
At Arm TechCon today, West Lake Village, Calif.–based startup Eta Compute showed off what it believes is the first commercial low-power AI chip capable of learning on its own using a type of machine learning called spiking neural networks. Most AI chips for use in low-power or battery-operated IoT devices have a neural network that has been trained by a more powerful computer to do a particular job. A neural network that can do what’s called unsupervised learning can essentially train itself: Show it a pack of cards and it will figure out how to sort the threes from the fours from the fives.
Eta Compute’s third-generation chip, called TENSAI, also does traditional deep learning using convolutional neural networks. Potential customers already have samples of the new chip, and the company expects to begin mass production in the first quarter of 2019.
Neural networks are essentially a group of nodes having values called “weights” and connections to other nodes. The combination of connections and weights is the intelligence that can tell a slug from a snake in a photo or the word “slug” from the word “snake” in a spoken sentence. In convolutional neural networks (the “deep learning” kind), these weights are often 8- or 16-bit numbers. But in spiking neural networks, they’re all just 1s or 0s. In consequence, the key neural network operation—multiply and accumulate—becomes mostly addition, reducing the amount of computation and therefore the power consumed. “It’s a much more simple operation,” says Paul Washkewicz, cofounder and vice president of marketing.
Another difference is that while the nodes in a convolutional neural network tend to be densely connected, the connections for spiking networks wind up being quite sparse. The combination of a sparse network and less complex math means it takes less data and time to come to an answer. For example, to recognize the cheetah seen in the photo in the video below, a CNN needs 100,000 pixels; the spiking neural network needs less than 1,000.

“One of the holy grails of machine learning is unsupervised learning,” says Washkewicz. Usually, networks are trained on hundreds or thousands of labeled examples of what they’ll need to recognize in the real world. For an embedded system, the resulting set of weights and connections is then programmed onto the chip. “When you talk about the democratization of machine learning and getting regular engineers and computer scientists involved in IoT, you need to be able to make the training [of networks] simpler.”
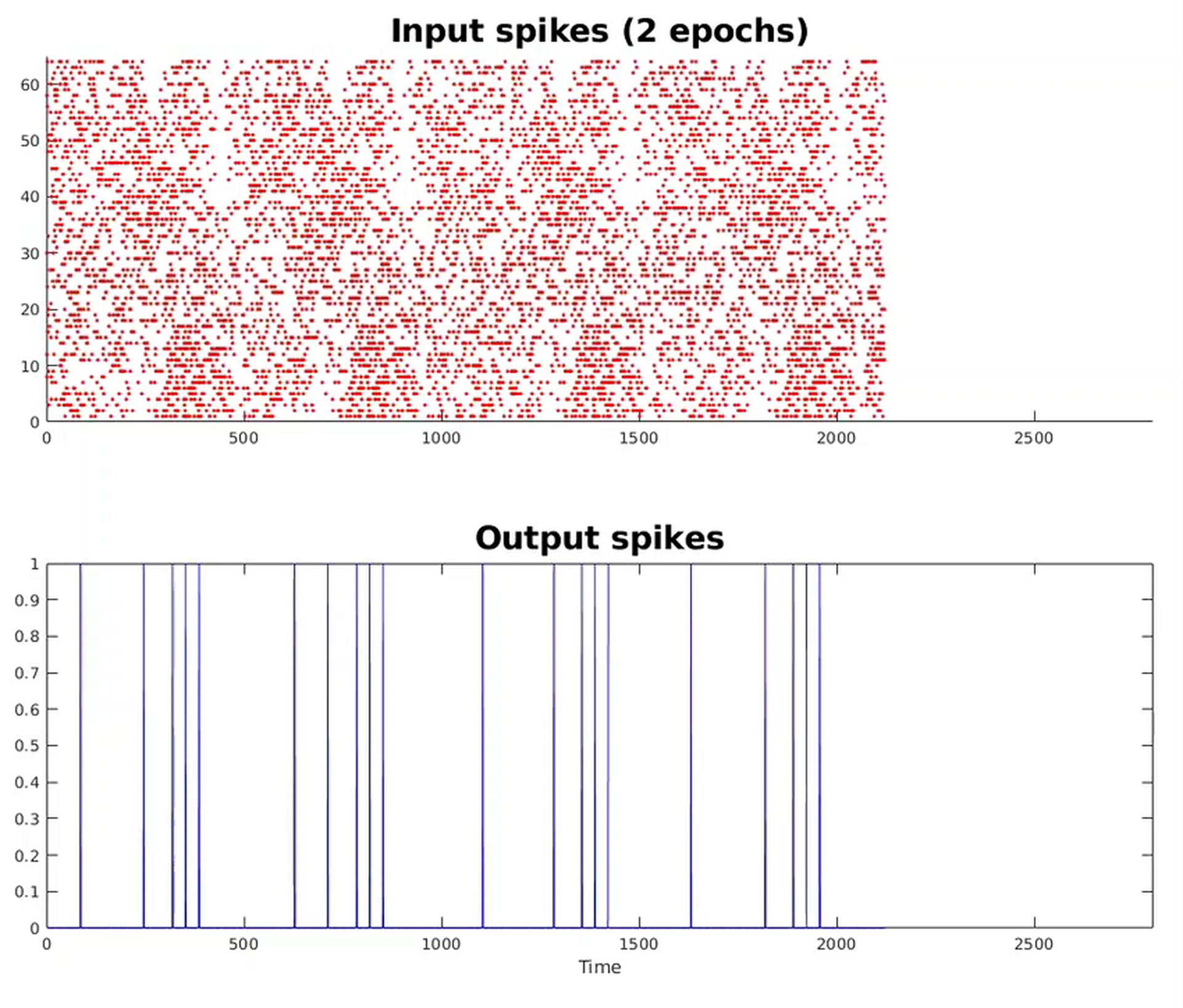
Because their structure includes feedback, spiking neural networks are capable of training themselves even without a labeled set of data. In the example Eta Compute provided, the network trained itself to recognize the word “smart,” correctly ignoring the words “yellow” and “dumb” once it had done so. [see video below]
The TENSAI chip consists primarily of an Arm M3 core and an NXP CoolFlux digital signal processor core. The DSP has two arrays dedicated to doing deep learning’s main computation—multiply and accumulate. These cores are implemented in a manner that’s called asynchronous subthreshold technology. It allows them to operate at as low as 0.2 volts (compared with the 0.9 V most chips use), and with a clock period that can be scaled up or down to suit the computational need. The feat required a good deal of analog design work, even for the digital parts, says Washkewicz. “We spent a lot of engineering time on analog; it’s a source of advantage.”
The result is a chip that Eta Compute believes will be miserly enough to listen out for “wake words” in battery-operated audio devices. In such a system, it might burn just 50 microwatts in listening mode and only jump to 500 microwatts when fully awake.


