The Conversation (0)

Intel's million-transistor chip development team
In San Francisco on Feb. 27, 1989, Intel Corp., Santa Clara, Calif., startled the world of high technology by presenting the first ever 1-million-transistor microprocessor, which was also the company’s first such chip to use a reduced instruction set.
The number of transistors alone marks a huge leap upward: Intel’s previous microprocessor, the 80386, has only 275,000 of them. But this long-deferred move into the booming market in reduced-instruction-set computing (RISC) was more of a shock, in part because it broke with Intel’s tradition of compatibility with earlier processors—and not least because after three well-guarded years in development the chip came as a complete surprise. Now designated the i860, it entered development in 1986 about the same time as the 80486, the yet-to-be-introduced successor to Intel’s highly regarded 80286 and 80386. The two chips have about the same area and use the same 1-micrometer CMOS technology then under development at the company’s systems production and manufacturing plant in Hillsboro, Ore. But with the i860, then code-named the N10, the company planned a revolution.
Freed from the limitations of compatibility with the 80X86 processor family, the secret N10 team started with nothing more than a virtually blank sheet of paper.
This article was first published as “Intel’s secret is out.” It appeared in the April 1989 issue of IEEE Spectrum. A PDF version is available on IEEE Xplore. The diagrams and photographs appeared in the original print version.
One man’s crusade
The paper was not to stay blank for long. Leslie Kohn, the project’s chief architect, had already earned the nickname of Mr. RISC. He had been hoping to get started on a RISC microprocessor design ever since joining Intel in 1982. One attempt went almost 18 months into development, but current silicon technology did not allow enough transistors on one chip to gain the desired performance. A later attempt was dropped when Intel decided not to invest in that particular process technology.
Jean-Claude Cornet, vice president and general manager of Intel’s Santa Clara Microcomputer Division, saw N10 as an opportunity to serve the high-performance microprocessor market. The chip, he predicted, would reach beyond the utilitarian line of microprocessors into equipment for the high-level engineering and scientific research communities.
“We are all engineers,” Cornet told IEEE Spectrum, “so this is the type of need we are most familiar with: a computation-intensive, simulation-intensive system for computer-aided design.”
Discussions with potential customers in the supercomputer, graphics workstation, and minicomputer industries contributed new requirements for the chip. Supercomputer makers wanted a floating-point unit able to process vectors and stressed avoiding a performance bottleneck, a need that led to the entire chip being designed in a 64-bit architecture made possible by the 1 million transistors. Graphics workstation vendors, for their part, urged the Intel designers to balance integer performance with floating-point performance, and to make the chip able to produce three-dimensional graphics. Minicomputer makers wanted speed, and confirmed the decision that RISC was the only way to go for high performance; they also stressed the high throughput needed for database applications.
Freed from the limitations of compatibility with the 80X86 processor family, the secret N10 team started with nothing more than a virtually blank sheet of paper.
The Intel team also speculated over what its competitors—such as MIPS Computer Systems Inc., Sun Micro Systems Inc., and Motorola Inc.—were up to. The engineers knew their chip would not be the first in RISC architecture on the market, but the 64-bit technology meant that they would leapfrog their competitor’s 32-bit designs. They were also already planning the more fully defined architecture, with memory management, cache, floating-point, and other features on the one chip, a versatility impossible with what they correctly assumed were the smaller transistor budgets of their competitors.
The final decision rested with Albert Y.C. Yu, vice president and general manager of the company’s Component Technology and Development Group. For several years, Yu had been intrigued by Kohn’s zeal for building a superfast RISC microprocessor, but he felt Intel lacked the resources to invest in such a project. And because this very novel idea came out of the engineering group, Yu told Spectrum, he found some Intel executives hesitant. However, toward the end of 1985 he decided that, despite his uncertainty, the RISC chip’s time had come. “A lot depends on gut feel,” he said. “You take chances at these things.”
The moment the decision was made, in January 1986, the heat was on. Intel’s RISC chip would have to reach its market before the competition was firmly entrenched, and with the project starting up alongside the 486 design, the two groups might have to compete both for computer time and for support staff. Kohn resolved that conflict by making sure that the N10 effort was continually well out in front of the 486. To cut down on bureaucracy and communications overhead, he determined that the N10 team would have as few engineers as possible.
