The Conversation (0)

Illustration: Gold Standard Simulations
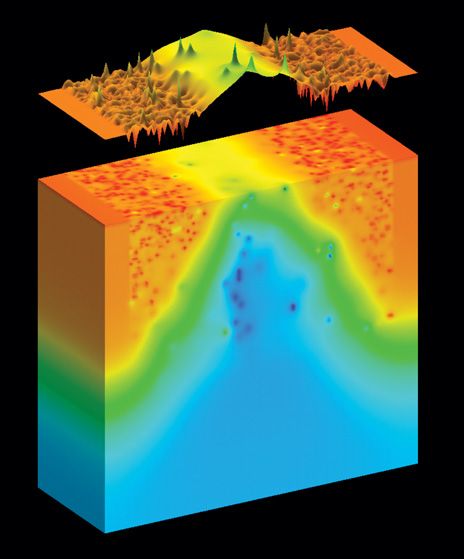
Image:
Gold Standard Simulations
Tough Terrain: Atom-level variations in devices can no longer be ignored.
Click on image to enlarge.
Today’s chips are marvels of mass production. Tens of thousands of silicon wafers can move through a single fab in a month, each one carted from tool to tool, blasted by heat, bombarded by ions, immersed in vapor, coated with chemicals, hit with radiation, and exposed to acid. It can take months and hundreds of steps to transform a plain piece of silicon into an array of chips. But at the end of this elaborate assembly line, chipmakers finally get a pile of identical devices that perform just as their designers intended.
At least that’s how it used to be. Then, about 10 years ago, chipmakers began to notice a problem: Even state-of-the-art manufacturing processes couldn’t produce chips with consistent properties. Nowadays two transistors, fabricated a few dozen nanometers apart on the same piece of silicon, will not have the same electrical properties. It’s one of the key barriers that the global chip industry—with sales of US $300 billion—must overcome to keep producing better, faster, cheaper, more energy-efficient chips.
The culprit is scaling. Chips have improved because their transistors and connecting wires have kept getting smaller, but now they’re so small that random differences in the placement of an atom can have a big impact on electrical properties. Some batches vary so much that more than half will run 30 percent slower than intended or consume 10 times as much power as they should when on standby.
Some of these defective chips can be sold at a discount, but if they’re for application-specific designs—say, for mobile phone communication or video encoding—they might find no better destination than the junkyard. And the defect rate will only get worse as transistors continue to shrink.
Chip variability is what the International Technology Roadmap for Semiconductors calls a “red brick” problem: one of a handful of important issues that lack any clear solution, forming a red brick wall that prevents forward progress.
But just because variability is here to stay doesn’t mean we can’t mitigate its effects. We could accomplish much by changing the way we design chips. This has traditionally been done by introducing a margin of error to account for the worst-case scenario. Now that ridiculously small defects have entered the mix, that approach no longer works, and chipmakers must overcompensate for the problem. The result is pessimistically designed chips that operate far slower and consume far more energy than they should.
Fortunately, a new family of design techniques promises to predict not only the worst-case scenario for a chip but also the likelihood that the scenario will happen. These approaches use statistical methods to make informed trade-offs between how fast the chips will run and how many good chips a given batch is likely to yield. Some makers of high-end microprocessors like IBM and foundries like the Taiwan Semiconductor Manufacturing Co. are already using some of these statistical techniques in their design flows. Although statistical tools are still far from being widely adopted, if we can push them along, these tools will help us make affordable chips that are as fast and efficient as those the semiconductor road map calls for—and perhaps then some.

Image: IMEC
Rough Going: These uneven rows of exposed photoresist, created using extreme ultraviolet light, will become 30-nanometer-long transistor gates.
Click on image to enlarge.
Variation has been present since the first integrated circuit was created. But its nature and scope—and the way it shows up in the behavior of digital circuits—have changed.
For a long time, most variation was global, caused by slight alterations in the manufacturing process. Such changes differentiate one chip from another or all the chips on one wafer from those on another. Global variations tend to affect the electrical characteristics of all transistors in the same, albeit unpredictable, way. For example, the light coming from a lithography tool that’s used to print devices can be distorted by slight changes in optics from exposure to exposure, creating transistors that are slightly longer—and thus slower—than intended. Fluctuating environmental conditions can also create variation. If the temperature in a vapor deposition chamber drops too low, for instance, it can slow the growth of the insulating layer of oxide in a transistor. The resulting thin insulator can leave transistors a bit leakier than normal. But over the past few decades, chipmakers have been able to keep global variation under control by steadily improving manufacturing tools and manufacturing process control.
