
Back in the 1980s, parallel computing pioneer Gene Amdahl hatched a plan to speed mainframe computing: a silicon-wafer-sized processor. By keeping most of the data on the processor itself instead of pushing it through a circuit board to memory and other chips, computing would be faster and more energy efficient.
With US $230 million from venture capitalists, the most ever at the time, Amdahl founded Trilogy Systems to make his vision a reality. This first commercial attempt at “wafer-scale integration” was such a disaster that it reportedly introduced the verb “to crater” into the financial press lexicon. Engineers at University of Illinois Urbana-Champaign and at University of California Los Angeles think it’s time for another go.
At the IEEE International Symposium on High-Performance Computer Architecture in February, Illinois computer engineering associate professor Rakesh Kumar and his collaborators will make the case for a wafer-scale computer consisting of as many as 40 GPUs. Simulations of this multiprocessor monster sped calculations nearly 19-fold and cut the combination of energy consumption and signal delay more than 140-fold.
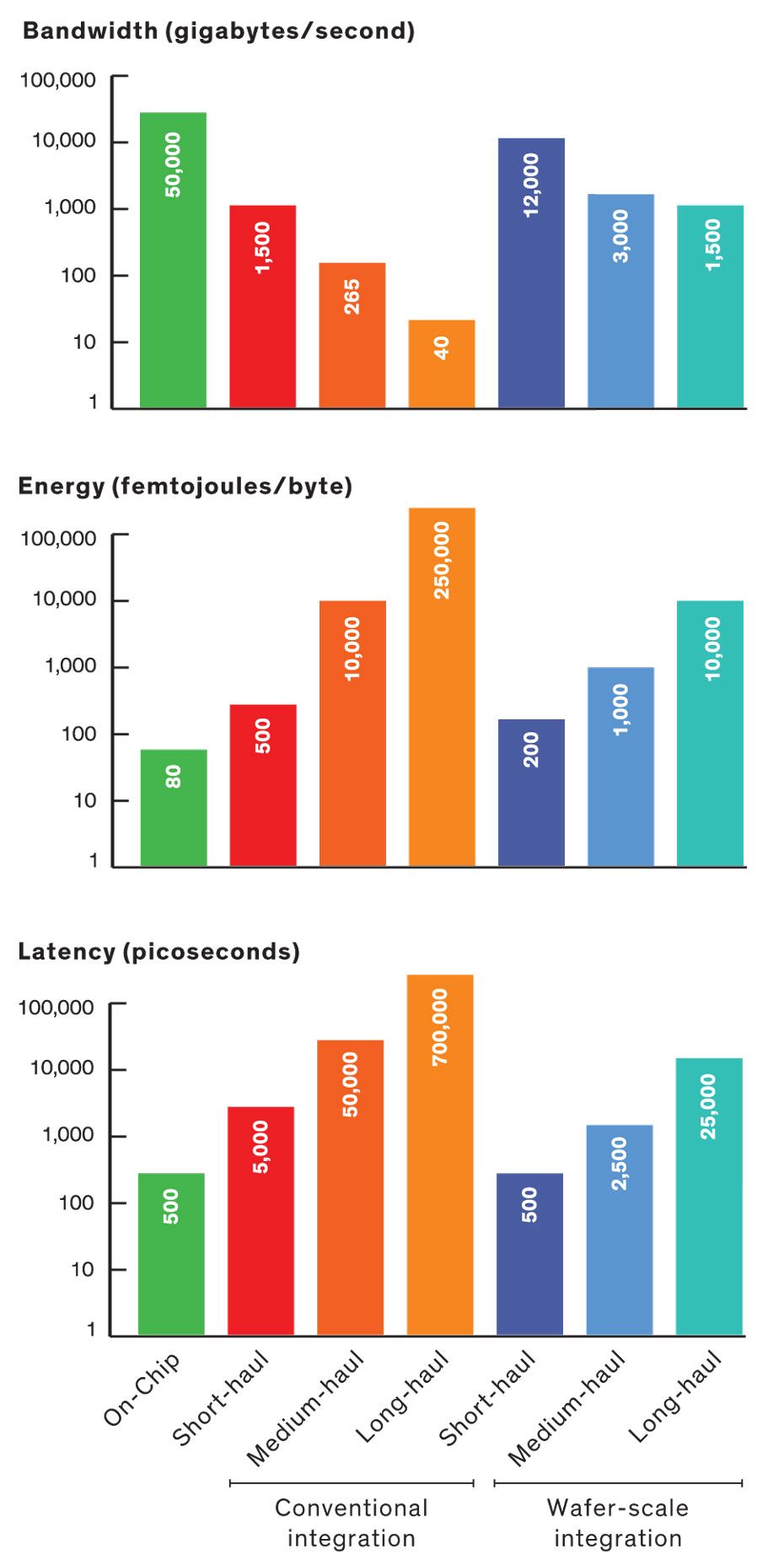
“The big problem we are trying to solve is the communication overhead between computational units,” Kumar explains. Supercomputers routinely spread applications over hundreds of GPUs that live on separate printed circuit boards and communicate over long-haul data links. These links soak up energy and are slow compared to the interconnects within the chips themselves. What’s more, because of the mismatch between the mechanical properties of chips and of printed circuit boards, processors must be kept in packages that severely limit the number of inputs and outputs a chip can use. So getting data from one GPU to another entails “an incredible amount of overhead,” says Kumar.
