The Conversation (0)

Illustration: John Hersey
“On tap at the brewpub. A nice dark red color with a nice head that left a lot of lace on the glass. Aroma is of raspberries and chocolate. Not much depth to speak of despite consisting of raspberries. The bourbon is pretty subtle as well. I really don’t know that find a flavor this beer tastes like. I would prefer a little more carbonization to come through. It’s pretty drinkable, but I wouldn’t mind if this beer was available.”
Besides the overpowering bouquet of raspberries in this guy’s beer, this review is remarkable for another reason. It was produced by a computer program instructed to hallucinate a review for a “fruit/vegetable beer.” Using a powerful artificial-intelligence tool called a recurrent neural network, the software that produced this passage isn’t even programmed to know what words are, much less to obey the rules of English syntax. Yet, by mining the patterns in reviews from the barflies at BeerAdvocate.com, the program learns how to generate similarly coherent (or incoherent) reviews.
The neural network learns proper nouns like “Coors Light” and beer jargon like “lacing” and “snifter.” It learns to spell and to misspell, and to ramble just the right amount. Most important, the neural network generates reviews that are contextually relevant. For example, you can say, “Give me a 5-star review of a Russian imperial stout,” and the software will oblige. It knows to describe India pale ales as “hoppy,” stouts as “chocolatey,” and American lagers as “watery.” The neural network also learns more colorful words for lagers that we can’t put in print.
This particular neural network can also run in reverse, taking any review and recognizing the sentiment (star rating) and subject (type of beer). This work, done by one of us (Lipton) in collaboration with his colleagues Sharad Vikram and Julian McAuley at the University of California, San Diego, is part of a growing body of research demonstrating the language-processing capabilities of recurrent networks. Other related feats include captioning images, translating foreign languages, and even answering e-mail messages. It might make you wonder whether computers are finally able to think.
That’s a goal computer scientists have pursued for a long time. Indeed, since the earliest days of this field, they have dreamed of developing truly intelligent machines. In his 1950 paper, “Computing Machinery and Intelligence,” Alan Turing imagined conversing with such a computer via a teleprinter. Envisioning what has since become known as a Turing test, he proposed that if the computer could imitate a person so convincingly as to fool a human judge, you could reasonably deem it to be intelligent.
The very year that Turing’s paper went to print, Gnome Press published I, Robot, a collection of Isaac Asimov’s short stories about intelligent humanoids. Asimov’s tales, written before the phrase “artificial intelligence” existed, feature cunning robots engaging in conversations, piloting vehicles, and even helping to govern society.
And yet, for most of the last 65 years, AI’s successes have resembled neither Turing’s conversationalists nor Asimov’s humanoids. After alternating periods of overenthusiasm and subsequent retrenchment, modern AI research has largely split into two camps. On one side, theorists work on the fundamental mathematical and statistical problems related to algorithms that learn. On the other side, more practically oriented researchers apply machine learning to various real-world tasks, guided more by experimentation than by mathematical theory.
