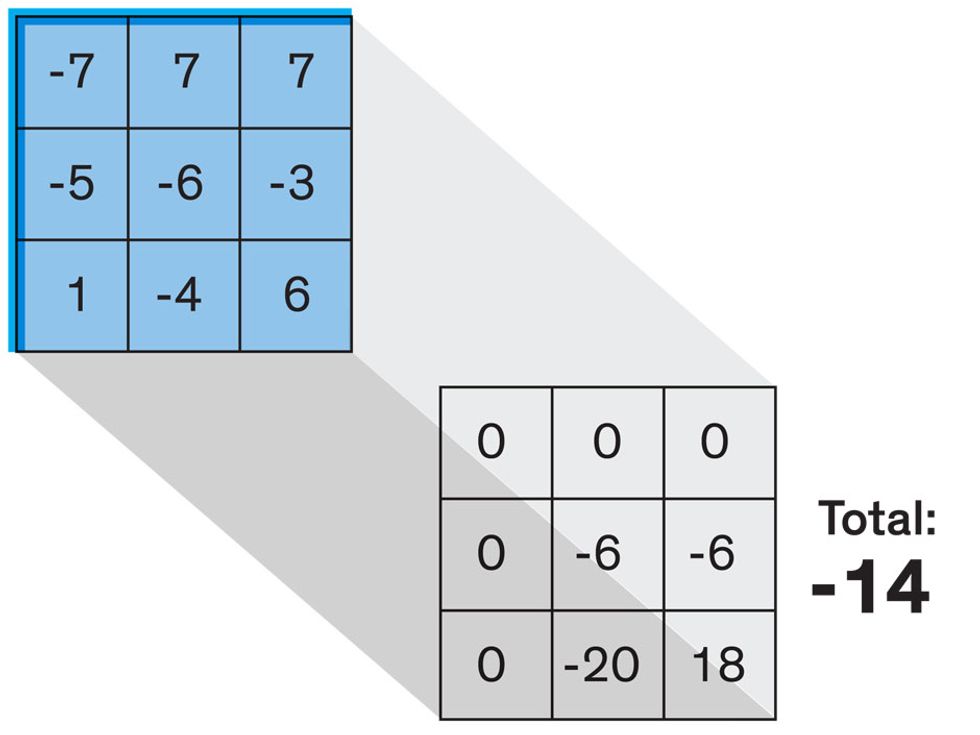
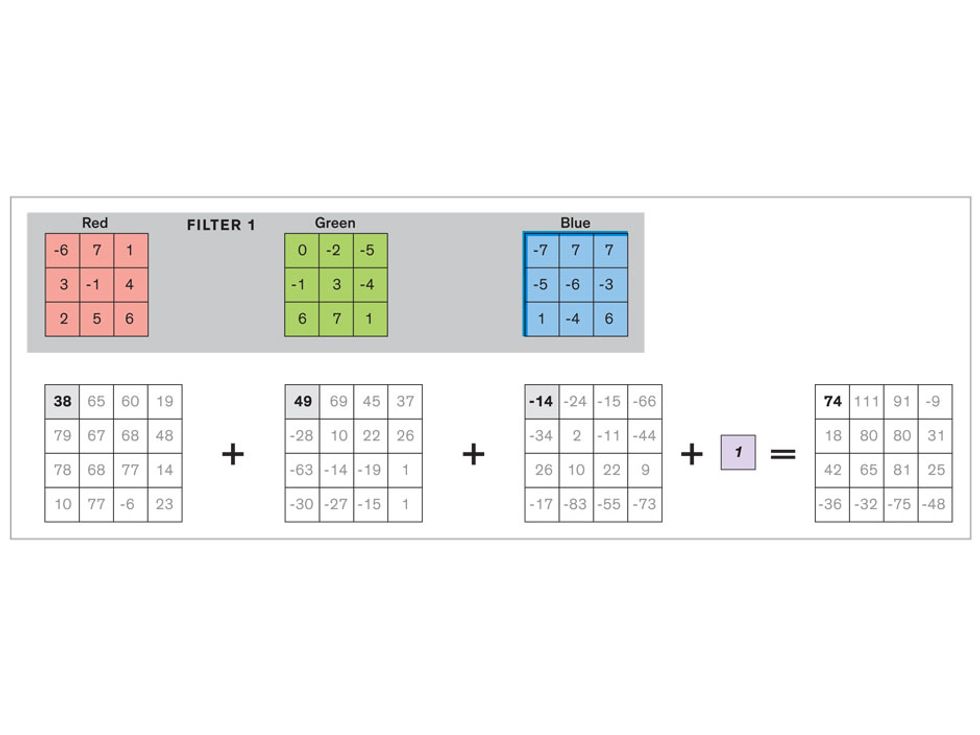
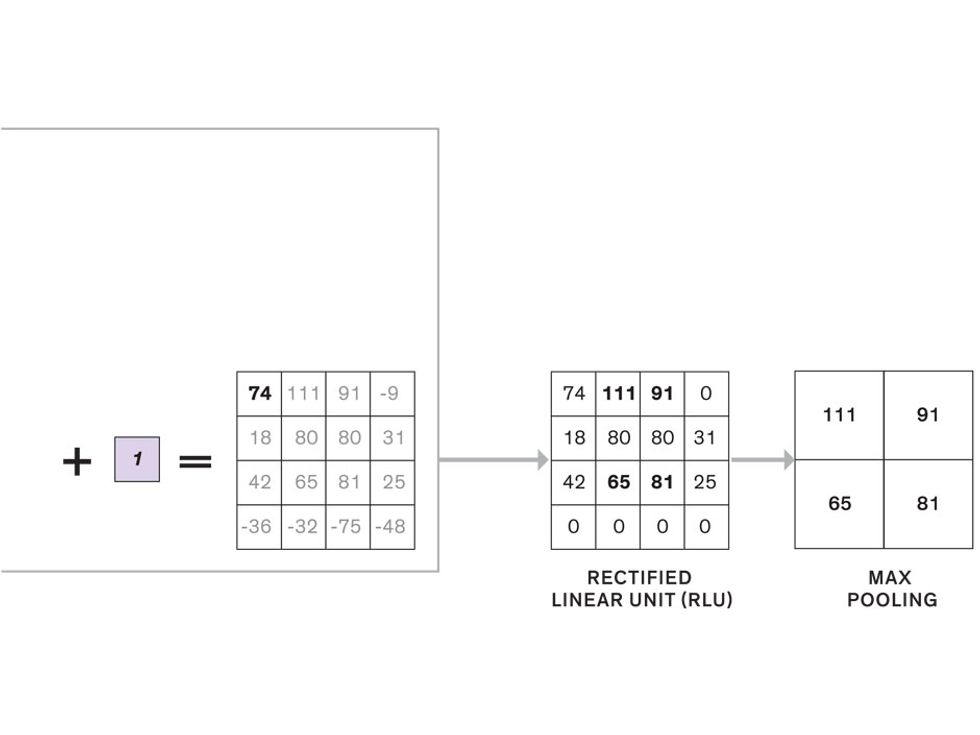
