The Conversation (0)
What do Viagra, low interest rates, and the Abacha family of Nigeria have in common? Not much, except that news of them is as predictable as your morning caffeine hit. The difference is, your beverage consumption remains about the same from year to year, while the spam problem has reached crisis proportions.
The problem of spam—unwanted e-mail messages—is new only in its scale, which is a bit like saying that a 4.1 and an 8.1 earthquake differ only in magnitude. In fact, this past May, e-mail reached a distressing milestone, as the amount of spam exceeded nonspam for the first time ever, according to e-mail security firm MessageLabs Ltd. in Gloucester, UK.
People have been struggling with spam for 10 years and more. [For the why and how of sending spam and filtering it, see "The Spam Game" (PDF).] The standard techniques are blacklisting, not accepting e-mail from known spammers or from mail servers that harbor them, and filtering, automatically rejecting messages with typical spam key words.
The trouble is, neither of these traditional techniques works particularly well. Spammers switch e-mail addresses or servers to avoid detection—so fast that it’s impossible to keep track. And as for filters, when they are conservatively implemented, they let too much spam through; when they’re aggressive, they often block legitimate messages along with the spam. This problem of false positives is so pervasive that the Electronic Frontier Foundation, in San Francisco, recently called on filter writers and implementers to take a Hippocratic-like oath: ”Any measure for stopping spam must ensure that all non-spam messages reach their intended recipients.”
False positives lie at the heart of the spam headache. Systems that delete messages as spam sight unseen (either at the server level or in our own e-mail readers) save us the most time but present the highest risk. We can use such systems only if we have a high degree of confidence that they’re not accidentally deleting legitimate messages. The alternatives, to merely flag messages as spam or to shuttle them to a holding pen for further review, are safer but time-consuming.
Do we have no choice but to spend the rest of our lives pausing periodically to sift through tidal waves of messages about mortgage rates, growth hormones, and even, ironically enough, antispam software? Perhaps not: over the past year, a powerful and effective new filtering method has started to emerge. The new strategies draw on techniques of probability theory originally invented by Thomas Bayes, the 18th century mathematician, to analyze entire e-mail messages instead of just the words that jump out (”Viagra,” ”cable descrambler,” ”Abacha”).
Already deployed as freely available open-source code [see table] the new methods will start to turn up in more and more products over the next year. In the meantime, promising Bayesian-like machine learning software has been included in several e-mail products from Microsoft Corp. (Redmond, Wash.), and the first commercial Bayesian products for end users and system administrators have already arrived, from Cloudmark (San Francisco).
The new Bayesian filters are trained: you go through your in box and indicate which messages are spam. Using those long-known methods of probability and statistics, the filter learns the terms usually found in spam messages, and in the remaining good ones as well. The filter then forms rules that it uses to assess new messages on its own.
While spam-filtering tools have been calling themselves ”Bayesian” for a couple of years now, strictly speaking, none of them is. The commercial filters that call themselves Bayesian today deviate from Bayes’ Rule regarding probabilities in an important respect—they create artificial scoring systems (so many points for ”Viagra,” several more for ”Abacha,” and so on) instead of using the raw probabilities generated by algorithms that implement Bayes’ Rule.
The new Bayesians reject such scoring systems. And to be really strict about it, even they deviate from Bayesian probability theory, since in a true Bayesian analysis, every event, even whether the sun will come up tomorrow, makes a starting assumption that gives an event a probability greater than zero but less than 1. So we would assign some small but nonzero probability that the sun won’t come up. Such assumptions, sometimes called ”priors,” are critical with small data sets, but in the spam world, where we have millions of past samples, they can be dispensed with.
Can the centuries-old legacy of an obscure mathematician save us from suffocating in spam? Paul Graham, a Cambridge, Mass., self-employed software engineer and the leading exponent of the new approach, believes it can. He notes that by analyzing entire messages, the filters make it much harder for spammers to craft e-mails that can elude detection. In fact, if the only spam to make it through a filter is indistinguishable from regular e-mail—no financial scams, no biggest this or sexiest that, no Viagra or cheap sales pitches of any kind—then spammers will have lost the war.