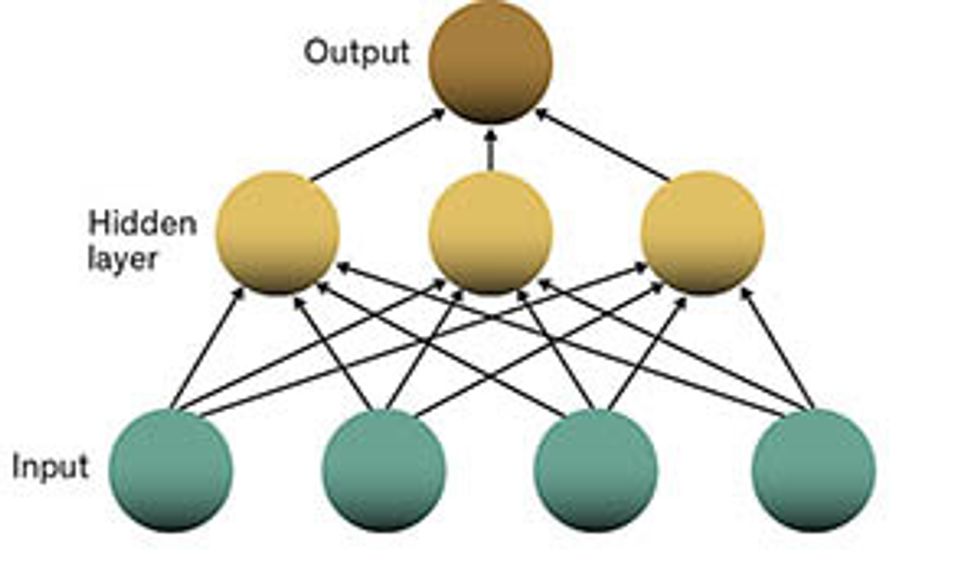
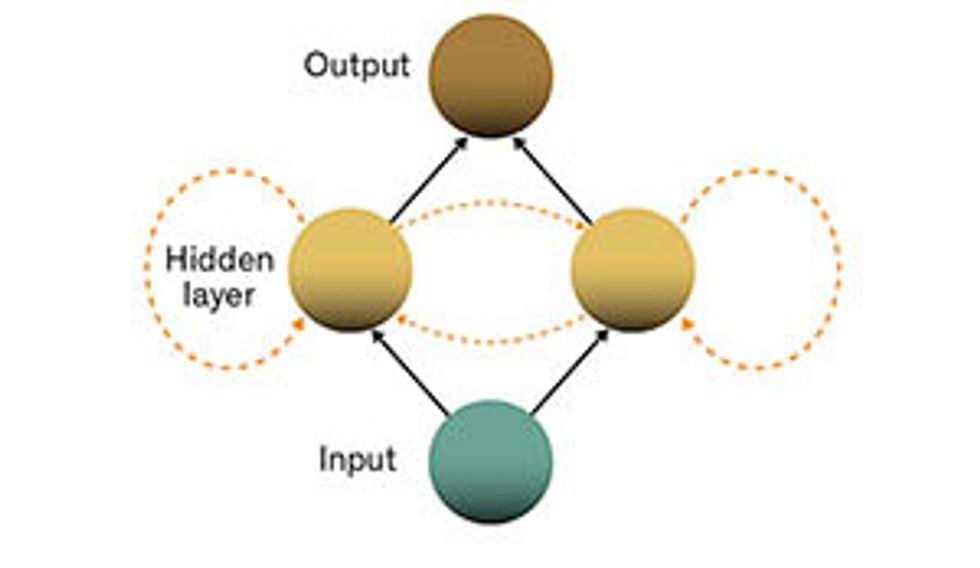
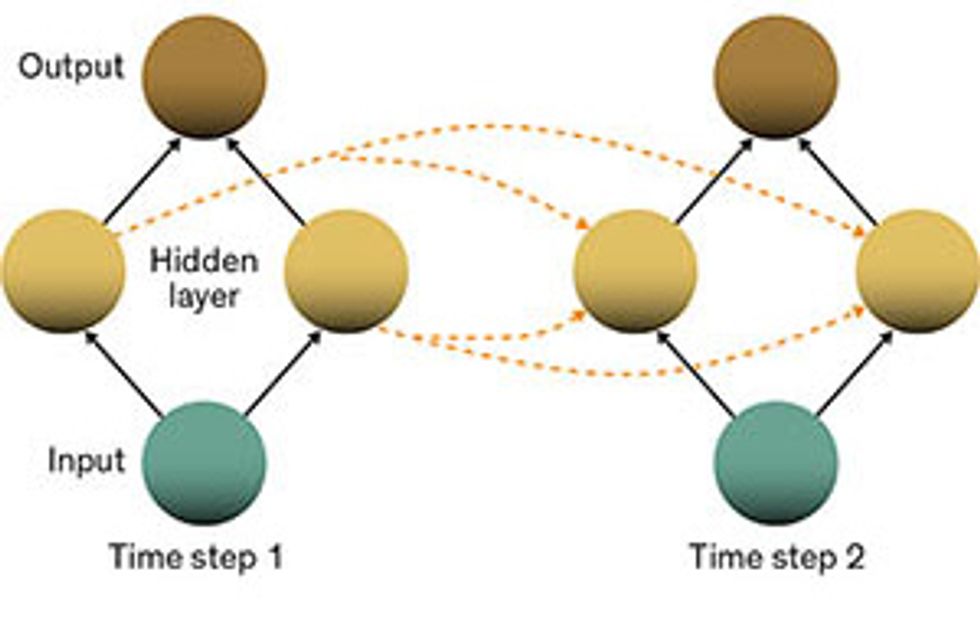 Bottom’s Up: A standard feed-forward network has the input at the bottom. The base layer feeds into a hidden layer, which in turn feeds into the output. Loop the Loop: A recurrent neural network includes connections between neurons in the hidden layer (yellow arrows), some of which feed back on themselves. Time After Time: The added connections in the hidden layer link one time step with the next, which is seen more clearly when the network is “unfolded” in time.Illustrations: Zachary C. Lipton/University of California, San Diego
Bottom’s Up: A standard feed-forward network has the input at the bottom. The base layer feeds into a hidden layer, which in turn feeds into the output. Loop the Loop: A recurrent neural network includes connections between neurons in the hidden layer (yellow arrows), some of which feed back on themselves. Time After Time: The added connections in the hidden layer link one time step with the next, which is seen more clearly when the network is “unfolded” in time.Illustrations: Zachary C. Lipton/University of California, San Diego
Until recently, both sides of this divide focused on simple prediction problems. For example: Is an e-mail message spam or not spam? Or: What’s the probability that a loan will default? A cynic might say that we dreamed of creating humanlike intelligence and got spam filters instead. However, breakthroughs in neural-network research have revolutionized computer vision and natural-language processing, rekindling the imaginations of the public, researchers, and industry.
The modern incarnation of neural networks, commonly termed “deep learning,” has also widened the gap between theory and practice. That’s because, until recently, machine learning was dominated by methods with well-understood theoretical properties, whereas neural-network research relies more on experimentation.
As high-quality data and computing resources have grown, the pace of that experimentation has similarly taken off. Of course, not everyone is thrilled by the success of deep learning. It’s somehow unsatisfying that the methods that perform best might be those least amenable to theoretical understanding. Nevertheless, the capabilities of recurrent neural networks are undeniable and potentially open the door to the kinds of deeply interactive systems people have hoped for—or feared—for generations.
