The Conversation (0)

Illustration: Greg Mably
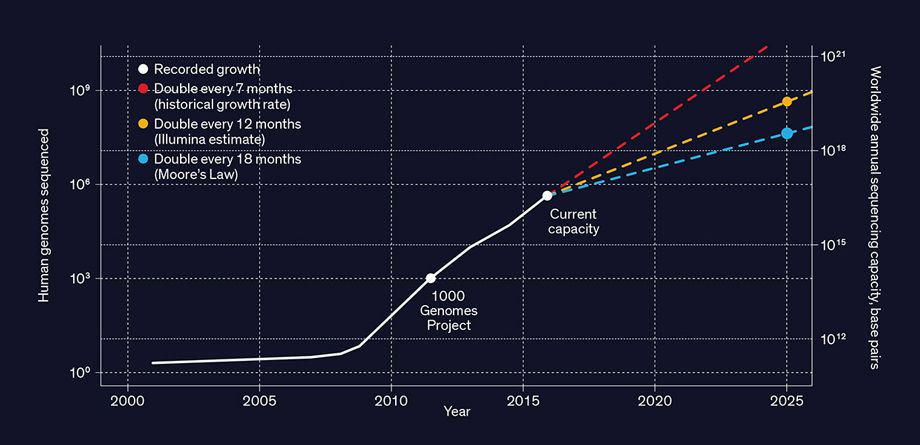
Have you had your genome sequenced yet? Millions of people around the world already have, and by 2025 that number could reach a billion.
The more genomics data that researchers acquire, the better the prospects for personal and public health. Already, prenatal DNA tests screen for developmental abnormalities. Soon, patients will have their blood sequenced to spot any nonhuman DNA that might signal an infectious disease. In the future, someone dealing with cancer will be able to track the progression of the disease by having the DNA and RNA of single cells from multiple tissues sequenced daily.
And DNA sequencing of entire populations will give us a more complete picture of society-wide health. That’s the ambition of the United Kingdom’s Biobank, which aims to sequence the genomes of 500,000 volunteers and follow them for decades. Already, population-wide genome studies are routinely used to identify mutations that correlate with specific diseases. And regular sequencing of organisms in the air, soil, and water will help track epidemics, food pathogens, toxins, and much more.
This vision will require an almost unimaginable amount of data to be stored and analyzed. Typically, a DNA sequencing machine that’s processing the entire genome of a human will generate tens to hundreds of gigabytes of data. When stored, the cumulative data of millions of genomes will occupy dozens of exabytes.
And that’s just the beginning. Scientists, physicians, and others who find genomic data useful aren’t going to stop at sequencing each individual just once [PDF]—in the same individual, they’ll want to sequence multiple cells in multiple tissues repeatedly over time. They’ll also want to sequence the DNA of other animals, plants, microorganisms, and entire ecosystems as the speed of sequencing increases and its cost falls—it’s just US $1,000 per human genome now and rapidly dropping. And the emergence of new applications—and even new industries—will compel even more sequencing.
While it’s hard to anticipate all the future benefits of genomic data, we can already see one unavoidable challenge: the nearly inconceivable amount of digital storage involved. At present the cost of storing genomic data is still just a small part of a lab’s overall budget. But that cost is growing dramatically, far outpacing the decline in the price of storage hardware. Within the next five years, the cost of storing the genomes of billions of humans, animals, plants, and microorganisms will easily hit billions of dollars per year. And this data will need to be retained for decades, if not longer.
Compressing the data obviously helps. Bioinformatics experts already use standard compression tools like gzip to shrink the size of a file by up to a factor of 20. Some researchers also use more specialized compression tools that are optimized for genomic data, but none of these tools have seen wide adoption. The two of us do research on data compression algorithms, and we think it’s time to come up with a new compression scheme—one that’s vastly more efficient, faster, and better tailored to work with the unique characteristics of genomic data. Just as special-purpose video and audio compression is essential to streaming services like YouTube and Netflix, so will targeted genomic data compression be necessary to reap the benefits of the genomic data explosion.
Before we explain how genomic data could be better compressed, let’s take a closer look at the data itself. “Genome” here refers to the sequence of four base nucleotides—adenine, cytosine, guanine, and thymine—that compose the familiar A, C, G, T alphabet of DNA. These nucleotides occur in the chains of A-T and C-G pairs that make up the 23 pairs of chromosomes in a human genome. These chromosomes encompass some 6 billion nucleotides in most human cells and include coding genes, noncoding elements (such as the telomeres at the ends of chromosomes), regulatory elements, and mitochondrial DNA. DNA sequencing machines like those from Illumina, Oxford Nanopore Technologies, and Pacific Biosciences are able to automatically sequence a human genome from a DNA sample in hours.