The enemy is us
Unfortunately, this very sign of victory—the indistinguishability of spam and legitimate e-mail—also points to the reason why spam is so insidiously difficult to kill automatically.
The problem with spam is that it’s almost impossible to define—it’s one of those I-know-it-when-I-see-it things. If you get e-mail from your bank, or Amazon.com, or a potential employer, how does filtering software know that you’re a customer of that bank, or have signed up for those Amazon e-mail alerts, or applied for the job? Something can be spam for you and not for your spouse, sibling, or best friend. Even those ads promising to enlarge body parts aren’t spam to someone (you know who you are).
While spam is cheap to send, it’s not entirely cost free. With no buyers at all, the sellers would eventually have to find some other way to earn a living. [See ”The Spam Game” (PDF)] In short, as Jared Blank, a senior analyst with Jupiter Research (Darien, Conn.), says: ”The true problem is that spam is effective.”
Given spam’s highly favorable business model, we’re only going to see more of it. And if that’s an annoyance for you, it’s a form of serious oppression for Internet service providers (ISPs). Alexis Rosen, president and co-owner of Public Access Networks (New York City), which runs Panix, one of the oldest commercial ISPs, declares that spam is ”morally evil.” Moreover, it hits him squarely in the pocketbook.
Rosen finds that spam uses ”a lot of an ISP’s bandwidth and disk space.” Worse is the constant reading and writing of files on his network’s hard disks as new e-mail continually arrives from the outside world in ever greater quantities. To keep up, he must add ever more servers, and ways to balance loads between them. ”Disk activity is the most precious and expensive resource we have,” says Rosen. Thus, most ISPs use server-based antispam tools to filter e-mail before it gets moved around the network to individual in boxes.
Dealing with spam like this does not come at all cheap. David Daniels, president and CEO of Starfish Internet Service, a small North Carolina ISP in Morehead City, found he had to add a second mail server just to filter spam. ”Running everything on one box was slowing down mailbox access by our customers even though the machine should be capable of supporting at least 10 times as many accounts as were on it,” he complains.
One popular proposal is to make spam illegal. Good idea, but it’s got problems. In a 1993 decision, City of Cincinnati v. Discovery Network Inc., the U.S. Supreme Court ruled that limits on commercial speech must be narrowly tailored to be constitutional. General antispam laws are likely to be too broad and therefore unconstitutional. After all, if users can’t define spam, it’s unlikely that judges or lawmakers will be able to.
Other legal or financial schemes for curtailing spam, such as placing a surcharge on outgoing e-mail, which would change the economics of spam, are as unlikely to be adopted today as they were when first suggested a decade ago. They tend to fall into one or more of three categories: they’re impossible to enforce, users would object strenuously, or they would disturb the fundamental architecture of the Internet. If we are to end spam—or at least reduce it to manageable levels—it is to technology that we must look.
The spam killers
There are other strategies, such as e-mail filters that look at the subject line or the text of an incoming message. Subject lines of well-known spams, such as ”Refinancing? Get a FREE quote on any mortgage loan program” and ”Protect Your Computer Against Viruses for $9.95,” and phrases like ”printer cartridges” and ”save up to” are collected on a ”known bad list” and searched for. When found, the messages can be discarded.
This approach, called pattern matching, can, unfortunately, discard legitimate messages. For example, a friend sends you a real message with the subject: ”Great Free Movie Offer.” Many spam filters would blast it on sight, based solely on the combination of the words ”free” and ”offer.” And simple pattern matching can be defeated by spammers modifying those key terms (”E}{treme,” ”F*R*E*E,” and ”p0rn”).