You might think that the study of artificial neural networks requires a sophisticated understanding of neuroscience. But you’d be wrong. Most press coverage overstates the connection between real brains and artificial neural nets. Biology has inspired much foundational work in computer science. But truthfully, most deep-learning researchers, ourselves included, actually know little about the brain.
So here’s how neural networks actually work. Neural networks consist of a large number of artificial neurons, building blocks that are analogous to biological neurons. Neurons, as you might recall from high school biology class, are cells that fire off electrical signals or refrain from doing so depending on signals received from the other neurons attached to them. In the brain, a neuron connects to other neurons along structures called synapses. Through such connections, one neuron’s firing can either stimulate or inhibit the firing of others, giving rise to complex behavior. That’s about all the brain science you’ll need to know to get going with deep learning.
Like biological neurons, an artificial neural network’s simulated neurons work together. To each connection between one artificial neuron and another, we assign a value, called a weight, that represents the strength of the linkage. A positive weight could be thought of as an excitatory connection, while a negative weight could be thought of as inhibitory. To determine the intensity of an artificial neuron’s firing or, more properly, its activation, we calculate a weighted sum of the activations of all the neurons that feed into it. We then run this sum through an aptly named activation function, which outputs the desired activation. This value in turn contributes to the weighted sums for calculating other neurons’ activations.
So you might wonder: Which neuron’s activation should be calculated first? In a densely connected network, it’s not clear. Because each neuron’s activation can depend on every other neuron’s activation, changing the order in which we process them can produce radically different outcomes. To dodge this problem entirely and to simplify the computations, we typically arrange the neurons in layers, with each neuron in a layer connected to the neurons in the layer above, making for many more connections than neurons. But these connections go only from lower to upper, meaning that the output of a lower layer influences the one above, but not vice versa.