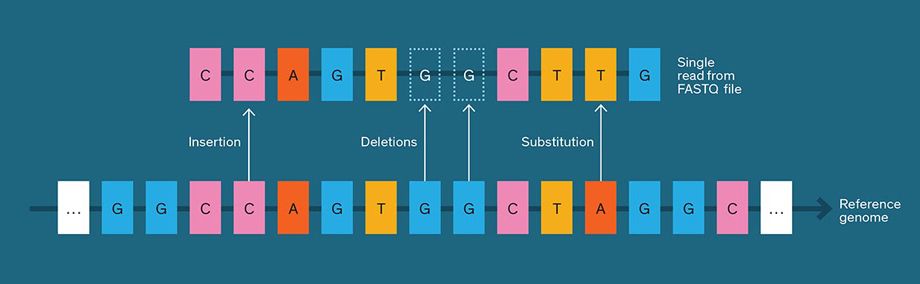
These commercial DNA sequencers don’t produce a single genome-long string of ACGTs but rather a large collection of substrings, or “reads.” The reads partially overlap each other, requiring sequence-assembly software to reconstruct the full genome from them. Typically, when whole-genome sequencing is performed, each piece of the genome appears in no more than about 100 reads.
Depending on the sequencing technology used, a read can vary in length from about 100 to 100,000 base pairs, and the total number of reads varies from millions to tens of billions. Short reads can turn up single base-pair mutations, while longer reads are better for detecting complicated variations like deletions or insertions of thousands of base pairs.
DNA sequencing is a noisy process, and it’s common for reads to contain errors. And so, besides the string of ACGT nucleotides, each read includes a quality score indicating the sequencing machine’s confidence in each DNA nucleotide. Sequencers express their quality scores as logarithms of error probabilities. The algorithms they use to do so are proprietary but can be checked after the fact. If a quality score is 20—corresponding to an error probability of 1 percent—a user can confirm that about 1 percent of the base pairs were incorrect in a known DNA sequence. Programs that use these files rely on quality scores to distinguish a sequencing error from, say, a mutation. A true mutation would show a higher average quality score—that is, a lower probability of error—than a sequencing error would.
The sequencer pastes together the strings and the quality scores, along with some other metadata, read by read, to form what is called a FASTQ file. A FASTQ file for an entire genome typically contains dozens to hundreds of gigabytes.
The files are also very redundant, which stems from the fact that any two human genomes are nearly identical. On average, they differ in about one nucleotide per 1,000, and it’s typically these genetic differences that are of interest. Some DNA sequencing targets specific areas of difference—for example, DNA-genotyping applications like 23andMe look only for specific variations, while DNA profiling in criminal investigations looks for variations in the number of repetitions of certain markers.
But you need to sequence the whole genome if you don’t know where the interesting stuff lies—when you’re trying to diagnose a disease of unknown genetic origin, say—and that means acquiring much larger quantities of sequencing data.
The repetition in sequencing data also comes from reading the same portions of the genome multiple times to weed out errors. Sometimes a single sample contains multiple variations of a sequence, so you’ll want to sequence it repeatedly to catch those variations. Let’s say you’re trying to detect a few cancer cells in a tissue sample or traces of fetal DNA in a pregnant woman’s blood. That may mean sequencing each DNA base pair many times, often more than 100, to distinguish the rare variations from the more common ones and also the real differences from the sequencing errors.
By now, you should have a better appreciation of why DNA sequencing generates so much redundant data. This redundancy, it turns out, is ideal for data compression. Rather than storing multiple copies of the same chunk of genomic data, you can store just one copy.
To compress genomic data, you could first divide each DNA sequence read into smaller chunks, and then assign each chunk a numerical index. Eventually, the sum total of indexes constitutes a dictionary, in which each entry isn’t a word but a short sequence of DNA base pairs.
Text compressors work this way. For example, GitHub hosts a widely used list of words that people can use to assign each word its own numerical index. So to encode a passage of text into binary, you’d replace each word with its numerical index—the list on GitHub assigns the number 64,872 to the word compression—which you’d then render in binary format. To compress the binary representation, you could sort the dictionary by word usage frequency instead of alphabetical order, so that more common words get smaller numbers and therefore take fewer bits to encode.
Another common strategy— the Lempel-Ziv family of algorithms—builds up a dictionary of progressively longer phrases rather than single words. For example, if your text often contains the word genomic followed by data, a single numerical index would be assigned to the phrase genomic data.
