The Conversation (0)

Illustration: QuickHoney
Purple
The Internet is more than 45 years old, and it's starting to show its age. To be sure, it has served us wonderfully well. Its underlying technologies delivered the World Wide Web (still a young adult at around 28 years old) and our global communications network. Even as its user base has swelled to 3.4 billion, these technologies have scaled admirably.
Today, however, all of those users demand a level of performance that the Internet was never designed to deliver. The authors of the original Internet protocols, who began their pioneering work in the late 1960s, designed them for a network to be used mainly for sending electronic mail from one computer to another. Now, though, people spend far more time streaming Netflix movies. Oftentimes, one piece of content must be distributed to hundreds of thousands or millions of users simultaneously—and in real time.
With its growth and shifts in usage, the Internet is being severely strained. That's why you're often stuck watching a “buffering" message when you're trying to watch a viral video.
Increasingly, network engineers find themselves scrambling for patches to improve performance or searching for ways to squeeze slightly more capacity from this creaky infrastructure. Looking ahead to what it hopes will be a golden era for the Internet, Cisco Systems expects global traffic to grow by 22 percent per year through 2020. It's hard to imagine that happening, however, if the original framework remains in place.
What we really need is an Internet that can provide more bandwidth and lower latency to many users at once—and do it securely. Along with our colleagues at the Palo Alto Research Center (PARC), in California, we've developed a better Internet architecture. We call it content-centric networking, or CCN. Our approach fundamentally changes the way information is organized and retrieved and improves network reliability, scalability, and security.
After a decade of development, we're now testing our concept: In January 2016, PARC released the open-source code for CCN software. Since then, more than 1,000 copies have been downloaded by individuals, universities, and industrial-research organizations. Companies including Alcatel-Lucent (now part of Nokia), Huawei, Intel, Panasonic, and Samsung have also had substantial R&D efforts focused on one or more aspects of CCN in recent years. In February, Cisco announced that it had acquired the CCN platform that we originally developed at PARC.
As the Internet stretches to its next billion users, all of whom will want to stream videos and upload content to their heart's content, it's time for us to rethink the way the Internet was built. Although we don't expect CCN to completely replace the Internet's protocols, we are convinced that an alternative architecture can offer better performance and security in many cases.
The origins of the modern Internet were largely patterned on technologies that support the public telephony system. Just like the telephone system, the early Internet needed a set of addresses to identify users and instructions to spell out how information should be routed and protected throughout the network. Over time, many of the same methods that had been used to make telephone calls reliable and secure, and which enabled the telephone system to scale up, were reproduced in the Internet.
That strategy wasn't perfect, though, because early telephones relied on circuit-switched networks. In such a network, users sent a stream of information over a single connection established at the start of a call. The Internet is a packet-switched network, which means it separates the many bits that make up a piece of content into smaller pieces (packets) of data. On the Internet, packets can be sent over different paths on the network and are reassembled into the original piece of content at its destination.
Each piece of online content is stored on a user's server (known as a host), often that of the content's creator. To retrieve the content, other users must navigate to that server with their requests. Then the packets must be sent back to the requestor.
Along the way, routers must constantly juggle these packets. To help routers direct packets, the Internet's founders came up with a clever system of assigning a unique IP address to every computer or server. The IP address is similar to a phone number. Routers move information along by reading bits on an incoming content packet that indicate its intended destination, looking up the recipient's IP address in routing tables, and forwarding the packet in the recipient's direction.
Whenever an Internet user types in a URL or email address, a Domain Name System translates those characters into the matching IP address. The DNS system is basically a phone book for the Internet. Through these servers, a URL, such as /, becomes an IP address, such as 23.197.245.16.
To enable packets to travel between hosts once a user has the correct IP address, the Internet's founders also built a shared network architecture. It has four basic layers, each with a distinct function. The first layer is the physical link over which information is sent, such as copper wires, fiber-optic cables, cellular towers, and home routers. The second and third layers are governed by common rules known as protocols that define how information is named and routed. Here, the main protocols are the Internet Protocol, which manages addresses for packets and hosts, and the Transmission Control Protocol, which describes how information is transferred. The upper layer has to do with specific applications, with more protocols that translate information for display within different Internet browsers and other programs.
