
This is part of IEEE Spectrum's special report: Always On: Living in a Networked World.
Supercomputers to date have been accessible to only a few fortunate specialists. But a new era will use high-speed data networks to link the huge beasts to more and more researchers' desktops, and just as important, to link individual supercomputers together. These new networks, or grids, are needed to grapple with incredible volumes of data and in turn promise better and cheaper science.
Supercomputers are a varied bunch, each with different strengths and weaknesses, but by uniting their resources, users can pick the computational approach most effective for the task in hand. The creation of these grids requires more than high-bandwidth connections—novel organizations, novel management, and novel service software are also essential.
The huge amounts of data being generated by researchers today need the brute force capacity of a supercomputer network. Consider that particle accelerators can produce data streams on the order of 100 MB/s while the Sloan Digital Sky Survey is generating about 10 TB of data a year in its bid to map the heavens [see " Networked Supercomputing Applications"]
With grids, massive amounts of communal data can be stored and processed independently of individual research groups and on the most appropriate resources.
Grids also encourage better analyses. Tom Prudhomme, at the National Center for Supercomputing Applications (NCSA) at the University of Illinois at Urbana-Champaign, is a principal investigator for the Network for Earthquake Engineering Simulation (NEESgrid), which will create a virtual laboratory for advanced earthquake research. "The tendency of scientists and engineers is to scope the problem to the computers available," Prudhomme explained. "For a very complicated problem, you'll make some a priori assumptions to simplify it so that it can run in a reasonable amount of time...[but with a grid] you can say 'not only have I access to the computer power I need, but the data I need to run this are also available.'" With NEESgrid, terabytes of data will be pulled through a model calculation, independent of the user's local resources.
Big science, big data
Prudhomme noted that high-performance computing centers are home not just to supercomputers, but also to huge data storage facilities. "A data repository is as much a high-performance function as a high-performance computer is," he said.
Large-scale data storage and access also concerns Julian Bunn, of the Globally Interconnected Object Databases (GIOD) project at the California Institute of Technology's Center for Advanced Computing Research, in Pasadena. GIOD is targeted at the data that will stream out from the new Large Hadron Collider, at the European Organization for Nuclear Research (CERN) in Geneva, Switzerland.
"The data model is obviously one very important aspect of making this work...[we want to] optimize how the data are laid out in the network as well as on storage devices," said Bunn. Data is distributed around the grid, so that it is close at hand when needed for processing, reducing network demands.
Matching needs to resources
Managing data is only half the story. Grids must also juggle user needs with available resources. So, GIOD is developing a matchmaking service. Users submit tasks to the service, which, Bunn continued, is aware of all the resources available in the network, including your "allocation of time [on individual machines] and the prevailing network conditions."
The matchmaking service relies upon grid middleware, which tracks network conditions, the location of data, and available resources, and provides a standard interface for accessing computational resources and data.
One promising approach to grid middleware is Globus, being developed by a team led by Carl Kesselman of the University of Southern California, Marina del Rey, and Ian Foster of the Argonne National Laboratory, Argonne, Ill., and the University of Chicago.
The Globus middleware is a set of low-level protocols for resource access and connectivity. Once in place, "it becomes feasible to start building resource brokering and discovery services and distributed data management services of various sorts," said Foster. Resource broker software determines the specific demands a task will place on a grid—bandwidth, number of processing nodes, and so on—and sends requests to the relevant resources. This arrangement shields users and client applications from having to deal with a grid's full complexity.
One of the most ambitious grids to date is the Grid Physics Network (GriPhyN), a collaboration funded by the National Science Foundation, Arlington, Va. It will use automatic resource brokers capable of dealing with both computational and data resources. Foster is also one of two principal investigators with the GriPhyN project, the other being Paul Avery at the University of Florida in Gainesville. GriPhyN is expected to perform over 120 trillion floating-point operations per second.
To reach those performance levels, thousands of computers worldwide (not just supercomputers) will have to be coupled, so one possibility is harnessing commercial distributed computing services that parcel out work to individual workstations (rather as in Seti@home's analysis of radio telescope data to search for extreterrestial intelligence). Foster observed: "The sheer number of components and the volume of data introduce resource management, scheduling, and fault tolerance problems that are beyond the state of the art."
From both the computational and data aspects of GriPhyN, the concept of "virtual data" is emerging. Researchers tend to think of data derived from raw data as different from original data. Virtual data puts both on an equal footing. When asked a question, the grid determines if the answer can be constructed from already derived results stored somewhere else or if follow-up computation is required on original data. In either case, the user remains ignorant of all the behind-the-scenes activity. This also allows for frequently performed analyses to be stored in local or regional caches, rather than computed from scratch each time [see figure below].