Many general-purpose compression tools such as gzip, bzip2, Facebook’s Zstandard, and Google’s Brotli use both of these approaches. But while these tools are good for compressing generic text, special-purpose compressors built to exploit patterns in certain kinds of data can dramatically outperform them.
Consider the case of streaming video. A single frame of a video and the direction of its motion enable video compression software to predict the next frame, so the compressed file won’t include the data for every pixel of every frame. Moreover, the viewer can tolerate some barely perceptible loss of video information or distortion, which isn’t the case with text-based data. To take advantage of that fact, an international consortium spent years developing the H.264 video compression standard (now used by Blu-ray Disc, YouTube, the iTunes store, Adobe Flash Player, and Microsoft’s Silverlight, among many others).
Researchers have likewise been devising special-purpose tools for compressing genomic data, with new ones popping up in the academic literature about once a month. Many use what’s called reference-based compression, which starts with one human genome sequence as its reference. Any short human DNA sequence—that is, one made up of 100 base pairs or less—is likely to appear somewhere in that reference, albeit with sequencing errors and mutations. So instead of listing all the base pairs in a string of 100, a specialized compressor notes only where the string starts within the reference (for example, “1,000th base pair in chromosome 5”) and describes any deviations from the reference sequence (for example, “delete the 10th base pair”). The reference-based approach requires the user to have a copy of the reference human genome, about 1 gigabyte in size, in addition to the compressor software.
As mentioned, FASTQ files contain not just DNA sequences but also quality scores indicating potential errors. Unfortunately, reference-based compression can’t be used to compress FASTQ quality scores because there is no reference sequence for quality scores. Instead, these tools look at patterns in the quality scores—that a low-quality score is likely to be followed by another low-quality score, for example, or that quality scores tend to be higher at the beginning of a DNA read than toward the end. Just as numbering all words in order of decreasing usage frequency lets us compress text, numbering the set of possible quality scores in the order of their predicted likelihood lets us compress this data. Instead of storing and compressing low-quality data, researchers sometimes discard it, but the data compression program might not be able to decide exactly which data to discard or what the threshold for “low quality” is.
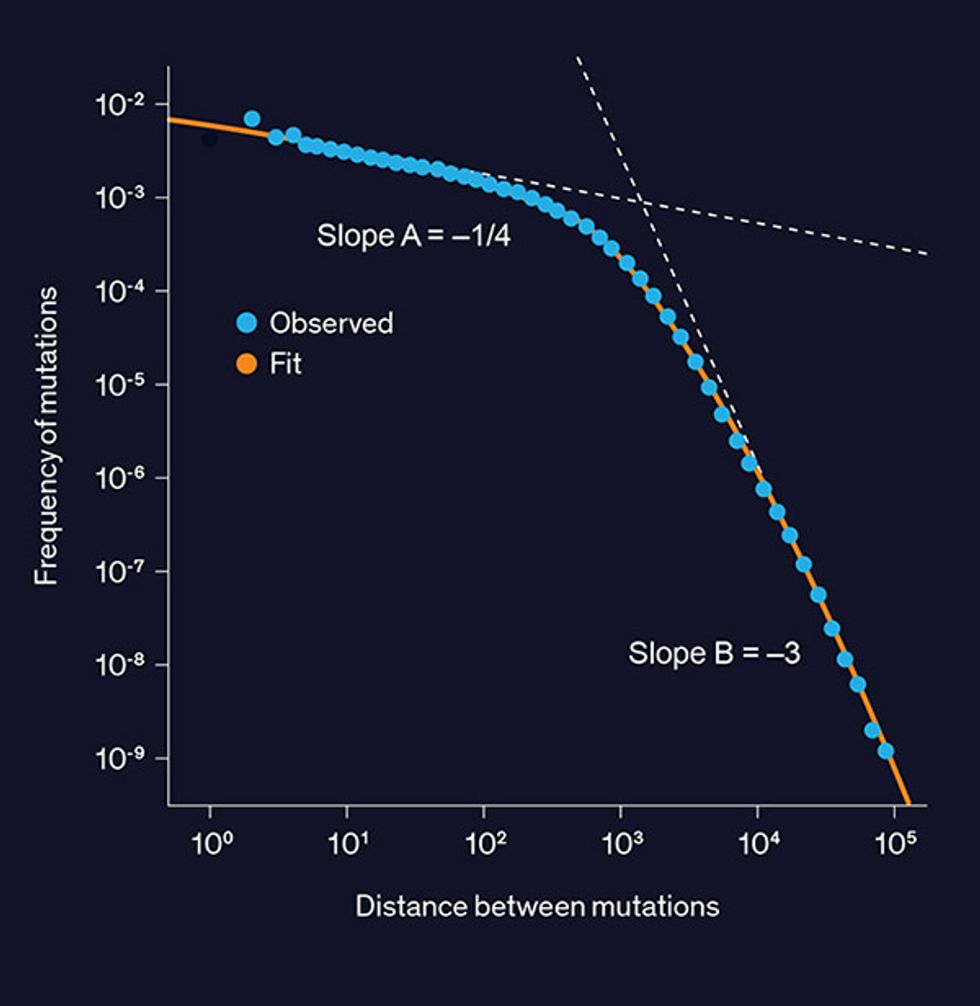 Double Power Law: Distances between adjacent DNA mutations within a single genome follow a “double power law” probability distribution. At around 1,000 DNA base pairs, the slope changes from about –1/4 to about –3 on a plot that uses logarithmic scales on both axes. Understanding this distribution could lead to better compression algorithms.Source: Dmitri S. Pavlichin, Tsachy Weissman, and Golan Yona, 2013,
Bioinformatics
Double Power Law: Distances between adjacent DNA mutations within a single genome follow a “double power law” probability distribution. At around 1,000 DNA base pairs, the slope changes from about –1/4 to about –3 on a plot that uses logarithmic scales on both axes. Understanding this distribution could lead to better compression algorithms.Source: Dmitri S. Pavlichin, Tsachy Weissman, and Golan Yona, 2013,
Bioinformatics