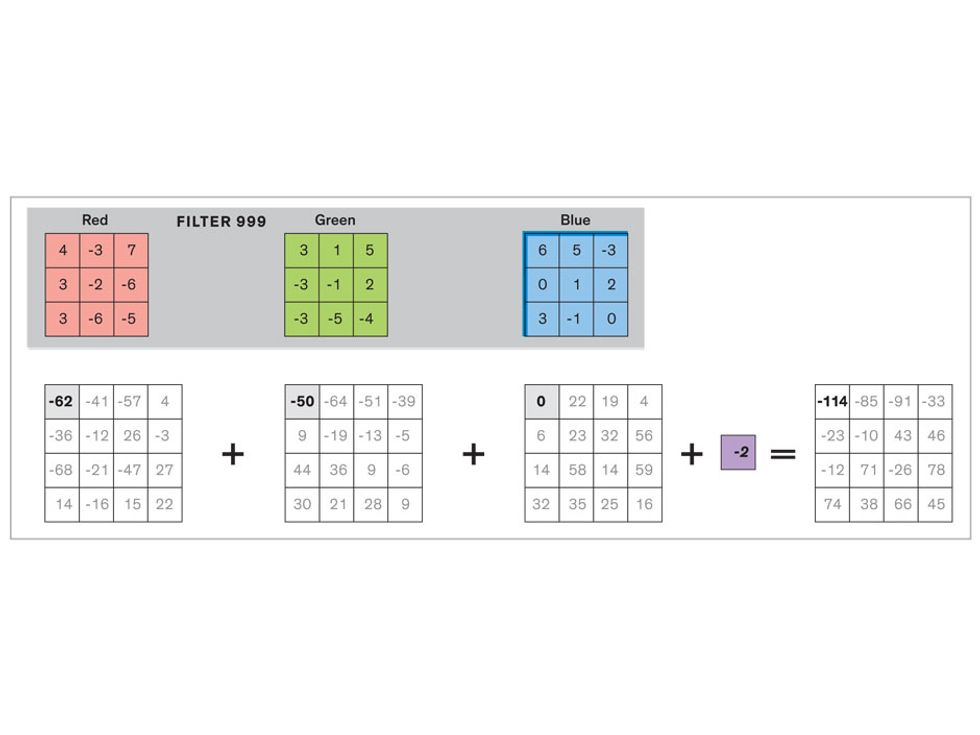
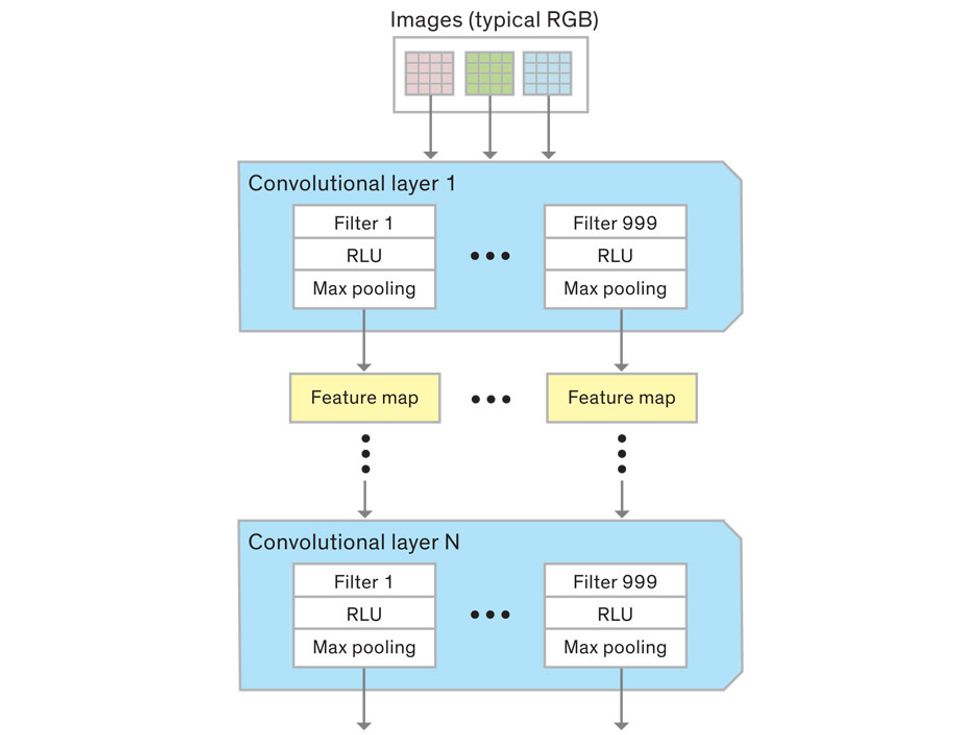
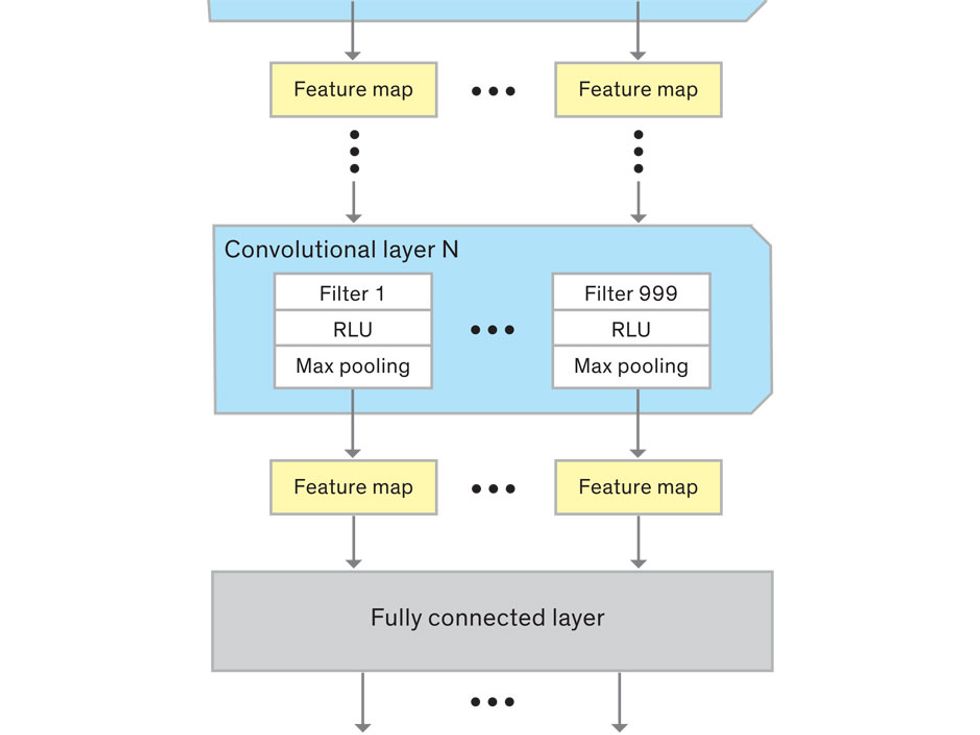
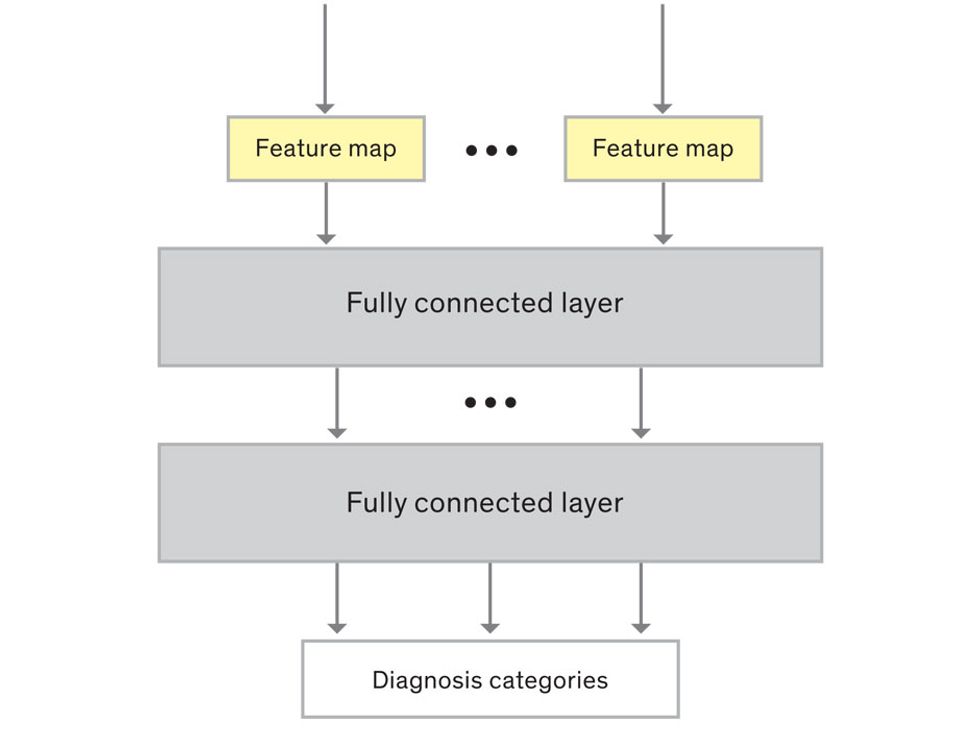
In tasks involving image processing and pattern recognition, the subtype of DNNs previously mentioned called convolutional neural networks (CNNs) are proving the most promising. This approach uses a few clever tricks to reduce the heavy computational task of making sense of an image.
