
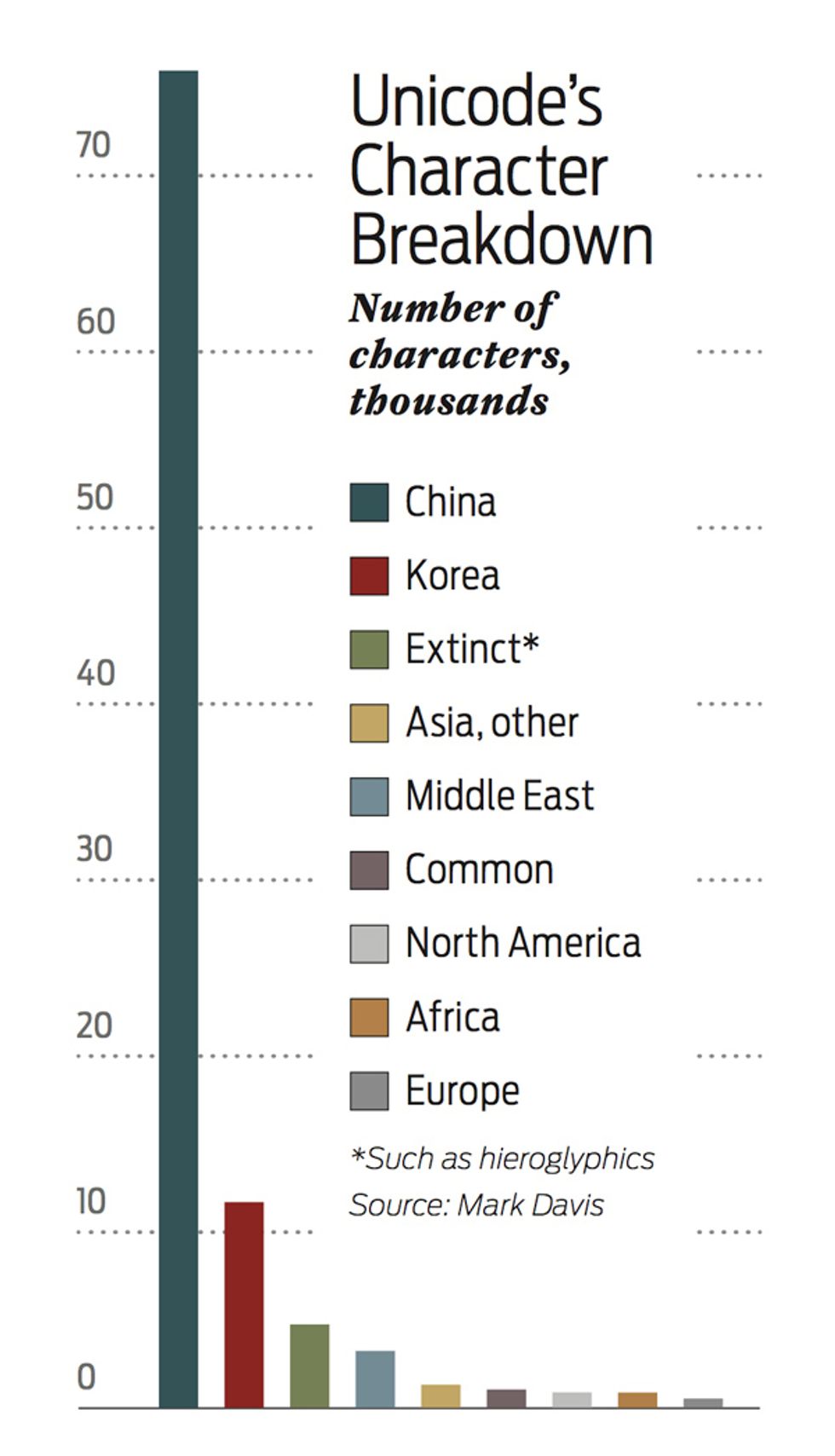
A universal human language, though appealing in theory, has never gained much traction in real life. French, Chinese, and Arabic have served as lingua francas at one time or another, but almost no one is fluent in Esperanto, the global linguistic mash-up.
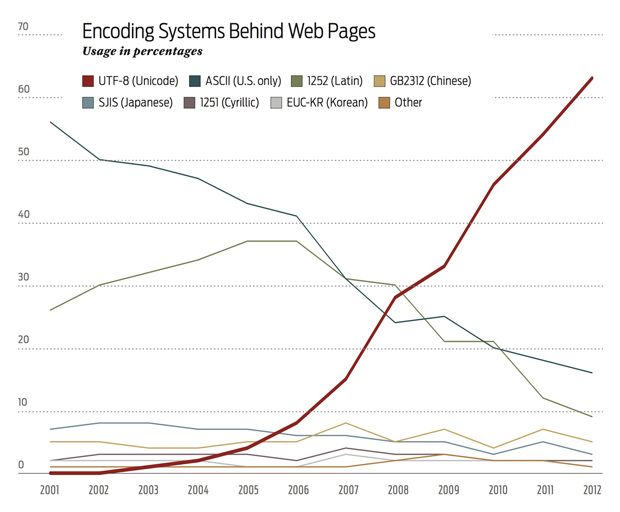
In computing, on the other hand, a universal way of encoding languages—that is, translating characters from any language into ones and zeros and vice versa—has been steadily growing since 2006. Unicode is now the encoding system of choice for over 60 percent of Web pages on the Internet, according to an analysis by Google.
The advantage of Unicode is that if everyone adopted it, it would eradicate the problem of mojibake, Japanese for “character transformation.” Mojibake is the jumble that results when characters are encoded in one system but decoded in another. For example, ASCII, which predates Unicode but is now effectively a subset of it, cannot encode a curly apostrophe—but Unicode can. So when the contraction “that’s” is written in Unicode and interpreted in ASCII, it comes out as “that’s.”
Though Unicode has been around since 1991, the year the Web was born, it took a long time for the encoding system to become popular. Mark Davis, one of Unicode’s creators, attributes the lag to two things: Most pages were produced in a single language in the early days of the Web, and the available development software tended to rely on different encoding systems, such as ASCII. But after 2006, “people were paying more and more attention to internationalization,” says Davis, who is now the senior internationalization architect at Google. “And people started getting the tools to produce their websites in Unicode.”


