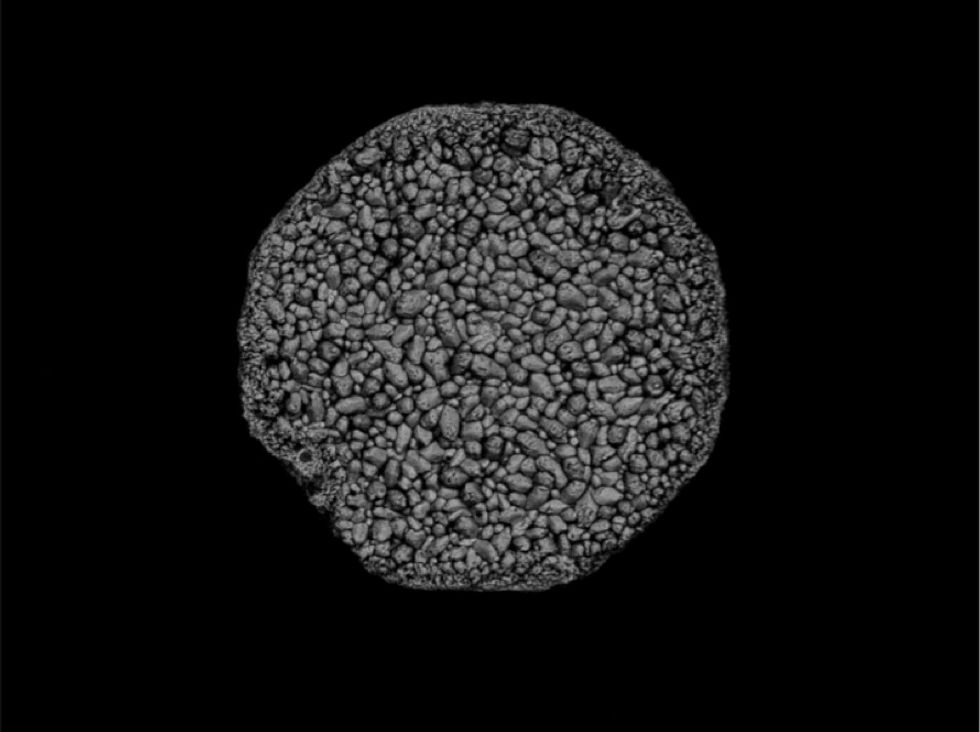
Image: Rahmat Agung Susantyoko
This year’s first-prize winner in the “Art of Failure Analysis” contest is an image of a bed of 0.13-micrometer-wide “nanoflowers” sitting on a silicon substrate. The flowers “blossomed” when an array of vertically oriented silicon nanowires bent from their original upright position. Rahmat Agung Susantyoko, who took the image, was given the task of monitoring the height of arrays of silicon nanowires. Nanowires of a certain height bent together to form the flowers.








Just as one man’s trash is another man’s treasure, one person’s systems failure is another one’s masterpiece. This is the third year that the “Art of Failure Analysis”was featured at the IEEE International Symposium on the Physical and Failure Analysis of Integrated Circuits (IPFA). Participants submitted the most intriguing images they’d captured during chip autopsies. Favorite pictures from the collection, which range from charming to just plain creepy, were on display at the symposium from 5 to 9 July in Singapore.
The Conversation (0)