
 Photo: Dan Saelinger; Prop Stylist: Dominique Baynes
Photo: Dan Saelinger; Prop Stylist: Dominique Baynes
In July 1993, The New Yorker published a cartoon by Peter Steiner that depicted a Labrador retriever sitting on a chair in front of a computer, paw on the keyboard, as he turns to his beagle companion and says, “On the Internet, nobody knows you’re a dog.” Two decades later, interested parties not only know you’re a dog, they also have a pretty good idea of the color of your fur, how often you visit the vet, and what your favorite doggy treat is.
How do they get all that information? In a nutshell: Online advertisers collaborate with websites to gather your browsing data, eventually building up a detailed profile of your interests and activities. These browsing profiles can be so specific that they allow advertisers to target populations as narrow as mothers with teenage children or people who require allergy-relief products. When this tracking of our browsing habits is combined with our self-revelations on social media, merchants’ records of our off-line purchases, and logs of our physical whereabouts derived from our mobile phones, the information that commercial organizations, much less government snoops, can compile about us becomes shockingly revealing.
Here we examine the history of such tracking on the Web, paying particular attention to a recent phenomenon called fingerprinting, which enables companies to spy on people even when they configure their browsers to avoid being tracked.
The earliest approach to online tracking made use of cookies, a feature added to the pioneering Web browser Netscape Navigator a little over a year after Steiner’s cartoon hit newsstands. Other browsers eventually followed suit.
Cookies are small pieces of text that websites cause the user’s browser to store. They are then made available to the website during subsequent visits, allowing those sites to recognize returning customers or to keep track of the state of a given session, such as the items placed in an online shopping cart. Cookies also enable sites to remember that users are logged in, freeing them of the need to repeatedly provide their user names and passwords for each protected page they access.
So you see, cookies can be very helpful. Without them, each interaction with a website would take place in a vacuum, with no way to keep tabs on who a particular user is or what information he or she has already provided. The problem came when companies began following a trail of cookie crumbs to track users’ visits to websites other than their own.
How they do that is best explained through an example. Suppose a user directs her browser to a travel website—let’s call it Travel-Nice-Places.com—that displays an advertising banner at the top of the page. The source of that banner ad is probably not Travel-Nice-Places.com itself. It’s more likely located on the Web servers of a different company, which we’ll call AdMiddleman.com. As part of the process of rendering the page at Travel-Nice-Places.com, the user’s browser will fetch the banner ad from AdMiddleman.com.
Here’s where things get sneaky. The Web server of AdMiddleman.com sends the requested banner ad, but it also uses this opportunity to quietly set a third-party cookie on the user’s browser. Later, when that same user visits an entirely different website showing another ad from AdMiddleman.com, this ad supplier examines its previously set cookie, recognizes the user, and over time is able to build a profile of that user’s browsing habits.
You might ask: If this brings me more relevant online advertisements, what’s the harm? True, online tracking could, in principle, help deliver ads you might actually appreciate. But more often than not, the advertisers’ algorithms aren’t smart enough to do that. Worse, information about your Web browsing habits can be used in troubling ways. A car dealer you approach online and then visit in the flesh, for example, could end up knowing all about your investigations, not only of its inventory but of all the other car-related websites you’ve been checking out. No wonder such tracking has garnered a reputation for being creepy.
Not long after the use of third-party tracking cookies became common, various media outlets and privacy organizations began questioning the practice. And over the years, people have increasingly come to appreciate that the set of websites they visit reveals an enormous amount about themselves: their gender and age, their political leanings, their medical conditions, and more. The possession of such knowledge by online advertising networks, or indeed by any company or government agency that purchases it from those networks, comes with potentially dire consequences for personal privacy—especially given that users have no control of this very opaque process of data collection.
It should come as no surprise that some of the early news articles about advertisers’ use of cookies had headlines announcing “the death of privacy” and made allusions to George Orwell’s all-seeing Big Brother. Even the programmers and engineers involved in the development of technical standards got an earful.
In particular, in 1997 a coalition of privacy organizations wrote an open memo to the Internet Engineering Task Force (sending copies to the leading browser developers) that expressed their support for the first cookie standard, RFC 2109, which stated that third-party cookies should be blocked to “prevent possible security or privacy violations.” But advertising companies pushed back harder. And in the end, neither of the two mainstream browsers of that era, Netscape Navigator and Internet Explorer, followed the specification, both allowing third-party cookies.
The winds began to shift in 2005, though, when browser developers started adding a “private browsing” mode to their products. These give users the option of visiting websites without letting those sites leave long-term cookies. Independent developers, too, started producing privacy-preserving extensions that users could add to their browsers.
Today, the most popular extension to Mozilla’s Firefox browser is AdBlock Plus, which rejects both ads and third-party cookies used for tracking. And recently developed tools like Ghostery and Mozilla’s Lightbeam reveal the number of trackers on each website and show how these trackers collaborate between seemingly unrelated sites. Finally, recent studies have shown that a large percentage of people delete their browser cookies on a regular basis, a fact that points to their having at least some understanding of how cookies can compromise privacy online.