Computer scientist Yann LeCun created some of the first CNNs in the 1980s at AT&T Bell Laboratories, using them in computer vision systems that could recognize handwriting, such as the zip codes on envelopes. (Today, LeCun is the director of AI research at Facebook.) But the potential of CNNs wasn’t really explored until 2012, when University of Toronto graduate student Alex Krizhevsky and his colleagues used a CNN to win an image recognition challenge that involved 1.4 million photos of objects in 1,000 different categories. Their AlexNet program had an error rate more than 50 percent lower than previous winners. It handily recognized barometers, barbershops, bubbles, baseball players, bullet trains, bolo ties, burritos, bath towels, and Boston terriers, to name just a few of the categories under the letter B. (Krizhevsky and several of his teammates now work at Google.)
Since that game-changing demonstration, CNNs have taken off. Enabled by the availability of relatively cheap high-performance computing, which is needed for training these networks, CNNs have been adopted for many applications involving images.
In the medical field, the possibilities are exciting. For example, Jürgen Schmidhuber of the Swiss AI Lab IDSIA recently took images of breast cancer cells from real pathology reports and used a CNN to identify dividing cells that indicate an aggressive tumor—a detection task that’s challenging even for trained experts. His demonstration was a proof of concept, but we’re now reaching the critical point when research projects can be turned into tools that assist in clinical care.
In a CNN, many layers of artificial neurons perform remarkably basic calculations and feed the results forward in a simplified way. The power of CNNs—and their advantage over other neural networks—comes from the clever arrangement of these simple steps, which keeps the computational load within reasonable bounds.
Each neuron in a CNN can be thought of as a filter that scans an image for one particular feature. To make sense of any image—whether the CNN is trying to distinguish between a beer bottle and a soda bottle, or between a healthy and a cancerous cervix—it may use thousands of filters arranged in multiple layers, which collectively perform billions of calculations.
The first layer of filters looks at the digital image on the pixel scale, taking in each pixel’s numerical values for its red, green, and blue channels. One filter may detect vertical lines, while another may look for a certain color. Every filter examines the image in small and manageable chunks, seeking its particular feature in each chunk, and then represents its findings as number values in a feature map. These uncomplicated maps are then fed forward, with each map being used as an input for the filters in the next layer. These next filters will respond to features that are slightly larger or more abstract, such as the edge of an object or the presence of a flesh tone.
 Making the Call: Kenyan nurses practice using the EVA Scope to differentiate between benign lesions and signs of cervical cancer.Photo: Emily Johnson
Making the Call: Kenyan nurses practice using the EVA Scope to differentiate between benign lesions and signs of cervical cancer.Photo: Emily Johnson
This routine continues, with each layer identifying increasingly complex forms or patterns. Finally, a layer sends its output to a “fully connected” layer that doesn’t do a chunk-style scan of the feature maps but instead looks at them in their entirety. Typical CNNs finish with a couple of fully connected layers that look at the big picture (which is really just a lot of number values) and determine how well it matches the CNN’s template for an object. That holistic view enables the final layer to declare: This is a beer bottle. Or, this is a healthy cervix. It can make this assessment even though human programmers never tell the network what filters to use—the AI has made those determinations itself during training.
We human programmers aren’t mere observers, however. We establish the CNN’s computing architecture by setting both the number of filters in each layer and the number of layers. We explore many combinations: Adding filters might make the CNN take note of more fine-grained details, or adding layers could cause a more gradual progression from raw image to abstract classification. We examine the results of each architecture, make some changes, and do another run. Equally important to the CNN’s success is the set of images we provide for training: The images must represent the range that will be encountered in the real world and must be correctly sorted into labeled categories. A bad image set will yield bad results.
To train our CNN for cervical cancer screening, we’re feeding in approximately 100,000 images of cervixes sorted into categories such as healthy tissue, benign inflammation, precancerous lesions, and suspected cancer. We’re aided here by a partnership with the U.S. National Cancer Institute, which has given us access to its databases of high-quality, annotated, anonymized images. We’re training our CNN with these “ideal” images before turning to the trickier images obtained from clinics.