Staffing up
As soon as Yu approved the project, Sai Wai Fu, an engineer at the Hillsboro operation, moved to Santa Clara and joined Kohn as the team’s comanager. Fu and Kohn had known each other as students at the California Institute of Technology in Pasadena, had been reunited at Intel, and had worked together on one of Kohn’s earlier RISC attempts. Fu was eager for another chance and took over the recruiting, scrambling to assemble a compatible group of talented engineers. He plugged not only the excitement of breaking the million-transistor barrier, but also his own philosophy of management: broadening the engineers’ outlook by challenging them outside their areas of expertise.
To cut down on bureaucracy and communications overhead, [Leslie Kohn] determined that the N10 team would have as few engineers as possible.The project attracted a number of experienced engineers within the company. Piyush Patel, who had been head logic designer for the 80386, joined the N10 team rather than the 486 project.
“It was risky,” he said, “but it was more challenging.”
Hon P. Sit, a design engineer, also chose N10 over the 486 because, he said: “With the 486, I would be working on control logic, and I knew how to do that. I had done that before. N10 needed people to work on the floating-point unit, and I knew very little about floating-point, so I was interested to learn.”
In addition to luring “escapees,” as 486 team manager John Crawford called them, the N10 group pulled in three memory design specialists from Intel’s technology development groups, important because there was to be a great deal of on-chip memory. Finally, Kohn and Fu took on a number of engineers fresh out of college. The number of engineers grew to 20, eight more than they had at first thought would be needed, but less than two thirds the number on the 486 team.
Getting it down on paper
During the early months of 1986, when he was not tied up with Intel’s lawyers over the NEC copyright suit (Intel had sued NEC alleging copyright infringement of its microcode for the 8086), Kohn refined his ideas about what N10 would contain and how it would all fit together. Among those he consulted informally was Crawford.
“Both the N10 and the 486 were projected to be something above 400 mils, and I was a little nervous about the size,” Crawford said. “But [Kohn] said ‘Hey, if it’s not 450, we can forget it, because we won’t have enough functions on the die. So we should shoot for 450, and recognize that these things hardly ever shrink.’”
The chip, they realized, would probably turn out to be greater than 450 mils on the side. The actual i860 measures 396 by 602 mils.
Kohn started by calling for a RISC core with fast integer performance, large caches for instructions and data, and specialized circuitry for fast floating-point calculations. Where most microprocessors take from five to 10 clock cycles to perform a floating-point operation, Kohn’s goal was to cut that to one cycle by pipelining. He also wanted a 64-bit data bus overall, but with a 128-bit bus between data cache and floating-point section, so that the floating-point section would not encounter bottlenecks when accessing data. Like a supercomputer, the chip would have to perform vector operations, as well as execute different instructions in parallel.

Leslie Kohn, chief architect of Intel’s 1-million-transistor reduced-instruction-set computing microprocessor [left], and Sai-Wai Fu, project manager, shared in managing the chip’s development. Called the N10 project, work on the chip’s design began in January 1986. The first wafers came off the line last September, and as the i860, the chip was formally announced Feb. 27, 1989.
Early that April, Fu took a pencil and an 8 1/2-by-11-inch piece of paper and sketched out a plan for the chip, divided into eight sections: RISC integer core, paging unit, instruction cache, data cache, floating-point adder, floating-point multiplier, floating point registers, and bus controller. As he drew, he made some choices: for example, a line size of 32 bytes for the cache area. (A line, of whatever length, is a set of memory cells, the smallest unit of memory that can be moved to and fro between cache and main memory.) Though a smaller line size would have improved performance slightly, it would have forced the cache into a different shape and rendered it more awkward to position on the chip. “So I chose the smallest line size we could have and still have a uniform shape,” Fu said.
His sketch also effectively did away with one of Kohn’s ideas: a data cache divided into four 128-bit compartments to create four-way parallelism-called four-way set associative. But as he drew his plan, Fu realized that the four-way split would not work. With two compartments, the data could flow from the cache in a straight line to the floating-point unit. With four-way parallelism, hundreds of wires would have to bend. “The whole thing would just fall apart for physical layout reasons,” Fu said. Abandoning the four-way split, he saw, would cost only 5 percent in performance, so the two-way cache won the day.