A second source of variation is often called local process variation or process variability, and it is proving far more difficult to address. It started appearing in digital circuits about 10 years ago, when chipmakers began producing transistors with channels less than 90 nanometers long, the span of a few hundred silicon atoms. At that scale, the electrical properties of a transistor begin to be affected by random sources of variation, such as the roughness of a transistor’s edges or the granularity in the crystal of the metal electrode that turns a transistor on or off. Such variations have an independent effect on every transistor in any given integrated circuit. One transistor may end up being slower while its neighbor becomes speedier but also leaks more current.
One of the most dramatic sources of local process variation comes from dopants, the atoms of another material that are added to a silicon channel to speed up the switching of a transistor and, by extension, decrease the energy that switching consumes. Chipmakers typically add dopants by accelerating ions to high speeds and shooting them into a wafer. But this approach wasn’t designed for work on an atomic scale; it’s difficult to control how many atoms make it into a transistor and exactly where they fall. Transistor channels once contained tens of thousands of dopant atoms. Nowadays chipmakers produce transistors that can accommodate only a few hundred of them. And in that case, the absence of a single atom is much more noticeable and can alter how much voltage is needed to turn a transistor on or off by a few percent.
The random, uncorrelated nature of these variations poses a problem for circuit designers. Link up many such transistors in an integrated circuit, with its sensitive dependencies and timing requirements, and the variabilities can magnify one another: The resulting system may be even more randomly variable than its parts. Nor can you accommodate local variation by using hand-me-down tools developed to tackle global variation. We need a new approach.
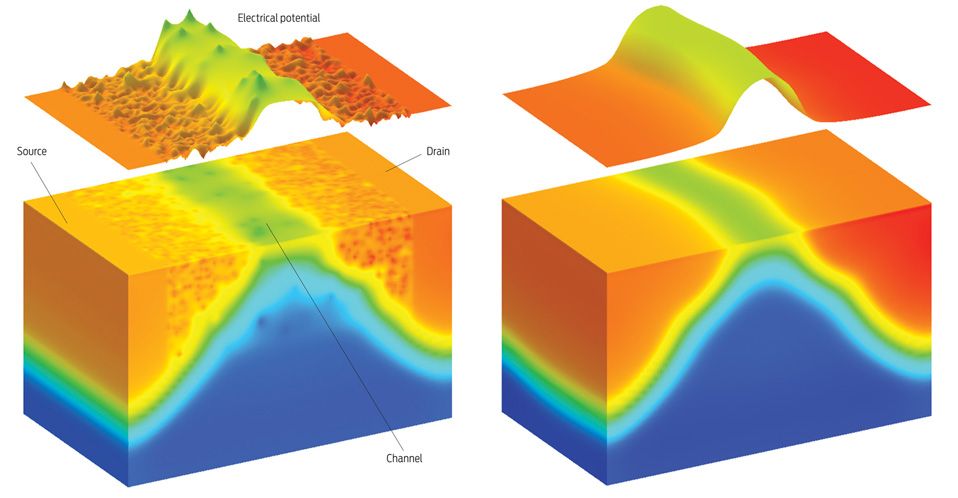
Image:
Gold Standard Simulations
Dots and Lines: As transistors get smaller, random fluctuations in dopant location and concentration [left block] and the roughness of circuit features [right block] have a stronger impact on transistor properties. Both factors result in less than ideal electrical potential profiles [shown above each block].
Click on image to enlarge.
First, though, let’s take a look at the long-standing strategy for tackling global variations. This approach relies on models that outline extreme process deviations—all the possible manufacturing scenarios for a chip. Fabs and foundries tend to measure these parameters on the production floor, by deliberately fabricating test chips that are way out of spec in one direction or another. Engineers then measure the electrical properties of the transistors on these extreme chips. The resulting set of specs—which can be represented using a square—is called a corner model.
The four corners of the model can help engineers anticipate how any circuit will behave. In one corner, both the positively and negatively doped field-effect transistors—pFETs and nFETs, respectively—are fast. In the other three corners you find the three other pairings: slow pFETS with slow nFETS, fast pFETs with slow nFETs, and slow pFETs with fast nFETs. Chipmakers and designers assume there is an equal chance that a circuit will fall into any one of these four corners.
This model breaks down, however, when circuits suffer strongly from local process variation. With process variability, every single nFET or pFET may operate either slower or faster than average, and the performance of one device will be completely uncorrelated with that of its neighbor. For most circuits, there will be far more than four possible behaviors, and not all of them will be equally likely. Because the number of combinatorial possibilities effectively grows exponentially with the number of devices in the circuit, the problem would challenge even the largest computing clusters—called compute farms—that chipmakers use to characterize their circuit libraries.
