
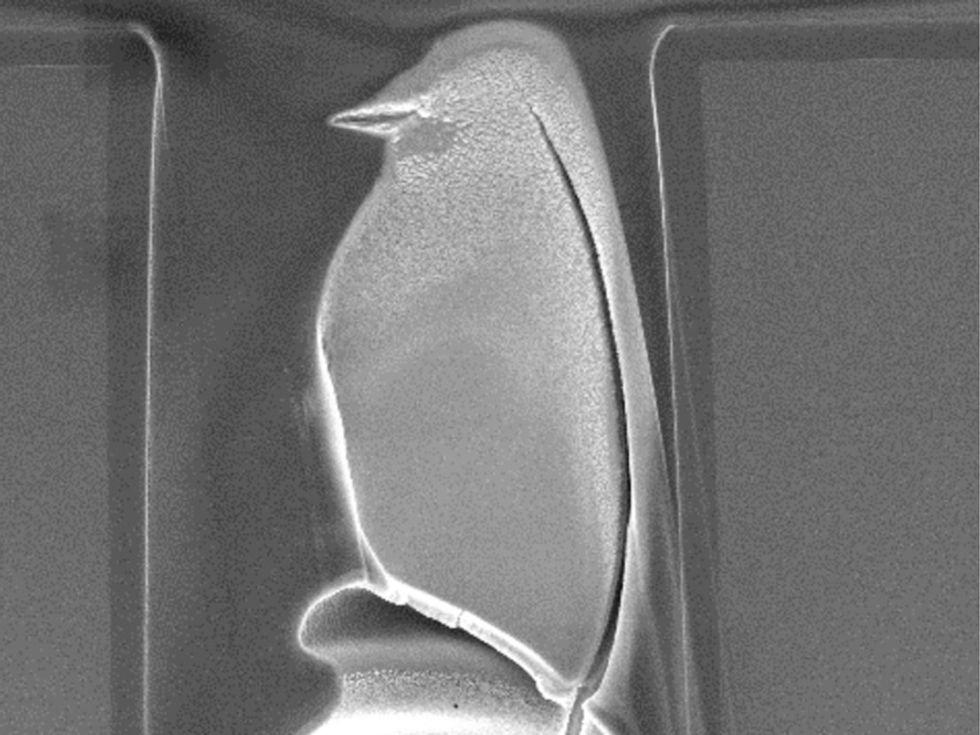
Photo: Lew Li Lian/GlobalFoundries
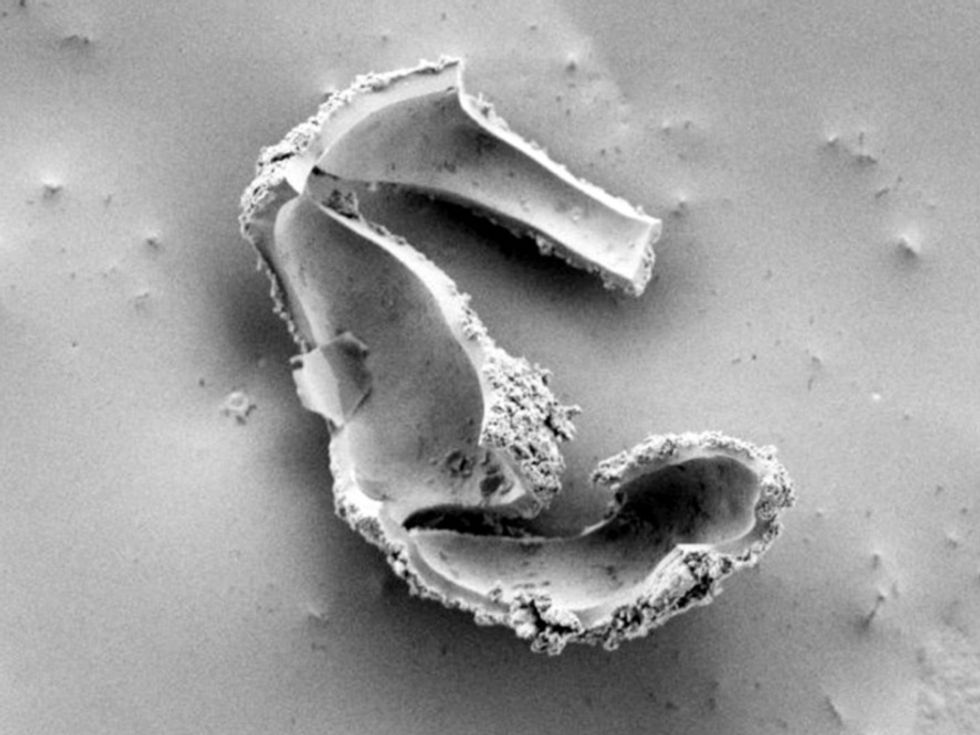
Birdie in the Hole: This little bird sits contentedly under the microscope’s gaze, but it didn’t fly there on its own. According to Lew Li Lian from GlobalFoundries, in Singapore, “A particle in the hole caused a cavity formation in the precoat material, resembling a birdie.” It won first prize at the 2014 IEEE International Symposium on the Physical and Failure Analysis of Integrated Circuits (IPFA) Art of Failure Analysis contest.


![]()
From Your Site Articles
The Conversation (0)