“When I was adding these blocks together, I didn’t add them properly. I missed 250 microns.” —an Intel engineer
When he finished his sketch, he had a block of empty space. “I’d learned you shouldn’t pack so tight up front when you don’t know the details, because things grow,” Fu said. That space was filled up, and more. Several sections of the design grew slightly as they were implemented. Then one day toward the end of the design process, Fu recalls, an engineer apologetically said: “When I was adding these blocks together, I didn’t add them properly. I missed 250 microns.”
It was a simple mistake in adding. “But it is not something that you can fix easily,” Fu said. “You have to find room for the 250 microns, even though we know that because we are pushing the limits of the process technology, adding a hundred microns here or there risks sending the yield way down.
“We tried every trick we could think of to compensate, but in the end,” he said, “we had to grow the chip.”

Sai-Wai Fu, co-leader of the N10 project, sketched out this first plan for the microprocessor early in 1986. He divided the chip into eight blocks: reduced-instruction-set computer (RISC) core, paging unit, instruction cache, data cache, floating point registers, floating point adder, floating point multiplier, and clock. (The three-dimensional graphics unit was an afterthought.) Fu left a little empty space which, he felt sure, would eventually be filled.

Since Fu’s sketch partitioned the chip into eight blocks, he and Kohn divided their team into eight groups of either two or three engineers, depending upon the block’s complexity. The groups began work on logic simulation and circuit design, while Kohn continued to flesh out the architectural specifications.
“You can’t work in a top-down fashion on a project like this,” Kohn said. “You start at several different levels and work in parallel.”
Said Fu: “If you want to push the limits of a technology, you have to do top-down, bottom-up, and inside-out iterations of everything.”
The power budget at first caused serious concern. Kohn and Fu had estimated that the chip should dissipate 4 watts at 33 megahertz.
Fu divided the power budget among the teams, allocating half a watt here, a watt there. “I told them go away, do your designs, then if you exceed your budget, come back and tell me.”
The wide buses were a particular worry. The designers found that one memory cell on the chip drove a long transmission line with 1 to 2 picofarads of capacitance; by the time it reached its destination, the signal was very weak and needed amplification. The cache memory needed about 500 amplifiers, about 10 times as many as a memory chip. Designed like most static RAMs, these amplifiers would burn 2.5 watts—more than half the chip’s power budget. Building the SRAMs using circuit-design techniques borrowed from dynamic RAM technology cut that to about 0.5 watt.
“It turned out that while some groups exceeded their budget, some didn’t need as much, even though I purposely underestimated to scare them a little so they wouldn’t go out and burn a lot of power,” Fu said. The actual chip’s data sheet claims 3 watts of dissipation.
One instruction, one clock
In meeting their performance goal, the designers made executing each instruction in one clock cycle something of a religion—one that required quite a number of innovative twists. Using slightly less than two cycles per instruction is common for RISC processors, so the N10 team’s goal of one instruction per cycle appeared achievable, but such rates are uncommon for many of the chip’s other functions. New algorithms had to be developed to handle floating-point additions and multiplications in one cycle in pipeline mode. The floating-point algorithms are among the some 20 innovations on the chip for which Intel is seeking patents.
Floating-point divisions, however, take anything from 20 to 40 cycles, and the designers saw early on that they would not have enough space on the chip for the special circuitry needed for such an infrequent operation.
[The designers] did discover a way to do the fast three-dimensional graphics demanded by engineers and scientists, without any painful tradeoffs.
The designers of the floating-point adder and multiplier units made the logic for rounding off numbers conform to IEEE standards, which slowed performance. (Cray Research Inc.’s computers, for example, reject those standards to boost performance.) While some N10 engineers wanted the higher performance, they found customers preferred conformity.
However, they did discover a way to do the fast three-dimensional graphics demanded by engineers and scientists, without any painful tradeoffs. The designers were able to add this function by piggybacking a small amount of extra circuitry onto the floating-point hardware, adding only 3 percent to the chip’s size but boosting the speed of handling graphics calculations by a factor of 10, to 16 million 16-bit picture elements per second.