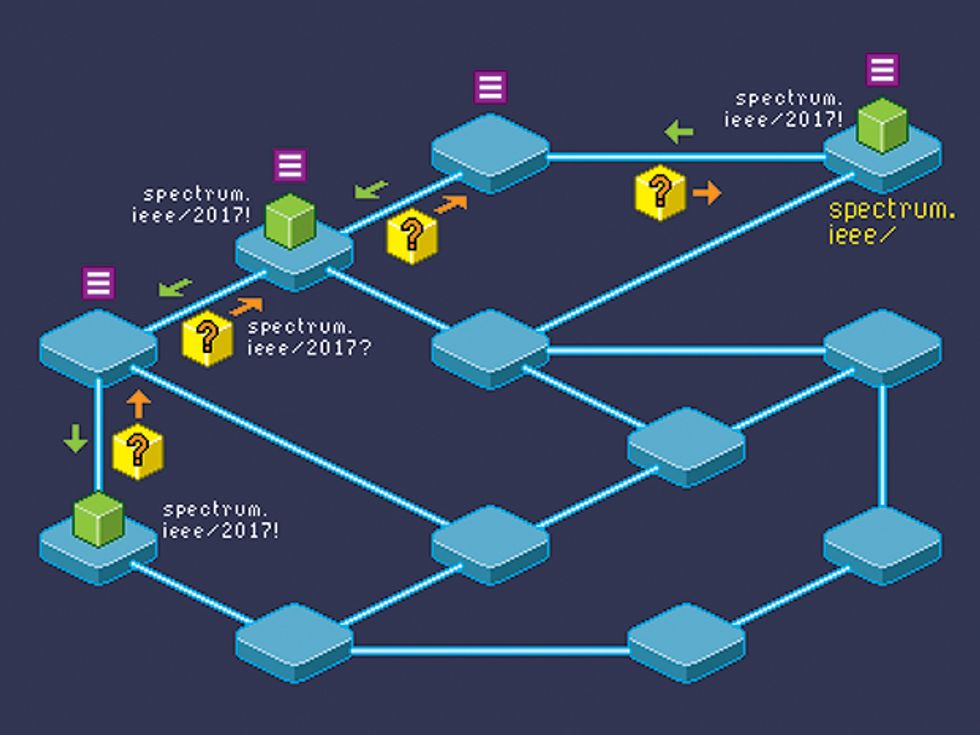 Illustration: QuickHoney
Illustration: QuickHoney
A New Way to Route
To retrieve an IEEE Spectrum article in a content-centric network, a node issues an interest packet [yellow] for content labeled with the routable prefix of spectrum.ieee/2017. Nearby nodes [blue] forward the request [orange] until it finds a content packet [green box] with a matching label. Then, the nodes return that content to the requester by retracing the same path [green arrows]. Along the way, any node may copy and store a popular piece of content in its content store [purple] for future requests.
These basic protocols have supported the Internet for more than four decades of growth. But they do have some shortcomings. For example, they don't always organize content in the most efficient way. Nor do they incorporate security prescriptions such as encryption by default. While these functions can be accomplished by adding more protocols, doing so can increase latency and further burden the network with additional traffic.
With CCN, we've developed a new architecture based on how information is organized within the network, rather than the IP addresses of hosts. That's why it's called content-centric networking—it's based on how content is named and stored, instead of where it is located. We've designed new protocols that can find and retrieve content from wherever it happens to be in the network at a given time and also perform many additional tasks that could make networks faster, more resilient, and more secure.
To understand how all of this works, we'll walk you through how a CCN network finds and retrieves a content packet for a user who is interested in reading an article or watching a video on the Web.
In today's Internet, there is only one kind of data packet—one that carries both content and requests for content between users. But in a CCN network, there are two types: content packets and interest packets. They work together to bring information to users. Content packets are most like traditional data packets. The bits in a content packet may specify part of an ad on a Web page, a piece of a photo in an article, or the first few seconds of a video. Interest packets, on the other hand, are like golden retrievers that a user sends out onto the network to find a specific content packet and bring it back.
When you visit a Web page, your computer needs to fetch about 100 pieces of content on average. A piece of content could be a block of text, a photo, or a headline. With CCN, when you navigate to a website or click on a link, you automatically send out interest packets to specify the content you would like to retrieve. Typing in a single URL, or Web address, can trigger a user's browser to automatically send out hundreds of interest packets to search for the individual components that make up that page.
Both interest and content packets have labels, each of which is a series of bits that indicate which type of packet it is, the time it was generated, and other information. The label on a content packet also includes a name that designates what bits of content it holds, while the label on an interest packet indicates which content it wishes to find. When a user clicks on a link, for example, and generates a flurry of interest packets, the network searches for content packets with matching names to satisfy that request.