Consider the simplest digital circuit, an inverter, built using one pFET and one nFET. A single inverter would have four possible behaviors and thus a clear worst-case behavior. But combine two inverters in an integrated circuit and you’ll either double or quadruple the number of possible behaviors, depending on how they’re connected. The problem only gets worse as you scale up. One step up from the inverter in complexity is the NAND gate, which contains two nFETs and two pFETS and could take on 16 possible behaviors. A very simple arithmetic logic unit, the core logic circuitry at the heart of a CPU, can easily contain hundreds of transistors and require the analysis of trillions of combinations, each of which would take a few minutes to calculate. Today’s microprocessors easily contain more than a billion transistors, resulting in an effectively infinite number of combinations.
It turns out this exercise in combinatorics is more difficult for some sorts of circuits than for others. For a basic logic gate, it’s actually fairly easy to at least predict the worst-case scenario of a circuit. That’s because the pFETs and nFETs in logic are only on for a fraction of the time and never at the same time, making the calculations much easier. But that isn’t the case for the flip‑flop circuitry that’s interleaved throughout a processor and used to clock computations or for static RAM (SRAM) memory cells, which now easily take up half the space on a smartphone chip.
Even if it were easy to figure out the worst-case scenario, we wouldn’t be able to estimate how many such bad chips we’ll generally get in a batch. We can’t even say whether the chance of producing such a chip is one in a billion or just one in a thousand. Yet you need some guidelines of this sort to push the performance of your design as far as possible without reducing the yield to uneconomic levels. In the chipmaking business, there is no more unforgiving measurement than yield. It is what determines your break-even point, the point below which you might as well close shop.
Fortunately, we can get guidelines for yield even before the manufacturing process starts, something that was never really possible with the corner model. Since around 2005, a new class of circuit analysis tools based on statistics has let engineers anticipate an unacceptably low yield and introduce modifications that will make the final manufactured IC more robust, such as increasing the size of the transistors that cause most of the delay and variation in a circuit.
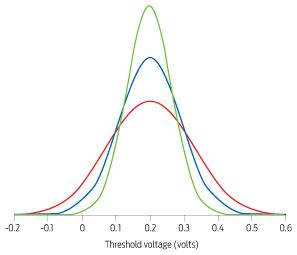
Data:
Asen Asenov
Widening Variability: The range of threshold voltages—those needed to turn a transistor on—is widening as circuit feature sizes shrink from 28 nanometers [green line] to 20 nm [blue] and 14 nm [red]. As feature sizes get smaller, an increasing fraction of transistors are made with threshold voltages at or below zero, which means they no longer operate as switches.
Click on image to enlarge.
So far, most of the effort in the digital realm has focused on revamping one of the core tools for logic design: static timing analysis. STA predicts the maximum operating frequency of an IC, which is determined by the longest time it takes a signal to propagate through logic gates. Nowadays, however, STA doesn’t work so well, since each chip will have its own delay, and some will be able to run quite a bit faster than others.
A statistical version of the STA tools, called SSTA, can be used to calculate not only the theoretical operating frequency of a design but also the probability that the manufactured version will in fact operate correctly at that frequency. This turns out to be fairly easy to calculate, because the delay in logic is almost always a linear operation and the computational power needed to handle the analysis is not excessive.
But SSTA is only as good as the data you supply to it. The tools need timing information based on statistics describing basic transistor variation. You could create such statistics by simply summing the effect of each source of variation on the behavior of a circuit, but the problem with such “sensitivity analysis” is that most sources of variation can’t be considered independently. If, for instance, a transistor’s channel is longer than expected, then more voltage will be needed to turn the transistor on. As a result, voltage and channel length are linked. If you add the variation from each source separately, you’ll effectively be counting the same effect multiple times, overestimating how much local process variation affects circuit timing.
The case is particularly bad for clocking circuitry: My colleagues and I calculated that sensitivity analysis overestimates timing delay, as well as two key measures of flip-flop performance, by a factor of two to three. Chipmakers who rely on this kind of analysis will end up overestimating how much they must widen transistors to increase current flow and thus the circuit speed. When the resulting processors are made, they’ll run 10 to 20 percent faster than expected, but they’ll also carry—and leak—more current than they should. For flip-flops, which are very active, switching every single clock cycle, the design choice will result in a lot of wasted power.
Another technique is CPU-intensive Monte Carlo analysis. This approach uses loops, each of which selects values at random for basic transistor properties and “injects” them into a transistor model, thus simulating the impact of local process variations. Once this is done, an electrical simulation of the circuit is performed. The process is repeated hundreds or thousands of times, with different random values every time. As you might imagine, the problem with this approach is the computer time it consumes. If a logic library is composed of, say, 1000 building blocks or logic gates and every block takes 3 seconds on average to simulate, a Monte Carlo loop of 1000 iterations would blow up the characterization time from the single hour needed to simulate a corner in traditional corner analysis on a CPU to more than a month.
