
Bothered by how quickly recording video drains your smartphone battery? There’s no app for that—but there may soon be a chip. Researchers at Sony and Stanford have constructed an imaging chip that incorporates a new technology called compressed (or compressive) sensing, to radically reduce battery drain by compressing video frames before they’re digitized.
The problem with mobile video is this: Recording an image requires analog-to-digital conversions—lots of them. And each conversion consumes some energy. For a single conversion, it’s not much, say a hundredth of a microjoule. But suppose your phone has an image sensor of 1080 by 1920 pixels. To capture one image, it must complete nearly 2.1 million conversions. So you need to multiply the energy of each A-to-D conversion by 2.1 million and then multiply the result by the number of video frames you capture—thousands for all but the shortest clips. A billion conversions here, a billion conversions there, and pretty soon you’re talking about real battery drain.
But consider what happens next: The raw digital pixel values are compressed into a more compact format, perhaps a JPEG file for an individual image or an MPEG-4 file for video. Most images compress down by a factor of 15 without loss of significant detail, so few cameras do anything with the raw image data. Why then spend the time, trouble, and energy collecting all that information in the first place, if you’re going to throw more than 90 percent of it away?
Up until recently, the answer has been that you can’t figure out how to compress a signal until you have that signal. If you try to sample it too coarsely, you’d run afoul of the Nyquist-Shannon sampling theorem, which states that you can’t capture a signal properly unless you sample it at least twice per cycle of the highest frequency component it contains. But it turns out that Harry Nyquist, who first formulated this idea in the context of telegraph transmissions—and, later, information-theory pioneer Claude Shannon—had missed something.
Perhaps the easiest way to understand their oversight is by recalling those old brain teasers: How can you use a balance scale to find one ball in a larger set that’s slightly heavier (or lighter) than the others using the fewest possible weighings? Answer: Rather than weighing one ball at a time, you weigh selected groupings to infer which ball is the odd one.
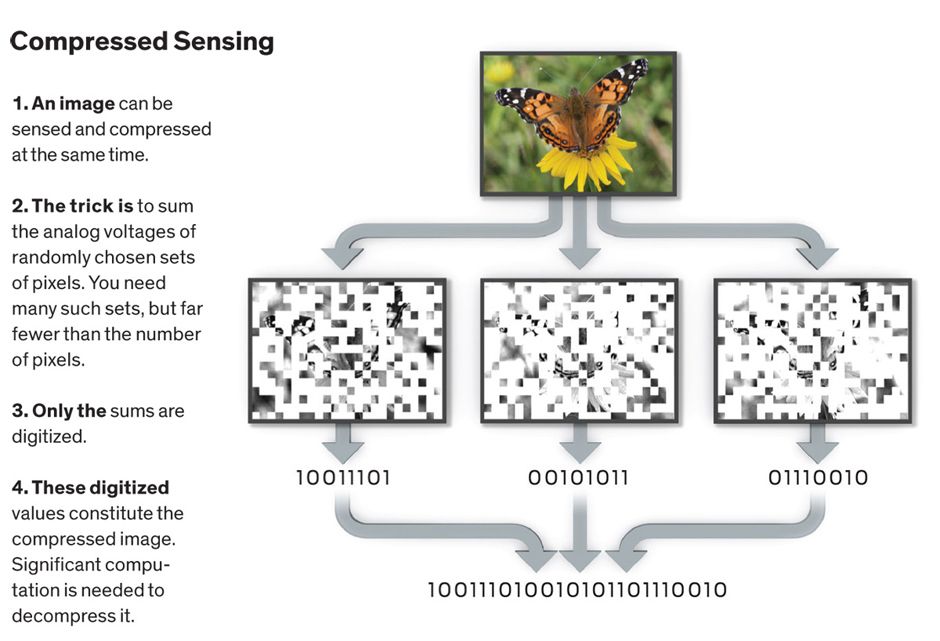
Most images don’t have just one pixel that’s different from all the others. But it turns out that compressing images isn’t all that much more challenging than finding that wonky ball. You merely pick random combinations of pixels and sum their intensities. Amazingly enough, with a sufficient number of such measurements (but far fewer than the number of pixels), you’ll have enough data to reproduce the original image.
This astonishing result came out of work that Emmanuel Candès and David Donoho (both at Stanford), Justin Romberg (now at Georgia Tech), and Terence Tao (University of California, Los Angeles) began in 2004. Since then, scientists and engineers in many disciplines have been looking to apply compressed sensing to other problems—typically ones where the sensor arrays are difficult or expensive to fabricate. That’s why Austin, Texas–based InView Technology Corp., for example, is applying compressed sensing to shortwave infrared imagery. Visible-light imaging arrays don’t have this problem. But as Yusuke Oike of Sony and Abbas El Gamal of Stanford realized in 2010 and 2011, when Oike was a visiting scholar at Stanford, the many A-to-D conversions they require consume more energy than smartphone designers would like.
At the time, El Gamal was involved in neurobiology research, examining the nerve cells of live, free-ranging mice by staining the cells with fluorescent dyes and attaching image sensors to the animals’ brains. “We had a very small power budget on the head of a mouse,” he says. And they knew that the power problem was more general. For example, power constraints limit the resolution of image sensors in endoscopic surgical instruments, El Gamal says: “Otherwise it burns your stomach.” The most widespread opportunity for such power savings, though, is in our phones.
To explore how compressed sensing could help, Oike and El Gamal designed a custom CMOS chip with a 256- by 256-pixel image sensor. That chip also contains associated electronics that can sum random combinations of analog pixel values as it’s making its A-to-D conversions. The digital output of this chip is thus already in compressed form. Depending on how it’s configured, the chip can slash energy consumption by as much as a factor of 15.
The chip is not the first to perform random-pixel summing electronically, but it is the first to capture many different random combinations simultaneously, doing away with the need to take multiple images for each compressed frame. This is a significant accomplishment, according to other experts. “It’s a clever implementation of the compressed-sensing idea,” says Richard Baraniuk, a professor of electrical and computer engineering at Rice University, in Houston, and a cofounder of InView Technology.
But don’t expect to see it in Apple’s next iPhone. The biggest stumbling block is decompressing the image. The algorithms used for that require considerable computational horsepower—much more than would be available on a phone. “You’d have to do the reconstruction in the cloud,” says El Gamal. Decompressing thousands of these videos every day would only exacerbate the demands our mobile lives are already placing on data centers and, in turn, on energy grids. Where will we find the power for all that, Siri?
This article originally appeared in print as “New Camera Chip Captures Only What It Needs.”