
In the 1970 sci-fi thriller Colossus: The Forbin Project, a computer designed to control the United States’ nuclear weapons is switched on, and immediately it discovers the existence of a Soviet counterpart.
The two machines, Colossus and Guardian, trade equations, beginning with “1 + 1 = 2.” The math moves faster and faster, advancing through calculus and beyond until suddenly the blurry cascade of symbols stops. The two machines have become one, and it has mankind by the throat.
Hah, you say. Development work takes a lot longer than that.
Maybe not. Today DeepMind, a London-based subsidiary of Google, announced that it has developed a machine that plays the ancient Chinese game of Go much better than its predecessor, AlphaGo, which last year beat Lee Sedol, a world-class player, in Seoul.
The earlier program was trained for months on a massive database of master games and got plenty of pointers—training wheels, as it were—from its human creators. Then it improved further by playing countless games against itself. But the new one, called AlphaGo Zero, received no training wheels; it trained itself all the way from tyro to grandmaster.
In three days.
After a few more days of training, the new machine was pitted against the old one in games held at the standard tournament speed of 2 hours per player, per game. AlphaGo Zero won by 100 games to zero.
To understand the new system, we must first review last year’s version. It has three parts: a search algorithm, a Monte Carlo simulator, and two deep neural networks.
Search algorithms dictate the moves within computer chess programs. The algorithm begins by listing every possible move, then every possible rejoinder, and so on, generating a tree of analysis. Next, it uses a second algorithm to evaluate the final position on each branch of the tree. Finally, it works its way back to select the move that leads to the best outcome should the opponent also play the best moves. Search is of only limited value in Go, because it’s so hard to evaluate final positions, a problem explained inIEEE Spectrum 10 years ago by Feng Hsiung-Hsu, who programmed IBM’s Deep Blue, which defeated then-world chess champion Garry Kasparov.
Monte Carlo simulation instead generates great numbers of possible games to get an idea of how often a given move leads to good results. This is what financial planners do when they take the known statistical variance for stocks, bonds, and inflation and use it to generate far more alternative histories than the actual periods for which good records exist. Other Go programmers had already tried this method, with decent results, as described in Spectrum in 2014 by Jonathan Shaeffer, Martin Miller, and Akihiro Kishimoto.
Deep neural networks were applied to Go for the first time by DeepMind’s engineers, led by CEO Demis Hassabis and David Silver. On top of search and Monte Carlo, their original AlphaGo system used two networks, one trained to imitate the play of masters, as exemplified in a huge database of games, and another to evaluate positions. Then the program played millions of times against itself to improve beyond the level of mere human players.
DeepMind calls such self-training reinforcement learning, and AlphaGo Zero relied largely on this technique. The machine played itself repeatedly, looking only at the board and at the black and white stones that take their places, move by move, at the intersections of 19 vertical and 19 horizontal lines. And it used one neural network rather than two.
“After 72 hours, we evaluated AlphaGo Zero against the exact version...that defeated Lee Sedol, under the same 2-hour time controls and match conditions that were used in the man-machine match in Seoul,” write Silver, Hassabis and their coauthors today in Nature. “AlphaGo Zero used a single machine with 4 tensor processing units (TPUs), whereas AlphaGo Lee was distributed over many machines and used 48 TPUs. AlphaGo Zero defeated AlphaGo Lee by 100 games to 0.”
Don’t get the idea that this stuff is easy. The authors explain their work with a jungle of symbols reminiscent of the conversation between Guardian and Colossus. Here’s a sample:
“MCTS may be viewed as a self-play algorithm that, given neural
network parameters θ and a root position s, computes a vector of search
probabilities recommending moves to play, π = αθ(s), proportional to
the exponentiated visit count for each move, πa ∝ N(s, a)1/τ, where τ is
a temperature parameter.”
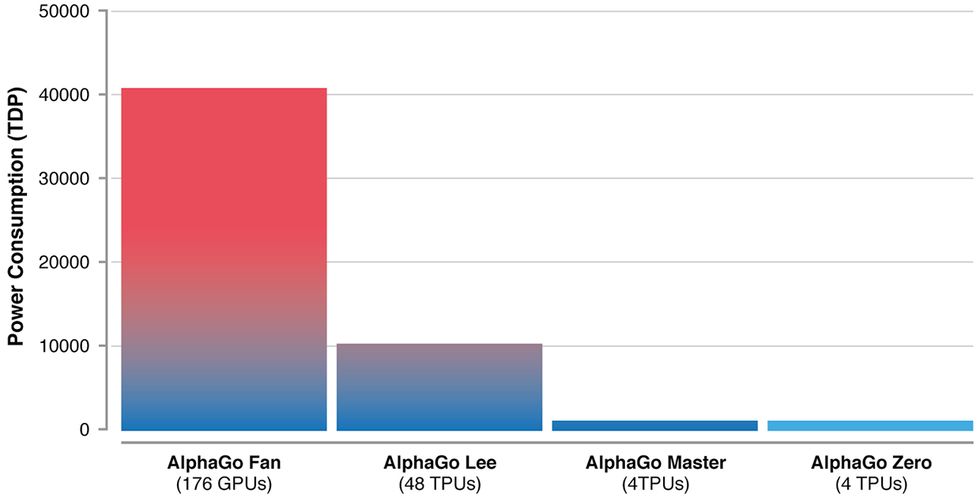 AlphaGo’s power consumption has decreased with each generation.Image: DeepMind
AlphaGo’s power consumption has decreased with each generation.Image: DeepMind
I looked it up: “Temperature” is a concept derived from statistical mechanics.
To a Go player, the result is a mixture of the familiar and the strange. In a commentary in Nature, Andy Okun and Andrew Jackson of the American Go Association write: “At each stage of the game, it seems to gain a bit here and lose a bit there, but somehow it ends up slightly ahead, as if by magic.”
And, the commentators add, the machine’s self-taught methods in the early and later parts of the game confirm the lore that grandmasters have accumulated over centuries of play: “But some of its middle-game judgements are truly mysterious.”
The DeepMind researchers discovered another bit of weirdness. When they had a neural network train itself to predict the moves of expert players, it did very well, though it took a bit longer to reach the standard of a system trained with human supervision. However, the self-trained network played better overall, suggesting “that AlphaGo Zero may be learning a strategy that is qualitatively different to human play.”
Different and better. Toward the end of Colossus: The Forbin Project, the computer says, “What I am began in Man’s mind, but I have progressed further than Man.”
But before we welcome our new overlords, a splash of cold water may be in order. And there is no better supplier of such coolant for AI hype than Rodney Brooks, who recently wrote for Spectrum on the limitations of self-driving cars.
In his keynote at the IEEE TechEthics Conference, held on Friday in Washington, D.C., Brooks said he’d asked the creators of the original AlphaGo how it would have fared against Lee Sedol if, at the last minute, the board had been enlarged by 10 lines, to 29 x 29. They told him the machine couldn’t have managed even if the board had been shrunk by a single line, to 18 x 18. That’s how specialized these deep neural networks are.
Brooks showed the audience a photo that Google’s AI system had labeled as a scene of people playing Frisbee. “If a person had done this,” Brooks said, “we’d assume that he’d know a lot of other things about Frisbees—that he could tell us whether a three-month-old can play Frisbee, or whether you can eat a Frisbee. Google’s AI can’t!”
AlphaGo Zero can’t tell us that Go is harder than checkers, that it involves occupying territory rather than checkmating the opponent’s king, or that it is a game. It can’t tell us anything at all.
But no human can stand against it.