For obvious reasons, we call this a feed-forward architecture. To provide input to this kind of neural network, we simply assign activations to the neurons of the lowest layer. Each value could represent, for example, the brightness of one pixel in an image.
We calculate the activations in each higher layer successively based on input from the layer below. The ultimate output of the network—say, a categorization of the input image as depicting a cat, dog, or person—is read from the activations of the artificial neurons in the very top layer. The layers between input and output are called hidden layers.
Writing a program to produce outputs from inputs in this way might seem awfully easy—and it is. The hard part is training your neural network to produce something useful, which is to say, tinkering with the (perhaps millions of) weights corresponding to the connections between the artificial neurons.
Training networks with many hidden layers seemed computationally infeasible.
Training requires a large set of inputs for which the correct outputs are already known. You also need some way to measure how much the generated output deviates from the desired output. In machine learning parlance, this is called a loss function. Once you have those things, you present randomly selected training examples to the network. Then you update the weights to reduce the value of the loss function. That is, you repeatedly adjust the connection weights a small amount, bringing the output of the network incrementally closer to the ground truth.
While determining the correct updates to each of the weights can be tricky, we can calculate them efficiently with a well-known technique called backpropagation, which was developed roughly 30 years by David Rumelhart, Geoff Hinton, and Ronald Williams. When the loss function has a convenient mathematical property called convexity, this procedure is guaranteed to find the optimal solution. Unfortunately, neural networks are nonconvex and offer no such guarantee. Computer scientists apply this strategy anyway, often successfully.
Early on, computer scientists built neural networks with just three tiers: the input layer, a single hidden layer, and the output layer. Training networks with many hidden layers (known as deep nets) seemed computationally infeasible. This perception has been overturned, thanks in part to the power of graphics processing units (GPUs). It’s now common to train networks with many hidden layers in just hours or days.
Once you’ve trained a neural network, it can finally do useful things. Maybe you’ve trained it to categorize images or to gauge the likelihood that an applicant for a loan will default. Or perhaps you have it tuned to identify spam e-mails. These are impressive capabilities, to be sure, but they are limited by the amnesia of feed-forward neural networks. Such networks have absolutely no memory. Each prediction starts afresh, as if it were the only prediction the network ever made. But for many real-world tasks, inputs consist of sequences of contextually related data—say, a set of consecutive video frames. To determine what is happening at any frame in a video, it’s clearly advantageous to exploit the information provided by the preceding frames. Similarly, it’s hard to make sense of a single word in a sentence without the context provided by the surrounding words.
Recurrent neural networks deftly handle this problem by adding another set of connections between the artificial neurons. These links allow the activations from the neurons in a hidden layer to feed back into themselves at the next step in the sequence. Simply put, at every step, a hidden layer receives both activation from the layer below it and also its own activation from the previous step in the sequence. This property gives recurrent neural networks a kind of memory.
Let’s walk through things slowly as the network processes a sequence of inputs, one step at a time. The first input (at step 1) influences the activations of the hidden layers of the network and therefore affects the output of the network. Next, the network processes the second input, again influencing its hidden layers. At step 2, however, the hidden layers also receive activation flowing across time from the corresponding hidden layers from step 1. Computation continues in this fashion for the length of the sequence. Thus the very first input can affect the very last output, as the signal bounces around the hidden layers.