What’s needed are connections between GPU modules that are as fast, low-energy, and as plentiful as the interconnects on the chips. Such speedy connections would integrate those 40 GPUs to the point where they act as one giant GPU. From the perspective of the programmer, “the whole things looks like the same GPU,” says Kumar.
One solution would be to use standard chip-making techniques to build all 40 GPUs on the same silicon wafer and add interconnects between them. But that’s the philosophy that killed Amdahl’s attempt in the 1980s. There is always the chance of a defect when you’re making a chip, and the likelihood of there being a defect increases with the size of the chip. If your chip is the size of a dinner plate, you’re almost guaranteed to have a system-killing flaw somewhere on it.
So it makes more sense to start with normal-sized GPU chips that have already passed quality tests and find a technology to better connect them. The team believes they have that in a technology called silicon interconnect fabric (SiIF). SiIF replaces the circuit board with silicon, so there is no mechanical mismatch between the chip and the board and therefore no need for a chip package.
The SiIF wafer is patterned with one or more layers of 2-micrometer-wide copper interconnects spaced as little as 4 micrometers apart. That’s comparable to the top level of interconnects on a chip. In the spots where the GPUs are meant to plug in, the silicon wafer is patterned with short copper pillars spaced about 5 micrometers apart. The GPU is aligned above these, pressed down, and heated. This well-established process, called thermal compression bonding, causes the copper pillars to fuse to the GPU’s copper interconnects. The combination of narrow interconnects and tight spacing means you can squeeze at least 25 times more inputs and outputs on a chip, according to the Illinois and UCLA researchers.
Kumar and his collaborators had to take a number of constraints into account in designing the wafer-scale GPU including how much heat could be removed from the wafer, how the GPUs could most quickly communicate with each other, and how to deliver power across the entire wafer.
Power turned out to be one of the more limiting constraints. At a chip’s standard 1-volt supply the SiIF wafer’s wiring would consume a full 2 kilowatts. Instead Kumar’s team boosted the voltage supply to 48 volts, reducing the amount of current needed and therefore the power lost. That solution required spreading voltage regulators and signal conditioning capacitors around the wafer, taking up space that might have gone to more GPU modules.
Still, in one design they were able to squeeze in 41 GPUs. They tested a simulation of this design and found it sped both computation and the movement of data while consuming less energy than 40 standard GPU servers would have.
The SiIF waferscale GPU “overcomes the problems that the early waferscale work was not able to solve,” says Robert W. Horst of Horst Technology Consulting in San Jose, Calif. More than two decades ago at Tandem Computers, Horst was involved in creating the only waferscale product ever commercialized, a memory system used in place of fast hard drives in stock exchanges. He expects that cooling will be one of the most challenging aspects. “If you put that much logic in that close proximity, the power dissipation can be pretty high,” he says.
Kumar says the team has started work on building a wafer-scale prototype processor system, but he would not give further details.
A version of this post appears in the March 2019 print issue as “A Chip Design With 40 GPUs.”