But when people started deleting their cookies, the companies involved in tracking didn’t just roll over. They responded by developing new ways of sniffing out users’ identities. Most had one thing in common: They tried to bury the same tracking information found in cookies in some other corner of the user’s browser.
One popular technique was to use Flash cookies. These are conceptually similar to normal cookies, but they are specific to Adobe’s Flash plug-in. In the past, a website could hide information in Flash cookies, which would survive the clearing of normal cookies. The information retained in the Flash cookies would then be used to regenerate the deleted normal cookies. Companies made use of this sneaky tactic for a few years before researchers caught on [PDF] and started publicizing these shady practices in 2008. Today, most browsers give users the ability to delete all flavors of cookies.
Taking Your Print
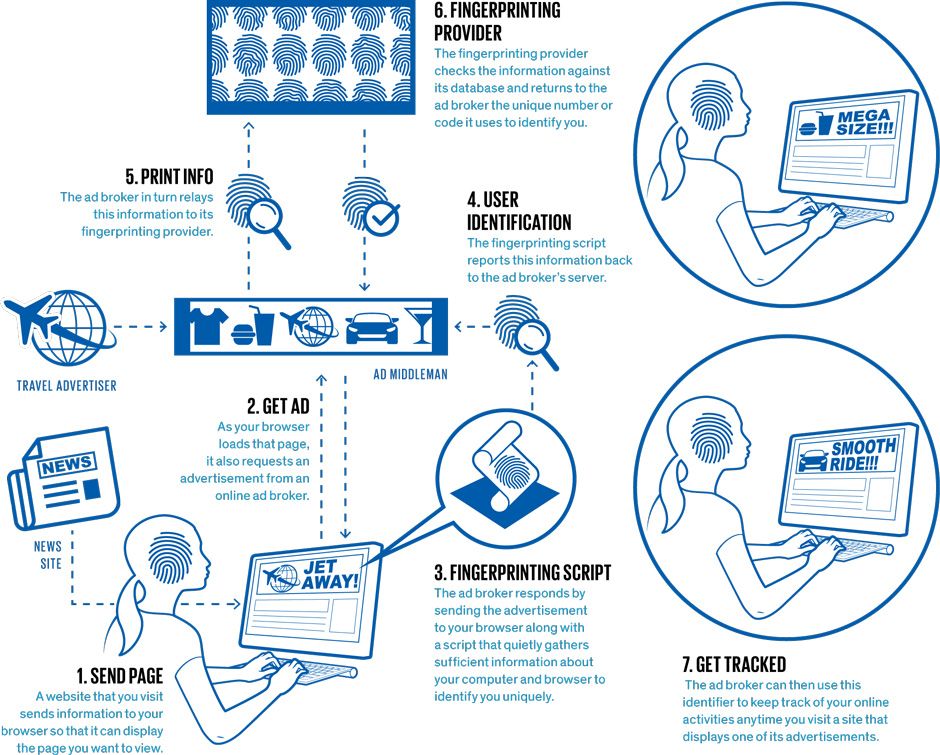
As you might expect of this long-standing cat-and-mouse game, the advertising networks have not sat idle. In recent years, they have shifted to a form of tracking that doesn’t require Web servers to leave any kind of metaphorical bread crumb on the user’s machine. Instead, these ad networks rely on a process known more generally as device fingerprinting: collecting identifying information about unique characteristics of the individual computers people use. Under the assumption that each user operates his or her own hardware, identifying a device is tantamount to identifying the person behind it.
While this all sounds very sinister, it’s important to realize that such fingerprinting has some very benign, indeed laudable, applications. It can be used, for example, to verify that someone logging into a Web-based service is not an attacker using stolen log-in credentials. Fingerprinting is also helpful for combating click fraud: Someone displays an advertisement on his website in return for payment each time that ad is clicked on—and then tries to run up the bill by having an identity-feigning computer click many times on the ad. The problem is that fingerprinting has become so precise that it makes a sham of browsers’ privacy-protection measures.
In 2010, Peter Eckersley of the Electronic Frontier Foundation showed that tracking various browser attributes provided enough information to identify the vast majority of machines surfing the Web. Of the 470,000-plus users who had participated at that point in his public Panopticlick project, 84 percent of their browsers produced unique fingerprints (94 percent if you count those that supported Flash or Java). The attributes Eckersley logged included the user’s screen size, time zone, browser plug-ins, and set of installed system fonts.
We have expanded on Eckersley’s study by examining not just what kinds of fingerprinting are theoretically possible but, more to the point, what is actually going on in the wilds of the Internet’s tracking ecosystem. We started our analysis at the University of Leuven, in Belgium, by first identifying and studying the code of three large fingerprinting providers: BlueCava, Iovation, and ThreatMetrix.
The results were rather chilling. The tactics these companies use go far beyond Eckersley’s probings. For instance, we found that one company uses a clever, indirect method of identifying the installed fonts on a user machine, without relying on the machine to volunteer this information, as Eckersley’s software did.