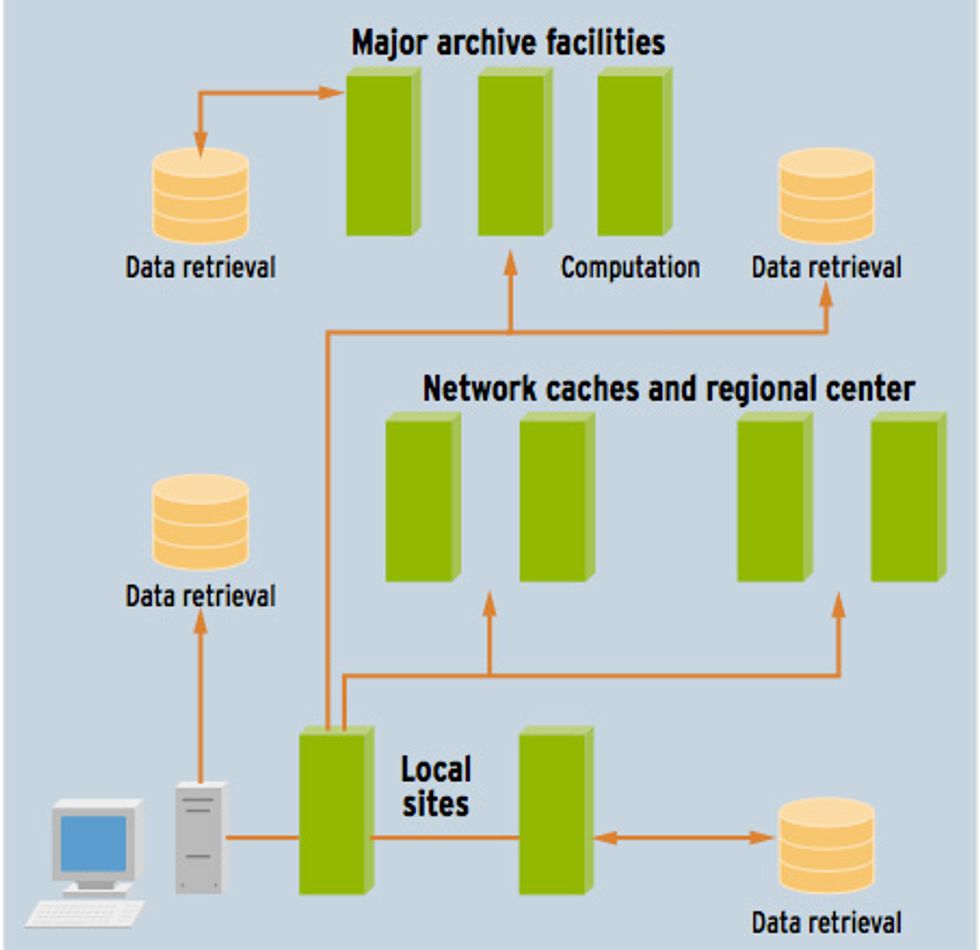
Strategic value
The substantial infrastructure required to create grids--ultrahigh-bandwidth connections, management organizations, and specialized software development—is seen as not just a boon to researchers, but also as a strategic resource to the governments footing the bill. Dai Davies is the general manager of Dante, the Cambridge, UK, company charged with planning, building, and running advanced network services for the European research community. Dante is currently planning Géant, a pan-European gigabit-per-second network.
Said Davies: "The telecommunications industry in Europe [has] been significantly held back by the lack of infrastructure." This infrastructure deficiency is not the absence of physical infrastructure, but rather the lack of a straightforward means of creating end-to-end connections--not so long ago, linking London and Berlin meant dealing with every national monopoly in between. With deregulation, logistics have become much simpler and more cost-effective. An experimental platform, consisting of demanding grids using high-bandwidth connections, enables a lot of curious engineers to develop the European telecommunications infrastructure on a regional level, rather than being limited to a national level. "In terms of the development of science and research within Europe, [it's] much more cost-effective [to cooperate]," Davies continued. "[This] strengthens the European economic position by making resources much more efficient."
Much work remains and not just on the technical side. Policy decisions and work practices will have to be developed to allocate local resources to a grid and to resolve friction between institutions. But networked supercomputing will mature as enabling software technologies take off and bandwidth grows. These grids will form a part of researchers' toolkits for attacking a wide variety of challenging problems, from genetic engineering to car design.
To Probe Further
More can be learned about the ambitious Grid Physics Network project at https://www.griphyn.org.
Information on the Globally Interconnected Object Databases (GIOD) project, which is to cope with the output pf CERN's Hadron Collider, is available at https://pcbunn.cacr.caltech.edu.
Similarly for Dante, the British company charged with developing advanced network services for European researchers, check out https://www.dante.org.uk.