Memory also turns out to be especially difficult to simulate. Statistical models tend to use a single SRAM bit to model the behavior of the entire memory chip. But memory is only as fast as its slowest bit. Bits are read in groups—or bytes—and each group must wait for all its bits to return values. Because a memory chip is basically composed of a grab bag of bits with different properties, it is all too likely that at least one of the billion or so bits will have an extremely long delay time. Although there are tricks that can help make Monte Carlo simulations speedier, statistical tools that can optimize memory are still lacking.

Image: IMEC
Imperfect Memory: This simulation of a 32-nanometer, 64-kilobit static RAM device illustrates the impact of local process variation. If there were no variation, all the cells in this graphic would be the same color.
Click on image to enlarge.
My colleagues and I began to get a taste of how far we have to go—particularly in modeling memory—in 2008, when we began Reality, a €4.5 million, six-institution research project funded by the European Union. We aimed to create something completely new: a variability-sensitive, fully statistical model of a system-on-a-chip (SoC), the combination of memory and processor that forms the CPUs of most tablet computers and smartphones.
To accomplish this task, we combined transistor data provided by project member STMicroelectronics with statistical tools developed at the University of Glasgow and at Imec, in Belgium. This allowed us to model a representative subset of chip designer ARM Holdings’ library of circuit building blocks and one of ARM’s cores. Along the way, we devised a trick for quickly modeling memory variations in the ARM SoC by assigning random timing and power properties to components on the chip. The project produced more than a few surprises.
Our back-of-the-envelope calculations had led us to expect that the SRAM on the chip would cause only 10 to 20 percent of the chip-to-chip variation in signal-processing speed. It turned out to be closer to 70 percent. This variation has a big impact: If chipmakers use an SSTA model of the SoC that doesn’t account for such variation in memory, they can overestimate the maximum operating frequency of a chip by as much as 10 percent. Such a mistake raises the probability of creating bad chips.
The Reality project has also helped identify what it would take to model the variation in an entire SoC. But although my team at Imec has transferred our memory tools for analyzing SRAM to a number of partners, including memory maker Samsung, these tools don’t work by themselves. They require a larger modeling framework capable of accommodating statistical design, something that few commercial packages can do and none can do for an entire SoC. Memories can account for up to half the maximum timing delay between input and output on such a chip, which means that right now we’re missing half of the problem and thus half of the solution. As it now stands, it’s not clear whether such chip-level analysis tools will emerge by 2026, the most distant point now specified in the industry’s road map. Chipmakers may simply opt to squeeze by with existing statistical tools for logic.
One project that’s looking beyond the end of the current road map is called Terascale Reliable Adaptive Memory Systems (TRAMS). The €3.5 million effort, backed in part by the EU, aims to study the possible effects of variability on some of the switching architectures that might replace the traditional CMOS transistor. These include 3-D transistors built on an insulating layer, devices made with compound semiconductors, and logic based on carbon nanotubes. Some of these devices may be able to tune their electrical properties without dopants, and TRAMS will help determine whether this simplification will ease the variability problem or other sources of variation will crop up to take its place.
Most design efforts aim at avoiding variability. One notable exception is the multi-institution, U.S. National Science Foundation–funded Variability Expedition, which aims to develop ways to adapt to the problem. A promising way to do this is with circuit components that use proactive, on-chip hardware and software to monitor and dynamically adapt to imperfect chips [see “CPU, Heal Thyself,” IEEE Spectrum, August 2009].
If all goes well, these research efforts will help identify the best way to handle variability. But it is clear that designers can’t do the job alone. New devices and circuits will likely be crucial to reducing the impact of variability. And chipmakers may also get some relief from the problem in a few years’ time, when they switch their manufacturing process from 300-millimeter-wide wafers to 450-mm versions. Fabs will then be able to produce more chips per hour and will therefore lose less money, proportionally, to out-of-spec chips.
In one form or another, variability will continue to plague us as we approach atom-scale switches. All we can do is make sure we have the tools we need to meet it head-on.
This article originally appeared in print as “When Every Atom Counts.”
About the Author
Miguel Miranda’s interest in the issue was sparked about 10 years ago at the research firm Imec, in Belgium, where he joined a team that was trying to tackle various problems in the chip industry. He was surprised to find a big language divide between the design and manufacturing experts on the team. Miranda, who recently became a staff engineer at Qualcomm, says, “It was like taking a plunge in a cold pool.”