With a RISC processor, performing loads from cache memory in one clock cycle typically requires an extra register write port, to prevent interference between the load information and the result returning from the arithmetic logic unit. The N10 team figured out a way to use the same port for both pieces of information in one cycle, and so saved circuitry without losing speed. Fast access to instructions and data is key for a RISC processor: because the instructions are simple, more of them maybe needed. The designers developed new circuit design techniques—for which they have filed patent applications—to allow one-cycle access to the large cache memory through very large buses drawing only 2.5 watts.
“Existing SRAM parts can access data in a comparable amount of time, but they burn up a lot of power,” Kohn said.
No creeping elegance
The million transistors meant that much of the 2 1/2 years of development was spent in designing circuitry. The eight groups working on different parts of the chip called for careful management to ensure that each part would work seamlessly with all the others after their assembly.
First of all, there was the N10 design philosophy: no creeping elegance. “Creeping elegance has killed many a chip,” said Roland Albers, the team’s circuit design manager. Circuit designers, he said, should avoid reinventing the wheel. If a typical cycle is 20 nanoseconds, and an established technique leads to a path that takes 15 ns, the engineer should accept this and move on to the next circuit.
“If you let people just dive in and try anything they want, any trick they’ve read about in some magazine, you end up with a lot of circuits that are marginal and flaky”
—Roland Albers
Path timings were documented in initial project specifications and updated at the weekly meetings Albers called once the actual designing of circuits was under way.
“If you let people just dive in and try anything they want, any trick they’ve read about in some magazine, you end up with a lot of circuits that are marginal and flaky,” said Albers. “Instead, we only pushed it where it had to be pushed. And that resulted in a manufacturable and reliable part instead of a test chip for a whole bunch of new circuitry.”
In addition to enhancing reliability, the ban on creeping elegance sped up the entire process.
To ensure that the circuitry of different blocks of the chip would mesh cleanly, Albers and his circuit designers wrote a handbook covering their work. With engineers from Intel’s CAD department, he developed a graphics-based circuit-simulation environment with which engineers entered simulation schematics including parasitic capacitance of devices and interconnections graphically rather than alphanumerically. The output was then examined on a workstation as graphic waveforms.
At the weekly meetings, each engineer who had completed a piece of the design would present his results. The others would make sure it took no unnecessary risks, that it adhered to the established methodology, and that its signals would integrate with the other parts of the chip.
Intel had tools for generating the layout design straight from the high-level language that simulated the chip’s logic. Should the team use them or not? Such tools save time and eliminate the bugs introduced by human designers, but tend not to generate very compact circuitry. Intel’s own autoplacement tools for layout design cut density about in half, and slowed things down by one-third, when compared with handcrafted circuit design. Commercially available tools, Intel’s engineers say, do even worse.
Deciding when and where to use these tools was simple enough: those parts of the floating-point logic and RISC core that manipulate data had to be designed manually, as did the caches, because they involved a lot of repetition. Some cells are repeated hundreds, even thousands, of times (the SRAM cell is repeated 100,000 times), so the space gained by hand-packing the circuits involved far more than a factor of two. With the control logic, however, where there are few or no repetitions, the saving in time was considered worth the extra silicon, particularly because automatic generation of the circuitry allowed last-minute changes to correct the chip’s operation.
About 40,000 transistors out of the chip’s more than a million were laid out automatically, while about 10,000 were generated manually and replicated to produce the remaining 980,000.
About 40,000 transistors out of the chip’s more than a million were laid out automatically, while about 10,000 were generated manually and replicated to produce the remaining 980,000. “If we’d had to do those 40,000 manually, it would have added several months to the schedule and introduced more errors, so we might not have been able to sample first silicon,” said Robert G. Willoner, one of the engineers on the team.
These layout-generation tools had been used at Intel before, and the team was confident that they would work, but they were less sure how much space the automatically designed circuits would take up.
Said Albers: “It took a little more than we had thought, which caused some problems toward the end, so we had to grow the die size a little.”
Unauthorized tool use
Even with automated layout, one section of the control logic, the bus controller, started to fall behind schedule. Fearing the controller would become a bottleneck for the entire design, the team tried several new techniques. RISC processors are usually designed to interface to a fast SRAM system that acts as an external cache and interfaces in turn with the DRAM main memory. Here, however, the plan was to make it possible for users to bypass the SRAM and attach the processor directly to a DRAM, which would allow the chip to be designed into low-cost systems as well as to address very large data structures.
