Today's boom in AI is centered around a technique called deep learning, which is powered by artificial neural networks. Here's a graphical explanation of how these neural networks are structured and trained.
ARCHITECTURE
DAVID SCHNEIDER
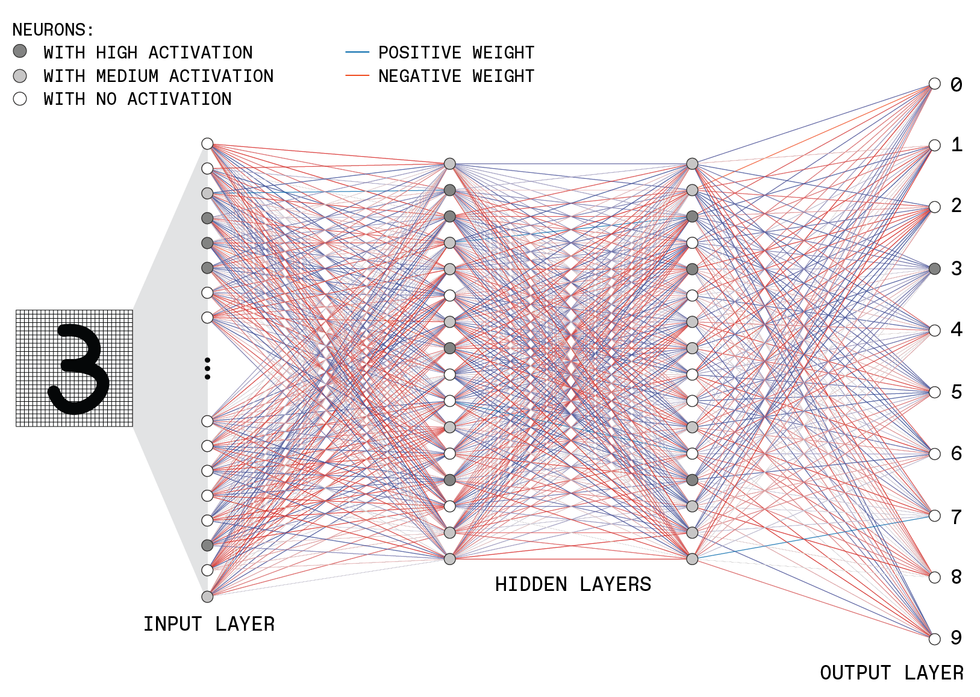
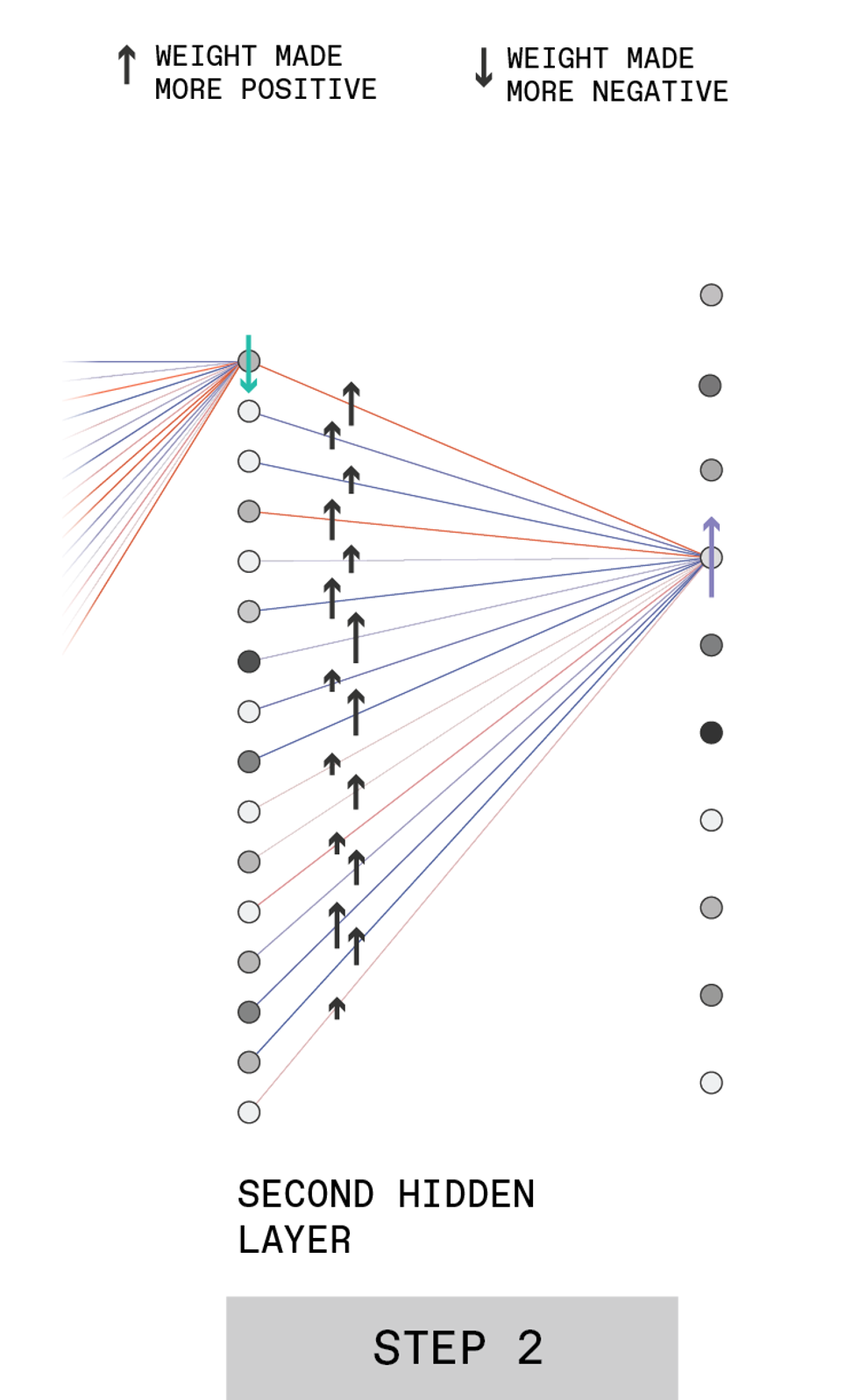
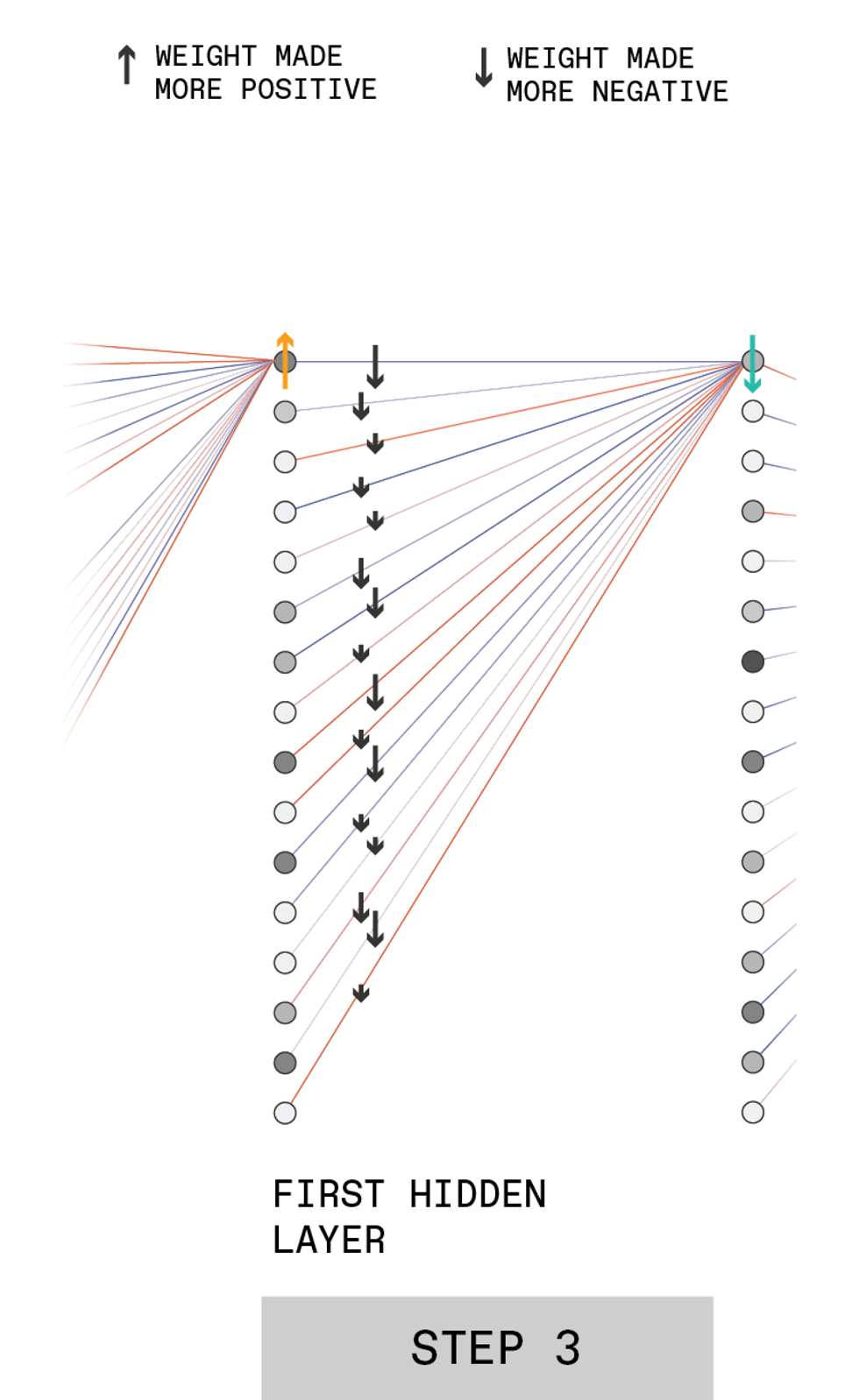
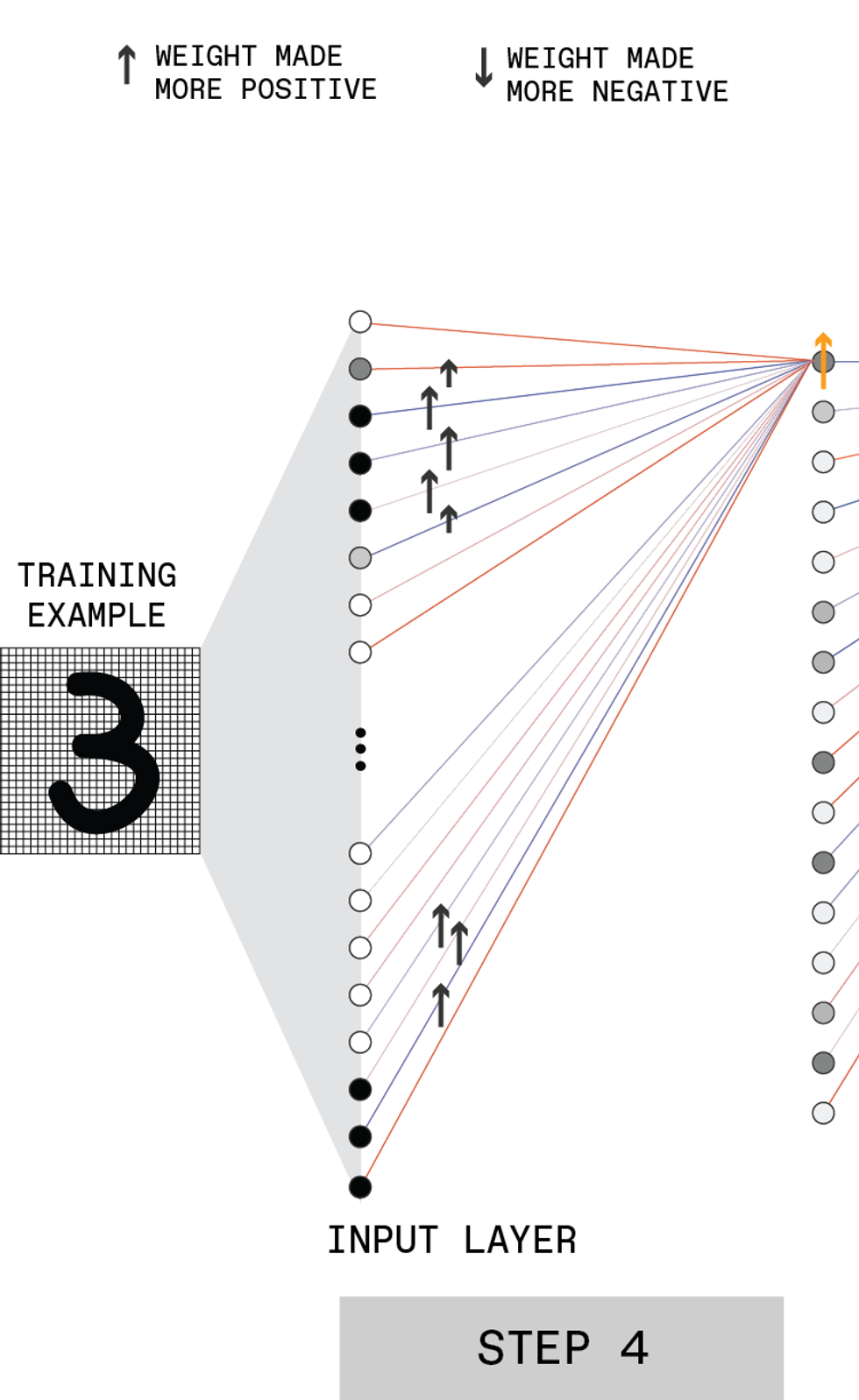