Bayesian-based means for scooping up spam promise to spot almost all of it, while reducing the number of good fish accidentally caught in the nets to nearly zero. Instead of collecting a handful of terms and using them to tag spam, this strategy uses the computer to do what it does best—make millions of calculations. It looks at thousands of e-mails and finds out which words they have in common.
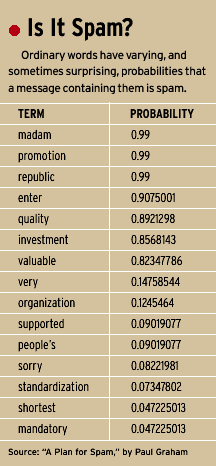
The results are striking. Graham, one of the first programmers to seriously apply this approach, found that the word ”sexy” in his e-mail means it has a 0.99 probability of being spam. But so does ”ff0000,” which is the HTML code for the bright red color that so many spam messages use—the spam filters read the HTML as well as the text. [See ”Is It Spam?”, above]
A probability of 0.99 sounds pretty good, until you realize that means if you filter the, say, 1000 e-mails you get this month, you’re going to lose 10 legitimate messages. It’s the false-positive problem, and Murphy’s Law ensures that one of those 10 is the one that offers you a job. So the real genius of this method comes from two other techniques.
Rolling the dice
The spam killers realized that the goal of spam filtering was to make a probabilistic inference about something new, based on known probabilities in the past. As luck would have it, there’s a 250-year-old edifice of mathematics for doing just that sort of thing: Bayesian analysis.
Bayes’ Rule provides a way of combining probabilities. The goal is to take two individual probabilities and combine them into a single value. If a message contains the word ”sex,” what is the likelihood the message is spam? If a message contains the word ”male,” what is its likelihood of being spam? And if the same message contains both ”sex” and ”male,” then what is the probability the message is spam? The rule creates a mathematical framework for combining these individual values into a single probability for the e-mail message as a whole.
Technically, this scenario illustrates ”naïve” Bayesian probability, where one assumes that the occurrence of one event is independent of the occurrence of the other, which generally isn’t the case with spam, where, for example, ”low” and ”mortgage” occur together more frequently in spam than they do normally. Assuming nonindependence yields even better results, but it requires more complex computations.
Essentially, the Bayesian idea is to define the probability of one thing’s happening if another thing is the case, in terms of the probability of the one, the probability of the other, and the reverse probability of the two. For example, if we want to know the probability that someone who smokes will get cancer, we need to know the number of cancer victims that are in the general population, the number of smokers, and the percentage of smokers among those who have cancer.
As companies and end users block ever more spam, spammers simply redouble their efforts
In addition to looking at the frequently used words in spam, Graham’s other insight was to look at the reverse probabilities as well—what are the words that never occur in spam? Since Graham’s methods use the entire e-mail message, the same e-mail addresses that would get passed by a so-called white, or good, address list become highly reliable indicators that something isn’t spam.
In fact, looked at that way, Bayesian filtering becomes almost a superset of all the other spam-catching techniques—blacklists (public lists of known spam originators), white lists (personal lists of nonspammers, such as your friends and colleagues), and rule-based filtering (filtering on simple key words, like ”Abacha,” ”credit,” ”Viagra,” or ”enlargement”). [See ”White Lists, Blacklists, and Challenge-Response Systems”.]
Graham was not the first to look at Bayesian tactics to attack spam. That honor goes to two sets of authors, both of whom presented papers at the 1998 annual conference of the American Association for Artificial Intelligence: Patrick Pantel and Dekang Lin, at the time at the University of Manitoba; and a team made up of Mehran Sahami, of Stanford University, and three Microsoft researchers, Susan Dumais, David Heckerman, and Eric Horvitz. Graham later took the basic idea and constructed a practical open-source implementation of it.
Meanwhile, the three researchers at Microsoft were building their own machine learning (a term they prefer to Bayesian) filter, which was first included in the e-mail reader in the company’s MSN 8 Internet service. It will soon appear in version 11 of the e-mail program Outlook, now being beta-tested. One of the Microsoft researchers, David Heckerman, told IEEE Spectrum that the company looked at hundreds of thousands of messages in its original data set—”the more training messages, the better we do.”