For this reason, the bus can pipeline as many as three cycles before it gets the first data back from the DRAM, and the data has the time to travel through a slow DRAM memory without holding up the processor. The bus also had to use the static column mode, a feature of the newest DRAMs that allows sequential addresses accessing the same page in memory to tell the system, through a separate pin, that the bit is located on the same page as the previous bit.
Both those features presented unexpected design complications, the first because the control logic had to keep track of various combinations of outstanding bus cycles. While the rest of the chip was already being laid out, the bus designers were still struggling with the logic simulation. There was no time even for manual circuit design, followed by automatic layout, followed by a check of design against layout.
One of the designers heard from a friend in Intel’s CAD department about a tool that would take a design from the logic simulation level, optimize the circuit design, and generate an optimized layout. The tool eliminated the time taken up by circuit schematics, as well as the checking for schematics errors. It was still under development, however, and while it was even then being tested and debugged by the 486 team (who had several more months before deadline than did the N10 team), it was not considered ready for use.
The N10 designer accessed the CAD department’s mainframe through the in-house computer network and copied the program. It worked, and the bus-control bottleneck was solved.
Said CAD manager Nave guardedly: “A tool at that stage definitely has problems. The specific engineer who took it was competent to overcome most of the problems himself, so it didn’t have any negative impact, which it could have. It may have worked well in the case of the N10, but we don’t condone that as a general practice.”
Designing for testability
The N10 designers were concerned from the start about how to test a chip with a million transistors. To ensure that the chip could be tested adequately, early in 1987 and about halfway into the project a product engineer was moved in with the N10 team. At first, Beth Schultz just worked on circuit designs alongside the others, familiarizing herself with the chip’s functions. Later, she wrote diagnostic programs, and now, back in the product engineering department, she is supervising the i860’s transfer to Intel’s manufacturing operations.
The first attempt to test the chip demonstrated the importance of that early involvement by product engineering. In the normal course of events, a small tester—a logic analyzer with a personal computer interface—in the design department is working on a new chip’s circuits long before the larger testers in product engineering get in on the act. The design department’s tester debugs in turn the test programs run by product engineering. This time, because a product engineer was already so familiar with the chip, her department’s testers were operating before the one in the design department.
The product engineer’s presence on the team also made the other designers more conscious of the testability question, and the i860 reflects this in several ways. The product engineer was consulted when logic designers set the bus’s pin timing, to make sure it would not overreach the tester’s capabilities. Production engineering constantly reminded the N10 team of the need to limit the number of signal pins to 128: even one over would require spending millions of dollars on new testers. (The i860 has 120 signal pins, along with 48 pins for power and grounding.)
The chip’s control logic was formed with level-sensitive scan design (LSSD). Pioneered by IBM Corp., this design-for-testability technique sends signals through dedicated pins to test individual circuits, rather than relying on instruction sequences. LSSD was not employed for the data-path circuitry, however, because the designers determined that it would take up too much space, as well as slow down the chip. Instead, a small amount of additional logic lets the instruction cache’s two 32-bit segments test each other. A boundary scan feature lets system designers check the chip’s input and output connections without having to run instructions.
Ordinarily the design and process engineers “don’t speak the same language. So tying the technology so closely to the architecture was unique.”
— Albert Y.C. Yu
Planning the i860’s burn-in called for much negotiation between the design team and the reliability engineers. The i860 normally uses 64-bit instructions; for burn-in, the reliability engineers wanted as few connections as possible: 64 was far too many.
“Initially,” said Fu, “they started out with zero wires. They wanted us to self-test. So we said, ‘How about 15 or 20?’”
They compromised with an 8-bit mode that was to be used only for the burn-in, but with this feature i860 users can boot up the system from an 8-bit wide erasable programmable ROM.
The designers also worked closely with the group developing the 1-μm manufacturing process first used on a compaction of the 80386 chip that appeared early in 1988. Ordinarily, Intel vice president Yu said, the design and process engineers “don’t speak the same language. So tying the technology so closely to the architecture was unique.”