We’re using a software program called Caffe, which was developed at the University of California, Berkeley, as the training framework for our CNN. We first define the CNN architecture, and then Caffe runs our image set through the CNN using one set of filters. After that, it checks to see how well its classification system performed. Caffe then adjusts the CNN filters to try to improve the system’s overall accuracy. It’s like a black box with millions of knobs being automatically turned: We understand some of the features it focuses on, like colors and lines, but many are completely inscrutable. Caffe keeps turning knobs until the CNN reaches some plateau of performance or until it becomes obvious that it’s a bad run. That’s when we humans step back in to try a new architecture.
Once our CNN seems proficient, we’ll challenge it to classify cervical images not used during its learning process. This is a crucial validation step, because CNNs can get great results when classifying familiar images but fail spectacularly when confronted with a new data set. When we get to this step later this year, we’ll use a subset of images from the National Cancer Institute that we’ve kept apart.
CNN training requires plenty of computational power. When Caffe is putting our CNN through a run, it performs nearly a trillion simple mathematical computations, which would take weeks or even months on a high-end multicore CPU machine. But doing the calculations on the graphics processing units (GPUs) used for high-end video games and simulations can drastically speed up this number crunching. At Global Good, we use two high-performance computer clusters that are stuffed with GPUs to run through these iterations using images stored on a massive array of disks. It takes about 72 hours to do a single training session. Still, in the world of CNNs, a three-day run is considered quick!
The final challenge will be bringing our well-trained system out into the field, to see whether it can make sense of images captured in a wide range of conditions. A health worker using MobileODT’s EVA Scope to conduct an exam employs a speculum and a light to view the cervix. Our AI will be trained to ignore the speculum and the light reflection from it. But it must also deal with variations that arise when you’re taking a photo with a mobile device, such as irregularities in lighting, alignment, steadiness, and focus. Our system must be trained with images from these in-the-field exams to make sense of such inconsistencies. When we begin our trials in Ethiopia later this year, we’ll assess our smart device’s performance by checking its diagnoses against medical experts’ assessments and pathology tests in the lab.
To make the technology practical for remote rural clinics, the smart EVA Scope won’t require connection to the cloud to evaluate images. The heavy computations take place during the training of a CNN, but once the system is configured it doesn’t require much processing power to evaluate an image. The EVA Scope will do that with an app on the smartphone to which it’s attached.
We’re already looking ahead to future generations of this technology. Currently, diagnostic tools based on machine learning are trained on a large initial data set prior to deployment, but they don’t learn while they’re being used in the field. Eventually, we hope to develop AI systems that can continue to improve their skills based on the cases and patients they encounter, adapting to changing conditions and improving their ability to make diagnoses. This adaptation wouldn’t require the heavy computational power that’s needed for basic training, since the CNN would be adding only a few images at a time to its data set. And if we can design AIs that are really good at making adjustments as they go, we can spend less time and energy on the initial training.
Our current effort may be just the beginning for machine-learning diagnostic tools. As many other medical exams rely on images such as X-rays and MRI scans, it’s easy to imagine using other smart tools to classify images, finding patterns and outliers. We can also use CNNs to detect rare objects that are tough to spot. For example, our team is now working on a program to diagnose malaria, which requires examining a blood sample under a microscope to find minute malaria parasites. For people with low parasite levels, that’s a challenge akin to finding a handful of marbles in a football field.
In many ways, machine learning is still in its infancy. A 3-year-old child has to look at only a few pictures of a cat before getting the concept, while a CNN has to look at millions. But in the medical field the comparison between humans and machines could shift in coming decades, as programs use features that are beyond our comprehension to scan medical images and draw conclusions. The machines may surpass doctors, but if they’re doing it in the service of humanity, we’ll take it.
About the Authors
Cary Champlin and David Bell both work for Intellectual Ventures Laboratory, in Bellevue, Wash. Champlin is a principal engineer there, and Bell is the portfolio lead on global health technology. Celina Schocken is CEO of Pink Ribbon Red Ribbon, a nonprofit based in Washington, D.C., which works to improve women’s health in the developing world.