These new compressors are a good start, but they’re far from perfect. As our understanding of the data evolves, so will our ability to compress the data. Data compression forces us to look for nonobvious patterns and redundancies in the data; when we reach the point of compressing the data deeply, we’ll know that we finally understand it. A genomic data compressor that factors in subtle patterns in the data will result in smaller file sizes and reduced storage costs.
In our own research at Stanford University, we’ve made one potentially useful observation: The distance along the genome between consecutive DNA variations follows a “double power law” distribution. You may be familiar with the concept of the “power law” distribution, in which the probability of an outcome is proportional to the inverse magnitude of that outcome, possibly raised to some power. City populations typically follow this distribution: There are about half as many cities with 2 million people as there are cities with 1 million people. This law can also apply to a country’s distribution of wealth, where 20 percent of the population holds 80 percent of the wealth.
A double power law consists of two different power laws operating on the same type of data but covering different ranges. For example, an 80/20 rule could apply to the lower half of a population by wealth, while a 90/10 rule applies to the upper half. Double power laws can be used to describe the distribution of the number of friends on Facebook, durations of phone calls, and file sizes on a hard drive.
And it turns out that a histogram plot of the distance between adjacent genetic variations, measured in DNA base pairs, looks like a double power law, with the crossover point between the two power laws happening at around 1,000 DNA base pairs [see graph, "Double Power Law"]. It’s an open question as to what evolutionary process created this distribution, but its existence could potentially enable improved compression. One of Claude Shannon’s foundational achievements in information theory states that data can’t be compressed below the Shannon entropy—a measure of randomness—of its distribution. A double power law distribution turns out to be less random—that is, it has lower entropy—than a model that assumes each location in the genome is equally likely to contain a variation. We are excited by this discovery—both as an intriguing biological phenomenon and as a hint that greater compression savings lie untapped.
 Sorting: Arranging DNA substrings, or “reads,” in alphabetical order results in similar reads being placed near one another, reducing the number of differences between adjacent reads, and thus reducing the space to compress the reads.
Sorting: Arranging DNA substrings, or “reads,” in alphabetical order results in similar reads being placed near one another, reducing the number of differences between adjacent reads, and thus reducing the space to compress the reads.
The genomic data compressors in use today are lossless—that is, they allow you to recover the uncompressed file bit for bit, exactly as it was before compression. But there’s a case for allowing some amount of loss, not in the DNA sequences but in the quality scores denoting the sequencer’s confidence in the data. While there are only four DNA nucleotides (A,C,G,T), there are typically about 40 possible quality scores, so most of the bits in a lossless compressed FASTQ file make up the quality score rather than the DNA sequences. This amount of precision is wasteful, as applications that use genomic data tend to ignore small variations in quality scores or may discard the quality scores entirely. Indeed, performance on some tasks, like finding variations between two genomes, actually improves when the quality scores are compressed in a lossy way, because lossy compression smooths out irrelevant variations among the quality scores, effectively removing noise from the data.