And in the Microsoft spam war room, as it’s called, another hundred thousand messages are added each day. ”You have to change as spam changes,” Heckerman says. For example, the added letters in a subject line like ”Tired of high rates? fc dh” are put there to defeat spam filters. Does it work? Heckerman laughs. ”It did for a while.”
How well do the Bayesian filters do? Graham says that at zero false positives, his filters typically catch 99.5 percent of the spam. And Heckerman says of Microsoft’s filters, ”We do better than humans. People make mistakes—my own error rate is about 1 in 100.” Moreover, he says, the few errors the filter makes will be in gray areas and are unlikely to involve important messages, like that job offer.

Click on the image for a larger view.
Graham doesn’t offer a software product, but his work has inspired a number of other people to do so. [See ”Open-Source Bayesian E-mail Filtering Software”] For example, Eric S. Raymond, a doyen of the open-source software movement, is working on his own e-mail filtering program, Bogofilter. ”I went with Paul’s technique because it looks a lot more robust against spammer attempts to game against it than [word] pattern-matching approaches.”
You want it when?
Besides the open-source filtering tools based on Graham’s code, commercial products that use Bayesian-like technology are starting to arrive. But outside of Microsoft, the large Internet service providers are being more cautious. Both EarthLink (Atlanta, Ga.) and America Online Inc. (Dulles, Va.) use server-based filters that can ”learn” but don’t use the Bayesian approach. Two other large e-mail providers, both in California, Yahoo Inc., in Sunnyvale, and Apple Computer Inc., in Cupertino, declined to reveal details of their filtering techniques.
Steven Curry, EarthLink’s senior product manager, says that humans look at e-mail first and verify if it is spam; if so, they write a rule to filter it out. Having humans in the process ”guards [against] the false positives.” About 70-80 percent of all spam is filtered out without ever getting routed to end users, he says.
This rule-based filtering—including blacklists—at the e-mail server will always be needed, simply because end-user filtering is too far downstream to help the ISPs in their own battle against spam. Ryan Hamlin, general manager of Microsoft’s antispam technology and strategy group, says that on a typical day, servers at the company’s free Hotmail e-mail service block more than two billion spam messages.
AOL discards about 2.4 billion spam messages everyday—”That’s 70 e-mails in each member’s mailbox every single day,” notes Charles Stiles, technical manager for e-mail at AOL. But as the company blocks ever more spam, spammers simply redouble their efforts. ”They are responding in turn,” Stiles says.
This is a war we need to win. Spam is already invading instant messaging and cellphone text messaging. And filters are also needed on the Web to block pornography, a fact recognized by the U.S. Supreme Court when it upheld a law requiring libraries to filter out pornography in Web browsing. Would a Bayesian approach work on the Web? When asked, Paul Graham said, ”I think it would work very well, actually, probably even better than e-mail filtering.” Microsoft is already blocking porn sites with a version of its machine learning filter, as part of the optional parental controls of its MSN service.
The spam war is far from over. It may never be. Like pollution or the flu, spam can never be eliminated, merely controlled. As the tide of spam threatens to overwhelm us, a return to the halcyon days of just a few years ago would be welcome.
IEEE Spectrum editorial interns Holli Riebeek and Chris Lang contributed to this article.
To Probe Further
Paul Graham’s ”A Plan for Spam” can be found at https://www.paulgraham.com/spam.html.
The 1998 conference paper ”A Bayesian Approach to Filtering Junk E-mail,” by Mehran Sahami, Susan Dumais, David Heckerman, and Eric Horvitz, is at https://research.microsoft.com/~horvitz/junkfilter.htm.
Some current statistics on spam have been compiled by the ePrivacy Group in ”Spam by the Numbers,” June 2003, at https://www.eprivacygroup.com/pdfs/SpamByTheNumbers.pdf.