Here's the structure of a hypothetical feed-forward deep neural network ("deep" because it contains multiple hidden layers). This example shows a network that interprets images of hand-written digits and classifies them as one of the 10 possible numerals.
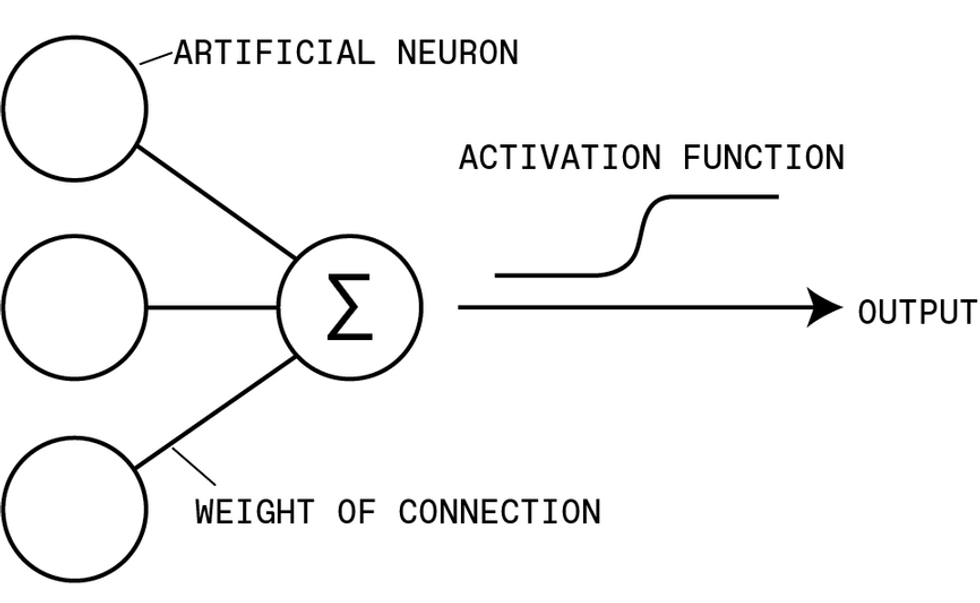
The input layer contains many neurons, each of which has an activation set to the gray-scale value of one pixel in the image. These input neurons are connected to neurons in the next layer, passing on their activation levels after they have been multiplied by a certain value, called a weight. Each neuron in the second layer sums its many inputs and applies an activation function to determine its output, which is fed forward in the same manner.

DAVID SCHNEIDER
Special Report: The Great AI Reckoning

READ NEXT:How DeepMind Is Reinventing the Robot
Or see the full report for more articles on the future of AI.
- Cerebras's Giant Chip Will Smash Deep Learning's Speed Barrier ... ›
- The Future of Deep Learning Is Photonic - IEEE Spectrum ›
- Deep Learning's Diminishing Returns - IEEE Spectrum ›
- Copy of Deep Learning Can’t be Trusted, Brain Modelling Pioneer Says - IEEE Spectrum ›
- Deep Learning Can’t be Trusted Brain Modelling Pioneer Says - IEEE Spectrum ›
- Some AI Systems May Be Impossible to Compute ›