Said William Siu, process development engineering manager at Intel’s Hillsboro plant: “This process is designed for very low parasitic capacitance, which allows circuits to be built that have high performance and consume less power. We had to work with the design people to show them our limitations.”
The process engineers had the most influence on the on-chip caches. “Initially,” said designer Patel, “we weren’t sure how big the caches could be. We thought that we couldn’t put in as big a cache as we wanted, but they told us the process was good enough to do that.”
A matter of timing
The i860’s most unique architectural feature is perhaps its on-chip parallelism. The instruction cache’s two 32-bit segments issue two simultaneous 32-bit instructions, one to the RISC core, the other to the floating-point section. Going one step further, certain floating-point instructions call upon adder and multiplier simultaneously. The result is a total of three operations acted upon in one clock cycle.
The architecture increases the chip’s speed, but because it complicated the timing, implementing it presented problems. For example, if two or three parallel operations request the same data, they must be served serially. Many bugs found in the chip’s design involved this kind of synchronization.
The logic that freezes a unit when needed data is for the moment unavailable presented one of the biggest timing headaches. Initially, designers thought this situation would not crop up too often, but the on-chip parallelism caused it more frequently than had been expected.
The freeze logic grew and grew until, said Patel, “it became so kludgy we decided to sit down and redesign the whole freeze logic.” That was not a trivial decision—the chip was about halfway through its design schedule and that one revision took four engineers more than a month.
Even running on a large mainframe, the circuit simulations were bogging down. Engineers would set one to run over the weekend and find it incomplete when they came in on Monday.
As the number of transistors approached the 1 million mark, the CAD tools that had been so much help began to break down. Intel has developed CAD tools in-house, believing its own tools would be more tightly coupled with its process and design technology, and therefore more efficient. But the N10 represented a vast advance on the 80386, Intel’s biggest microprocessor up to now, and the CAD systems had never been applied to a project anywhere near the size of the new chip. Indeed, because the i860’s parallelism has resulted in huge numbers of possible combinations (tens of millions have been tested; the total is many times that), its complexity is staggering.
Even running on a large mainframe, the circuit simulations were bogging down. Engineers would set one to run over the weekend and find it incomplete when they came in on Monday. That was too long to wait, so they took to their CAD tools to change the simulation program. One tool that goes through a layout to localize short circuits ran for days, then gave up. “We had to go in and change the algorithm for that program,” Willoner said.
The team first planned to plot the entire chip layout as an aid in debugging, but found that it would take more than a week of running the plotters round the clock. They gave up, and instead examined on workstations the chip’s individual areas.
But now the mainframe running all these tools began to balk. The engineers took to setting their alarm clocks to ring several times during the night and logging on to the system through their terminals at home to restart any computer run that had crashed.
The net-list software failed totally; the schematic was just too big.
Before a chip design is turned over to manufacturing for its first silicon run—a transfer called the tape-out—the computer performs full-chip verification, comparing the schematics with the layout. To do this, it needs a net list, an intermediate version of the schematic, in the form of alphanumerics. The net list is normally created only a few days before tape-out, when the design is final. But knowing the 486 team was on their heels and would soon be demanding—and, as a priority project, receiving—the manufacturing department’s resources, the N10 team did a full-chip-verification dry run two months early with an incomplete design.
And the net-list software failed totally; the schematic was just too big. “Here we were, approaching tape-out, and we suddenly discover we can’t net-list this thing,” said Albers. “In three days one of our engineers figured out a way around it, but it had us scared for a while.”
Into silicon
After mid-August, when the chip was turned over to the product engineering department to be prepared for manufacture, all the design team could do was wait, worry, and tweak their test programs in the hope that the first silicon run would prove functional enough to test completely. And six weeks later, when the first batch of wafers arrived, they were complete enough to be tested, but not enough to be packaged. Normally, design and product engineering teams wait until wafers are through the production process before testing them, but not this time.
Rajeev Bharadhwaj, a design engineer, flew to Oregon—on a Monday—to pick up the first wafers, hot off the line. By 9:30 p.m. he was back in Santa Clara, where the whole design team, as well as product engineers and marketing people, waited while the first test sequences ran—at no more than 10 MHz, far below the 33 MHz target. It looked like a disaster, but after the engineers spent 20 nervous minutes going over critical paths in the chips in search of the bottleneck, one noticed that the power-supply pin was not attached—the chip had been drawing power only from the clock signal and its I/O systems. Once the power pin was connected, the chip ran easily at 40 MHz.