We also discovered fingerprinting code that exploits Adobe Flash as a way of telling whether people are trying to conceal their IP addresses by communicating via intermediary computers known as proxies. In addition, we exposed Trojan horse–like fingerprinting plug-ins, which run surreptitiously after a user downloads and installs software unrelated to fingerprinting, such as an online gambling application.
With the information we gathered about these three companies, we created and ran a program that autonomously browses the Web and detects when a website is trying to fingerprint it. The purpose of this experiment was to find more players in the fingerprinting game, ones less well known than the three we studied initially.
We quickly uncovered 16 additional fingerprinters. Some were in-house trackers, used by individual companies to monitor their users without sharing the information more widely. The rest were offered as products by such companies as Coinbase, MaxMind, and Perferencement.
And it seems the companies selling this software are finding buyers. Our results showed that 159 of Alexa’s 10,000 most-visited websites track their users with such fingerprinting software. We also found that more than 400 of the million most popular websites on the Internet have been using JavaScript-only fingerprinting, which works on Flash-less devices such as the iPhone or iPad. Worse, our experiment revealed that users continue to be fingerprinted even if they have checked “Do Not Track” in their browser’s preferences.
 Photo: Dan Saelinger; Prop Stylist: Dominique Baynes
Photo: Dan Saelinger; Prop Stylist: Dominique Baynes
Browser fingerprinting is becoming common, and yet people are mostly in the dark about it. Even when they’re made aware that they’re being tracked, say, as a fraud-protection measure, they are, in essence, asked to simply trust that the information collected won’t be used for other purposes. One of those is targeted advertising, which works even when users switch into their browsers’ private mode or delete their cookies. What are those unwilling to go along with this new form of tracking doing about it?
As part of our research on browser fingerprinting, we examined various tools that people are using to combat it. One popular approach is installing browser extensions that let you change the values that identify your browser to the server. Such modifications allow users to occasionally trick servers into dishing out pages customized for different browsers or devices. Using these extensions, Firefox devotees on computers running Linux, for example, can pretend to be Internet Explorer fans running Microsoft Windows. Other extensions go further, reporting false dimensions for the screen size and limiting the probing of fonts.
Our analysis showed that a mildly accomplished fingerprinter could easily overcome any of these supposedly privacy-enhancing browser extensions. That’s because modern browsers are huge pieces of software, each with its own quirks. And these idiosyncrasies give away the true nature of the browser, regardless of what it claims to be.
This makes those privacy-protecting extensions useless. In fact, they are worse than useless. Resorting to them is like trying to hide your comings and goings in a small town by disguising your car. If you get a rental, that might work. But if you merely replace the chrome lettering on your Prius with lettering taken from the back of a Passat, not only will your ruse be obvious, you will have now marked your car in a way that makes it easy to distinguish from the many other Priuses on the road. Similarly, installing such a fingerprint-preventing browser extension only makes you stand out more.
Given that advertising is the Web’s No. 1 industry and that tracking is a crucial component of it, we believe that user profiling in general and fingerprinting in particular are here to stay. But more-stringent regulations and more-effective technical countermeasures might one day curb the worst abuses.
We and other researchers are indeed trying to come up with better software to thwart fingerprinting. A straightforward solution might be to stop the fingerprinting scripts from ever loading in browsers, similar to the way ad blockers work. By maintaining a blacklist of problematic scripts, an antifingerprinting extension could detect their loading and prohibit their execution.
One challenge is that the blacklist would have to be revised constantly to keep up with the changes that trackers would surely make in response. Another issue is that we don’t know whether the loading of fingerprinting scripts is necessary for the functionality of certain websites. Even if it’s not required now, websites could be changed to refuse loading of their pages unless the fingerprinting scripts are present and operational, which would discourage people from trying to interfere with them.
A more effective way of approaching the problem would be for many people to share the same fingerprint. To some extent that is happening now with smartphones, which can’t be customized to the degree that desktop or laptop computers can. So phones currently present fewer opportunities for fingerprinters. It might be possible to make other kinds of computers all look alike if Web browsing were done through a cloud service, one that treats the browser running on the user’s PC simply as a terminal. Trackers would then be able to detect only the cloud browser’s fingerprint.
Companies offering cloud-based browsing already exist, but it’s not clear to us whether the browsers that are exposed to potential fingerprinters actually operate in the cloud. Still, there’s no reason to think that a system for preventing fingerprinting with a cloud browser couldn’t be engineered. For some of us, anyway, it could be worth adopting, even if it involved monthly charges. After all, doing nothing has a price, too—perhaps one as steep as forfeiting online privacy for good.
This article originally appeared in print as “Browse at Your Own Risk.”
About the Authors
Nick Nikiforakis, who joins the faculty of New York’s Stony Brook University in September, works at the University of Leuven, in Belgium, where coauthor Günes Acar is a Ph.D. student. Nikiforakis was raised in Greece, where the Muppets are somewhat obscure, but he sometimes refers to the creepy new technique as a “cookieless monster”—an apt label if you value your privacy.