The name on a packet's label is called a uniform resource identifier (URI), and it has three main parts. The first part is a prefix that routers use to look up the general destination for a piece of content, and the second part describes the specific content the packet holds or wishes to find. The third part lists any additional information, such as when the content was created or in what order it should appear in a series.
Suppose a Web surfer's browser is using CCN to navigate to this article on IEEE Spectrum's website. The network must find and deliver all the content packets that make up the complete article. To make that process easier, URIs use a hierarchical naming system to indicate which packets are needed for the page, and in what order. For example, one content packet might be named spectrum.ieee/2017/April/ver=2/chunk=9:540. In this example, spectrum.ieee is the routable prefix for the second version of the article, and the specific packet in question is the ninth packet of 540 that make up the complete article.
Once a CCN user has clicked that link or typed it in as a Web address, the user's machine dispatches an interest packet into the network in search of that content, along with other interest packets to search for packets 10 and 11. As the interest packet for number 9 travels along, each router or server it encounters must evaluate that interest packet and determine whether it holds the content packet that can satisfy its request. If not, that node must figure out where in the network to forward the interest packet next.
To do all of this, every node relies on a system known as a CCN forwarder. The forwarder operates on components that are similar to what you'd find in a traditional router. A CCN forwarder requires a processor, memory, and storage to manage requests. The forwarder also runs a common software program called a forwarding engine. The forwarding engine decides where to store content, how to balance loads when traffic is heavy, and which route between two hosts is best.
The forwarding engine in a CCN network has three major components: the content store, the pending interest table, and the forwarding information base. Broadly speaking, CCN works like this: A node's forwarding engine receives interest packets and then checks to see if they are in its content store. If not, the engine next consults the pending interest table and, as a last resort, searches its forwarding information base. While it's routing information, the engine also uses algorithms to decide which content to store, or cache, for the future, and how best to deliver content to users.
To understand how that system improves on our existing Internet protocols, consider what happens when a new interest packet arrives at a node. The forwarding engine first looks for the content in the content store, which is a database that can hold thousands of content packets in its memory for quick and easy access, like the cache memory in a conventional router. But CCN has a key difference. Unlike the traditional Internet protocols, which permit content to be stored only with the original host or on a limited number of dedicated servers, CCN permits any node to copy and store any content anywhere in the network.
To build its own content store, a node can grab any packet that travels through it, keep a copy of it, and add that copy to its store to fill future requests. This ability means that content isn't stuck on the server where it was originally created. Content can move throughout the network and be stored where it's needed most, which could potentially enable faster delivery.
Currently, large companies such as Netflix pay a lot of money to store extra copies of their most popular content on content delivery networks built from regional data centers. With CCN, the entire Internet could act like one big content delivery network. Any server with available memory—not just the servers that Netflix manages—could store the first 3 seconds of a popular Netflix film. Later, we'll explain how special security precautions built into the most basic layer of CCN make it possible to securely copy and store content in this way.
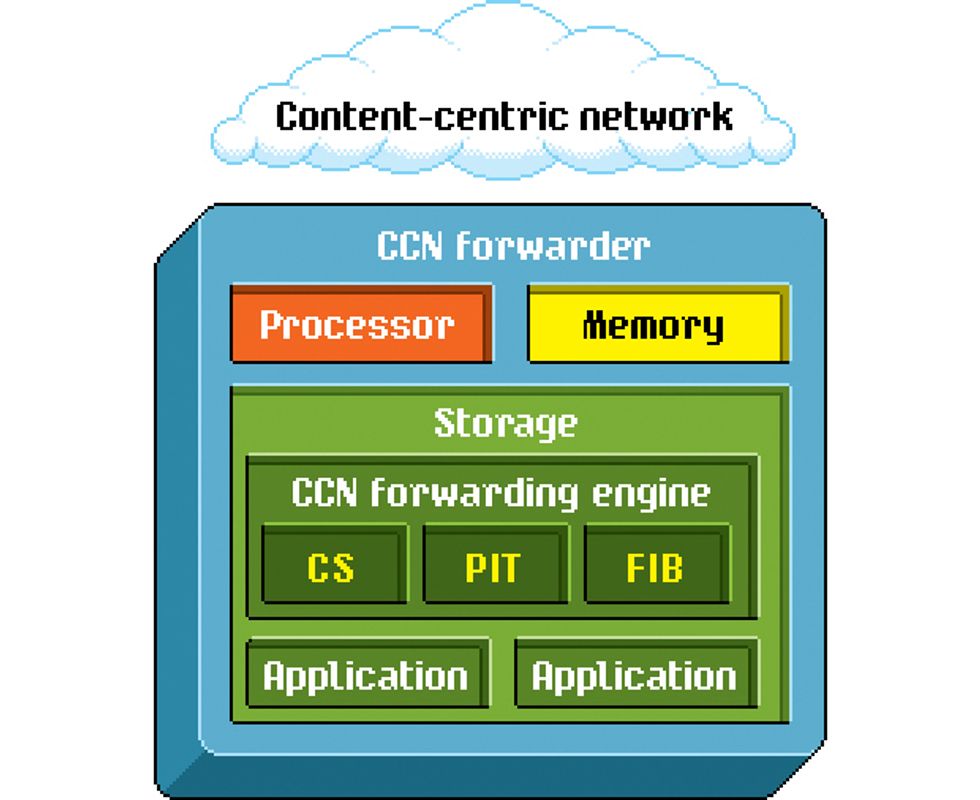 Illustration: QuickHoney
Illustration: QuickHoney
Power to the Node