By 3 a.m., some 8000 test vectors had been run through the chip—vectors that the product engineer had worked six months to create. This was enough for the team to pronounce confidently: “It works!”
The i860 designation was chosen to indicate that the new chip does bear a slight relationship to the 80486—because the chips structure their data with the same byte ordering and have compatible memory-management systems, they can work together in a system and exchange data.
This little chip goes to market
Intel expects to have the chip available—at $750 for the 33 MHz and $1037 for the 40 MHz version—in quantity by the fourth quarter of this year, and has already shipped samples to customers. (Peripheral chips for the 386 can be used with the i860 and are already on the market.) Because the i860 has the same data-storage structure as the 386, operating systems for the 386 can be easily adapted to the new production.
Intel has announced a joint effort toward developing a multiprocessing version of Unix for the i860 with AT&T Co. (Unix Software Operation, Morristown, N.J.), Olivetti Research Center (Menlo Park, Calif.), Prime Computer (Commercial Systems Group, Natick, Mass.), and Convergent Technologies (San Jose, Calif., a division of Unisys Corp.). Tektronix NC and Kontron Elektronik GmbH plan to manufacture debuggers (logic analyzers) for the chip.
For software developers, Intel has developed a basic tool kit (assemblers, simulators, debuggers, and the like) and Fortran and C compilers. In addition, Intel has a Fortran vectorizer, a tool that automatically restructures standard Fortran code into vector processes with a technology previously only available for supercomputers.
IBM plans to make the i860 available as an accelerator for the PS/2 series of personal computers, which would boost them to near supercomputer performance. Kontron, SPEA Software AG, and Number Nine Computer Corp. will be using the i860 in personal-computer graphics boards. Microsoft Corp. has endorsed the architecture but has not yet announced products.
Minicomputer vendors are excited about the chip because the integer performance is much higher than was expected when the project began.
“We have the Dhrystone record on a microprocessor today’’—85,000 at 40 MHz, said Kohn. (A Dhrystone is a synthetic benchmark representing an average integer program and is used to measure integer performance of a microprocessor or computer system.) Olivetti is one company that will be using the N10 in minicomputers, as will PCS Computer Systems Inc.
Megatek Corp. is the first company to announce plans to makei860-based workstations in a market where the chip will be competing with such other RISC microprocessors as SPARC from Sun, the 88000 from Motorola, Clipper from Integraph Corp., and R3000 from MIPS Computer Systems Inc.
Intel sees its chip as having leapfrogged the current 32-bit generation of microprocessors. The company’s engineers think the i860 has another advantage: whereas floating-point chips, graphics chips, and caches must be added to the other microprocessors to build a complete system, the i860 is fully integrated, and therefore eliminates communications overhead. Some critics see this as a disadvantage, however, because it limits the choices open to system designers. It remains to be seen if this feature can overcome the lead the other chips have in the market.
The i860 team expects other microprocessor manufacturers to follow with their own 64-bit products with other capabilities besides RISC integer processing integrated onto a single chip. As leader in the new RISC generations, however, Intel hopes the i860 will set a standard for workstations, just as the 8086 did for personal computers.
To probe further
Intel’s first paper describing the i860, by Leslie Kohn and SaiWai Fu—’’A 1,000,000 transistor microprocessor”—was published in the 1989 International Solid-State Circuits Conference Digest of Technical Papers, February 1989, pp. 54-55.
The advantages of reduced-instruction-set computing (RISC) are discussed in “Toward simpler, faster computers,” by Paul Wallich (IEEE Spectrum, August 1985, pp. 38-45).
Editor’s note June 2022: The i860 (N10) microprocessor did not exactly take the marketplace by storm. Though it handled graphics with impressive speed and found a niche as a graphics accelerator, its performance on general-purpose applications was disappointing. Intel discontinued the chip in the mid-1990s.