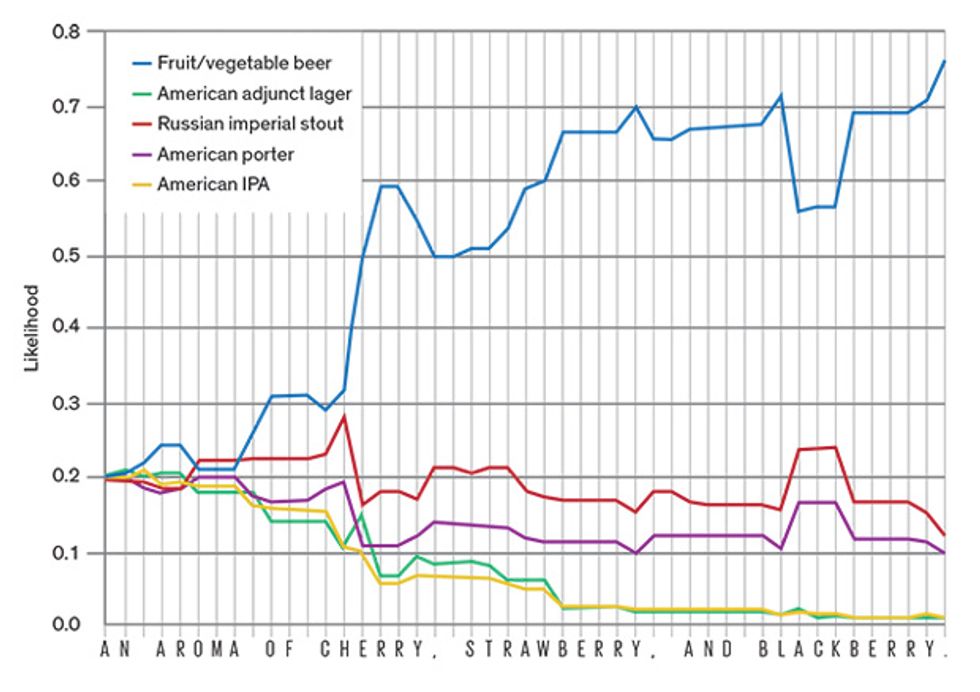 One By One: A recurrent neural network is used here to classify the subject of a beer review, tackling that task one character at a time in sequence. The likelihood that the beer being described belongs to one of the five possible categories shifts with each new character presented to the network.
One By One: A recurrent neural network is used here to classify the subject of a beer review, tackling that task one character at a time in sequence. The likelihood that the beer being described belongs to one of the five possible categories shifts with each new character presented to the network.
Computer scientists have known for decades that recurrent neural networks are powerful tools, capable of performing any well-defined computational procedure. But that’s a little like saying that the C programming language is a powerful tool, capable of performing any well-defined computational procedure. It’s true, but there’s a huge gap between knowing that your tool can in theory be used to write some desired program and knowing exactly how to construct it.
Working out the correct architecture for a recurrent network and training it to learn the best values for all the weights are hard problems. As with all neural networks, there’s no mathematical guarantee that the training procedure will ever find the best set of weights. Worse yet, calculations to determine the weight updates can easily become unstable with recurrent nets. This can stall the learning process, even blowing up the network when the magnitude of the update is so large that it wipes out all that the model has learned.
Fortunately, over the years computer scientists have overcome many of these difficulties in practice, and recurrent neural networks are proving exceptionally powerful. One particular variety, called the Long Short-Term Memory model, developed in 1997 by Sepp Hochreiter and Jürgen Schmidhuber, has seen the most success. It replaces simple artificial neurons with specialized structures called memory cells. We won’t go too far into the weeds describing memory cells here, but the basic idea is to provide the network with memory that persists longer than the immediately forgotten activations of simple artificial neurons. Memory cells give the network a form of medium-term memory, in contrast to the ephemeral activations of a feed-forward net or the long-term knowledge recorded in the settings of the weights.
One killer application for recurrent nets is language translation. Here, the training data consists of pairs of sentences, one in the source language and one in the target language. Amazingly enough, the sentences don’t need to be the same length or share the same grammatical construction.
What’s My Line
A recurrent neural network developed by Jeff Donahue of the University of California, Berkeley, and others wrote these image captions. The computer-generated descriptions are remarkably accurate (with some perplexing exceptions).