Servers and routers can find content packets located anywhere on a CCN network by consulting two specialized tables: the pending interest table and the forwarding information base. The FIB lists where content is currently stored, while the PIT traces how past requests were forwarded. Nodes can also pluck content packets they've cached in their own content store (CS) to satisfy requests.
To return to our example, if the forwarder finds the content it's looking for in the node's content store, the system sends that content packet back to the user through the same “face," or gateway, by which the interest packet entered the system. However, when an interest packet arrives, that node might not hold a copy of the needed content in its content store. So for its next step, the forwarding engine consults the pending interest table, a logbook that keeps a running tally of all the interest packets that have recently traveled through the node and what content they were seeking. It also notes the gateway through which each interest packet arrived and the gateway it used to forward that content along.
By checking the pending interest table (PIT) whenever a new interest packet arrives, the forwarding engine can see whether it has recently received any other interest packets for the same—or similar—content. If so, it can choose to forward the new interest packet along the exact same route. Or it can wait for that content to travel back on its return trip, make a copy, and then send it to all users who expressed interest in it.
The idea here is that these PIT records create a trail of bread crumbs for each interest packet, tracing its route through the network from node to node until it finds the content it's seeking. This is very different from conventional networks, where routers immediately “forget" information they've forwarded. Then, that forwarder consults the PIT at each node to follow the reverse path back to the original requester.
Suppose, though, that an interest packet arrives at a node and the forwarding engine can't find a copy of the requested content in its content store, nor any entry for it in the pending interest table. At this point, the node turns to the forwarding information base—its last resort when trying to satisfy a new request.
Ideally, the forwarding information base (FIB) is an index of all the URI prefixes, or routable destinations, in the entire network. When an interest packet arrives, the forwarding engine checks this index to find the requested content's general whereabouts. Then it sends the interest packet through whatever gateway will move it closer to that location and adds a new entry to the pending interest table for future reference. In reality, the FIB for the entire Internet would be too large to store at every node, so just like today's routing tables, it is distributed throughout the network.
In a traditional network, routers perform a similar search to find the IP address of the server that holds the bits of information a user wishes to retrieve and figure out which gateway to send the request through. The difference here is that with CCN, the forwarding information base finds the current location of the information itself on the network rather than the address of the server where it's stored.
By focusing on the location of content rather than tracking down the address of its original host, a CCN network can be more nimble and responsive than today's networks. In fact, our studies indicate that the CCN model will outperform [PDF] traditional IP-based networks in three key aspects: reliability, scalability, and security.
CCN improves reliability by allowing any content to be stored anywhere in the network. This feature is particularly useful in wireless networks at points where bit-error rates tend to be high, such as when data is transmitted from a smartphone to a cell tower, or broadcast from a Wi-Fi access point. Current Internet protocols leave error recovery to higher levels of the protocol stack. By keeping a copy of a content packet for a short while after sending it along, a CCN node reduces the upstream traffic for packets that need to be retransmitted. If a packet fails to transmit to the next node, the previous node does not need to request it again from the original host because it has its own copy on hand to retransmit.