We can also save on storage space by discarding other pieces of genomic sequencing information. The exact order in which DNA reads appear in a FASTQ file is often unimportant for subsequent analysis: You could, in many cases, such as when identifying genetic variations, shuffle the reads in a random order and expect nearly the same output. So you could sort the DNA reads alphabetically, and then exploit the fact that sorted lists can be compressed more than unsorted ones. The analogous case in text compression would be to sort a list of words and state the distance between adjacent words. The words decompressed and decompresses, for example, are adjacent in the dictionary, and their last letters (d and s) are 15 letters apart in the alphabet, so you can encode the entire second word with just the integer 15.
As an example of how this method works on DNA, let’s sort the sequences ACGAAA, ACGAAG, and ACGAAT alphabetically. The first five letters are all the same, so we’re interested only in the differences between the sixth letters. The second sequence is then encoded as the integer 2 (because the last letter, G, is two letters after A in the nucleotide alphabet ACGT), and the third sequence is encoded as a 1 (because its last letter, T, is one letter after G). This approach could result in a twofold or greater savings relative to storing the DNA reads in their original order.
Of course, the compression ratio is just one measure of a compression tool’s capabilities. Speed is another factor. Some special-purpose FASTQ compressors run in parallel, saving time over a single-CPU implementation; others exploit GPU and field-programmable gate array processors, hardware that’s more commonly used to accelerate video processing and machine learning. Another useful feature is being able to search compressed data. You don’t want to have to decompress an entire file in order to do a quick search for occurrences of a particular DNA sequence within it.
While a lot of genomic compression options are emerging, what’s needed now is standardization. Just as video compression technology couldn’t take off until a good portion of the industry agreed to a standard, genomic compression technology will have to move toward one standard—or at least a small set of standards.
Fortunately, work on a compression standard for genomic sequencing data has begun. The Moving Picture Experts Group (MPEG)—the same body that developed the MP3 audio format and several popular video formats—has for several years been developing a standard for compressed genomic data, an effort named MPEG-G. The specification is expected to be completed late this year. This standard will evolve as the technology improves, in the same way that video compression standards have been doing.
The pace at which we develop efficient, sound, and standardized genomic data compression is simply a matter of economics. As the amount of stored data skyrockets, and the cost of storage becomes onerous, reducing the cost will propel the industry toward better compression methods.
Right now, genomic research may be on the cusp of reaping unexpected benefits as the total amount of sequence data accumulates; today, the field is approximately where artificial intelligence was a mere decade ago. The recent dramatic advances in AI have been driven in large part by the availability of vast data sets; deep-learning algorithms that performed poorly on moderate amounts of data became powerful when used with massive sets. Genomic researchers have started applying deep learning to their data, but they’ll likely have to wait for a critical mass of genomic information to accumulate before realizing similar gains. One thing is clear, though: They won’t get there without major advances in genomic data compression technology.
This article appears in the September 2018 print issue as “The Quest To Save Genomics.”
HBO’s Data Compression Stars
 Photo: Tekla Perry
Photo: Tekla Perry
For fans of the HBO television show “Silicon Valley,” the name “Weissman” and “data compression technology” go together like Heinz and ketchup. The show has prominently featured the Weissman Score, a metric that rates the power of a compression algorithm.
Stanford professor of electrical engineering Tsachy Weissman [right] helped create that metric for the show, which premiered in 2014. Although the algorithm was made for TV, academics in the real world picked up on it.
The creators of “Silicon Valley” tapped Weissman as they were developing the first season and casting about for a technology to feature. They had settled on a universal compression algorithm, but they needed an expert to come up with the specifics of a technology that would be plausible but not possible today. They reached out to Weissman, and he laid out what he calls the holy grail of the compression world: a form of powerful and efficient lossless compression that can work on any type of data and is searchable.
That worked out nicely for the show, but given that such a compression scheme won’t exist in the real world anytime soon, Weissman continues to pursue his research. Most recently, his work has focused on genomic compression algorithms, which he and Dmitri Pavlichin [left], a Stanford postdoctoral fellow, describe in the article above.
Incidentally, Pavlichin took over Weissman’s original gig on “Silicon Valley” in 2017, coming up with plausible technology for season 4. He contributed sketches of whiteboards and technical documents and edited snippets of dialogue. A favorite moment of his came when the show’s characters attempt to move their server to the Stanford campus and give a shout-out to Sherlock, a computing cluster that Pavlichin uses daily.
Recently, the show’s fictional startup pivoted from compression technology to decentralizing the Internet. But the Weissman Score has already earned its place in tech history.
—Tekla S. Perry