 A baseball game in progress. A brown bear standing on top of a lush green field. A woman lying on a bed in a bedroom. A person holding a cell phone in their hand. A close up of a person brushing his teeth. A black and white cat is sitting on a chair.Photos: University of California, Berkeley (6)
A baseball game in progress. A brown bear standing on top of a lush green field. A woman lying on a bed in a bedroom. A person holding a cell phone in their hand. A close up of a person brushing his teeth. A black and white cat is sitting on a chair.Photos: University of California, Berkeley (6)
In one such approach [pdf], by researchers Ilya Sutskever, Oriol Vinyals, and Quoc V. Le, the source sentence is first passed as input, one word at a time. Then, the recurrent network generates a translation, also one word at a time. This program matched the accuracy of many state-of-the-art machine-translation programs, despite lacking any hard-coded knowledge of either language. Other impressive examples demonstrating what can be done with such networks include recognizing and even generating handwriting.
In our own research, we recently showed that recurrent neural networks can recognize many medical conditions. In collaboration with David Kale of the University of Southern California and Randall Wetzell of Children’s Hospital Los Angeles, we devised a recurrent neural network that could make diagnoses after processing sequences of observations taken in the hospital’s pediatric intensive-care unit. The sequences consisted of 13 frequently but irregularly sampled clinical measurements, including heart rate, blood pressure, blood glucose levels, and measures of respiratory function. Our objective was to determine which of 128 common diagnoses applied to each patient.
After training the network, we evaluated the model by presenting it with a new set of patient data. The network proved able to recognize diverse conditions such as brain cancer, status asthmaticus (unrelenting asthma attacks), and diabetic ketoacidosis (a serious complication of diabetes where the body produces excess blood acids) with remarkable accuracy. Surprisingly, it could also reliably recognize scoliosis (abnormal curvature of the spine), possibly because scoliosis frequently produces respiratory symptoms.
The promising results from our medical application demonstrate the power of recurrent neural networks to capture the meaningful signal in sequential data. But for other applications, such as generating beer reviews, image captions, or sentence translations, evaluation can be difficult. It’s hard to say objectively in these cases what constitutes good performance, because the ground truth that you use for the correct answer may be only one of many reasonable alternatives.
Computer scientists have come up with various metrics for these circumstances, particularly to evaluate translation systems. But these metrics are not quite as satisfying as simple measures, like accuracy, which work for straightforward prediction tasks. In many cases, though, the true measure of success is whether someone inspecting the network’s output might mistake it for human-generated text. The most impressive image-captioning research papers tend to contain eye-popping examples of what the neural net can do. Success in this context really means getting someone to declare, “There’s no way a computer wrote that!”
In this sense, the computer-science community is evaluating recurrent neural networks via a kind of Turing test. We try to teach a computer to act intelligently by training it to imitate what people produce when faced with the same task. Then we evaluate our thinking machine by seeing whether a human judge can distinguish between its output and what a human being might come up with.
While the very fact that we’ve come this far is exciting, this approach may have some fundamental limitations. For instance, it’s unclear how such a system could ever outstrip the capabilities of the people who provide the training data. Teaching a machine to learn through imitation might never produce more intelligence than was present collectively in those people.
One promising way forward might be an approach called reinforcement learning. Here, the computer explores the possible actions it can take, guided only by some sort of reward signal. Recently, researchers at Google DeepMind combined reinforcement learning with feed-forward neural networks to create a system that can beat human players at 31 different video games. The system never got to imitate human gamers. Instead it learned to play games by trial and error, using its score in the video game as a reward signal.
We expect reinforcement learning to rise in prominence as computers become more powerful and as imitation-based learning approaches its limits. And already, some pioneering work is combining recurrent neural networks with reinforcement learning.
As research at this intersection of approaches develops, we might see computers that not only imitate our abilities but eclipse them.
This article originally appeared in print as “Playing the Imitation Game With Deep Learning.”
About the Authors
Zachary C. Lipton studies computer science at the University of California, San Diego, where he works closely with coauthor Charles Elkan, who is on the UCSD faculty. Lipton didn’t have a computer science background when he started grad school. He was a jazz saxophonist in New York City. In 2012, he moved to California to join a health-tech startup and later enrolled at UCSD to study machine learning.