The pending interest table can also make it easier for networks to scale. By grouping similar interest packets together, it can reduce the bandwidth needed to satisfy each request. Instead of sending a new request back to the original host for each identical interest packet that arrives, a node could satisfy all those requests for interest packets with identical copies of the content it has stored locally. If the record shows that there has been a lot of demand for a viral cat video, the algorithms within that node may prompt it to keep an extra copy of all those packets in its content store to more quickly satisfy future requests.
Boosting reliability and making it easier to scale networks are two important benefits. But to us, the most important advantage of CCN is the extra security it offers. In traditional networks, most security mechanisms focus on protecting routes over which information travels (similar to the strategies used in early circuit-switched telephone networks). In contrast, CCN protects individual packets of information, no matter where they flow.
Currently, two users can establish a secure connection through established Internet protocols. The two most common of these are HTTPS and Transport Layer Security. With HTTPS, a user's system examines a digital certificate issued by a third party, such as Symantec Corp., to verify that the other user is who she claims to be. Through TLS, users negotiate a set of cryptographic keys and encryption algorithms at the start of each session that they both use to transfer information securely to each other.
With CCN, every content packet is encrypted by default, because each content packet also comes with a digital signature to link it back to its original creator. Users can specify in their interest packets which creator they would like to retrieve content from (for example, Netflix). Once they find a content packet with that creator's matching signature, they can check that signature against a record maintained by a third party to verify that it is the correct signature for that piece of content.
With this system in place, creators can allow other users to copy and store their content, because packets will always remain encrypted and verifiable. As long as users can verify the signature, they know that the content packet originated with the creator and that users can securely access the content—a motion picture, say—from anywhere it happens to be.
This security feature brings another bit of good news: Distributed denial-of-service attacks—in which hackers send a large volume of requests to a website or server in order to crash it—are more difficult to execute in CCN. Unusual traffic patterns are easier to discern in a CCN network and can be shut down quickly. On the other hand, clever attackers may just try to figure out a way to flood the network with interest packets instead. This security challenge would have to be solved before CCN could be widely adopted.
Another significant challenge [PDF] is figuring out how to integrate CCN's protocols into routers running at the speeds used on current networks. Analysts are especially concerned that routers in a CCN system would have to store rather large FIB and PIT tables to track the many moving content objects on the network, which will present major computational and memory-related challenges. However, researchers are now working on this problem at Cisco, Huawei, PARC, and Washington University in St. Louis, which have all demonstrated prototype routers supporting various elements of the CCN protocols.
Meanwhile, researchers elsewhere are drawing up their own protocols for alternative versions of CCN. These groups have built similar architectures called CCN-lite and Named Data Networking, with the support of the University of Basel, in Switzerland, and the National Science Foundation. All of these projects, along with the PARC software, are part of the broader field known as information-centric networking (ICN), which includes other research not directly related to CCN about redrawing the Internet's architecture.
One project worth mentioning is the GreenICN research program, led by Xiaoming Fu of the University of Göttingen, in Germany, in conjunction with more than a dozen universities and companies. That program explores the use of new technologies, including PARC's open-source CCN software, to create more robust networks to be rapidly deployed following a natural disaster. Fu and his colleagues took advantage of CCN's ability to operate independently of any private network and better manage limited energy resources. The group demonstrated a prototype network in early 2016.
From its earliest days, no one could have predicted what the Internet would become. Now that we have more than 45 years of knowledge about how people behave online, we want to build the next generation of the Internet to be even better than the last. We believe that early commercial deployments of CCN will be carried out, probably next year, on private networks meant for video distribution or financial transactions, where the numbers of users, forwarders, and caches can be carefully controlled.
It is hard to predict the future of today's Internet at its middle age. But consider this: In 1876, Western Union passed up the chance to purchase all of Alexander Graham Bell's telephone patents and, in an internal memo, stated that [PDF] “the 'telephone' has too many shortcomings to be seriously considered as a means of communication."
The pace of technological change has accelerated dramatically since the early days of the telephone, so it's hard to imagine a 125-year run for our current Internet technologies. With CCN, the Internet could begin its evolution into a faster and more secure service that billions more users can rely on for decades to come.
This article appears in the April 2017 print issue as “The Packet Protector."
About the Authors
Glenn Edens served as a vice president at the Palo Alto Research Center in California for four years, where he oversaw the organization's pioneering work on content-centric networking. He is now chief technology officer of TecReserve, a consulting company. Glenn Scott worked with Edens as PARC's manager of networking architectures and has since become a distinguished engineer at Intuit.
From Your Site Articles