Approaching Cray 1 performance—with a single chip
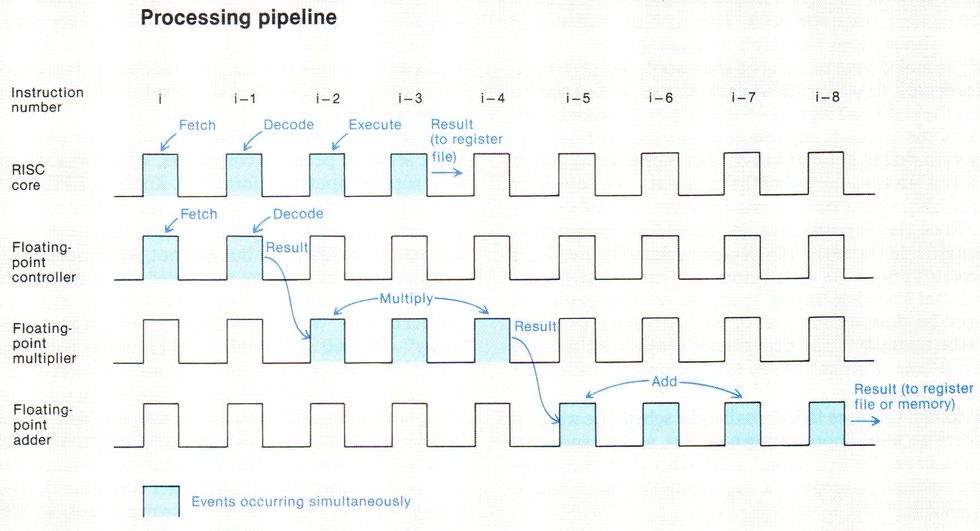
Symbolically depicted as waveforms for simplicity, processing events in the i860 microprocessor occur simultaneously (as indicated by color), particularly when the pipeline is full. Here both the RISC core and floating-point controller simultaneously fetch instruction i from the on-chip cache (not shown). At that instant the RISC core is also decoding the preceding instruction (i -1), executing the one before that (i - 2), and transmitting the result from the execution of instruction i-3 to, for example, the register file. Meanwhile the floating-point controller decodes instruction i-1 and sends the decoded instruction to the floating-point multiplier. At the same time, the multiplier is executing instructions i-2, i-3, and i-4, and sending the result of i-4 to the floating-point adder. The adder is executing instructions i-5, i-6, and i-7, and sending the result of instruction i-8 to, for example, the register file or memory.
The Intel i860—called the N10 by its designers —is a 64-bit CMOS microprocessor measuring 488 square mils. It contains more than 1 million transistors.
The chip’s core is a reduced-instruction-set computing (RISC) processor that, for integer operations, has been benchmarked at 85,000 Dhrystones (a standard measurement of integer performance) at 40 megahertz, according to Intel. (A RISC microprocessor from MIPS Computer Systems Incl, one of the fastest available, hits 42,000 Dhrystones on this benchmark; the Intel 80386 hits 13,000 Dhrystones.)
One-third of the i860 is devoted to floating-point calculations and runs at 80 million floating-point operations per second for single-precision calculations, and at 60 MFLOPS for double-precision calculations, again at 40 MHz.
In addition to standard scalar operations, the i860 can, like a supercomputer, perform vector operations. This vector capability is not implemented by dedicated hardware; rather, it is handled by a software library, and an on-chip cache that stores data for the chip’s regular calculations also holds the intermediate results of the vector operations. The i860’s overall performance is for most applications about half the speed of a Cray-1.
The chip’s designers consider its most important feature to be its balance. There are no on-chip bottlenecks, they say. All execution units run at the same speed, and the data flow to those units is just as fast as they can handle it. Therefore, the designers ay, the full power of the RISC and floating-point units is constantly available. Performance measurements refer not just to peak running, but are sustainable for vector operations. In addition, the integer and floating-point addition and multiplication units can function simultaneously at up to three operations for each clock.
From Your Site Articles
- Intel Now Packs 100 Million Transistors in Each Square Millimeter ... ›
- RISC Maker - IEEE Spectrum ›
- The U.S.-China Chip Ban, Explained - IEEE Spectrum ›
- The Ultimate Transistor Timeline - IEEE Spectrum ›
- Celebrate the 75th Anniversary of the Transistor With IEEE - IEEE Spectrum ›
Related Articles Around the Web
{"imageShortcodeIds":[]}


