The Conversation (0)

illustration: Christian Gralingen
 Illustration: Christian Gralingen
Illustration: Christian Gralingen
The era of telecommunicationssystems designed solely by humans is coming to an end. From here on, artificial intelligence will play a pivotal role in the design and operation of these systems. The reason is simple: rapidly escalating complexity.
Each new generation of communications system strives to improve coverage areas, bit rates, number of users, and power consumption. But at the same time, the engineering challenges grow more difficult. To keep innovating, engineers have to navigate an increasingly tangled web of technological trade-offs made during previous generations.
In telecommunications, a major source of complexity comes from what we’ll call impairments. Impairments include anything that deteriorates or otherwise interferes with a communications system’s ability to deliver information from point A to point B. Radio hardware itself, for example, impairs signals when it sends or receives them by adding noise. The paths, or channels, that signals travel over to reach their destinations also impair signals. This is true for a wired channel, where a nearby electrical line can cause nasty interference. It’s equally true for wireless channels, where, for example, signals bouncing off and around buildings in an urban area create a noisy, distortive environment.
These problems aren’t new. In fact, they’ve been around since the earliest days of radio. What’s different now is the explosive pace of wireless proliferation, which is being driven increasingly by the rise of the Internet of Things. The upshot is that the combined effect of all these impairments is growing much more acute, just when the need for higher bit rates and lower latencies is surging.
Is there a way out? We believe there is, and it’s through machine learning. The breakthroughs in artificial intelligence in general, and machine learning in particular, have given engineers the ability to thrive, rather than drown, in complex situations involving huge amounts of data. To us, these advances posed a compelling question: Can neural networks (a type of machine-learning model), given enough data, actually design better communications signals than humans? In other words, can a machine learn how to talk to another machine, wirelessly, and do so better than if a human had designed its signals?
Based on our work on space communications systems with NASA, we are confident the answer is yes. Starting in 2018, we began carrying out experiments using NASA’s Tracking Data Relay Satellite System (TDRSS), also known as the Space Network, in which we applied machine learning to enable radios to communicate in an extremely complex environment. The success of these experiments points to a likely future in which communications engineers are less focused on developing wireless signals and more focused on building the machine-learning systems that will design such signals.
Over the years, communications engineers have invented countless techniques to minimize impairments in wireless communications. For example, one option is to send a signal over multiple channels so that it is resilient to interference in any one channel. Another is to use multiple antennas—as a signal bounces off obstacles in the environment, the antennas can receive the signal along different paths. That causes the signals to arrive at different times in order to avoid a burst of unexpected interference. But these techniques also make radios more complex.
Completely accounting for impairments has never been practical, because the radio systems and environments that create them are so complicated. As a result, communications engineers have developed statistical models that approximate the effects of impairments on a channel. These models give communications engineers a generally good idea of how to design and build the equipment for a particular wireless system in order to reduce impairments as much as possible.
Nevertheless, using statistical models to guide the design of communications signals can’t last forever. The status quo is already struggling with the latest telecom systems, such as 5G cellular networks. The systems are too complicated and the number of connected devices is too high. For communications engineering to meet the demands of the current and future generations of wireless systems, a new approach, like artificial intelligence, is needed.
To be clear, using AI in communications systems isn’t a new concept. Adaptive radios, smart radios, and cognitive radios, increasingly used in military and other applications, all use AI to improve performance in challenging environments.
But these existing technologies have always been about adapting how a radio system behaves. For example, 4G LTE wireless networks include AI techniques that reduce data rates when the connection between the transmitter and receiver degrades. A lower data rate avoids overloading a low-bandwidth channel and causing data to be lost. In another example, AI techniques in Bluetooth systems shift a signal’s frequency to avoid an interfering signal, should one appear.
The takeaway here is that AI has been used in the past to modify the settings within a communications system. What hasn’t happened before is using AI to design the signal itself.
One of us, Tim O’Shea, researched how to apply deep learning to wireless signal processing as part of his doctoral work at Virginia Tech from 2013 to 2018. In late 2016, O’Shea cofounded DeepSig with Jim Shea, a veteran engineer and entrepreneur, to build on his research and create prototypes of the technology. The goal of the company, based in Arlington, Va., is to identify where human engineering in communications systems is hitting its limits, and how neural networks might enable us to push past that threshold (more on that later).
Before we go further, it will help to know a bit about how communications engineers design the physical components of a radio that are responsible for creating a signal to be transmitted. The traditional approach starts with a statistical model that resembles the real-world communications channel you’re trying to build. For example, if you’re designing cell towers to go into a dense, urban area, you might pick a model that accounts for how signals propagate in an environment with lots of buildings.
The model is backed by channel soundings, which are actual physical measurements taken with test signals in that environment. Engineers will then design a radio modem—which modulates and demodulates a radio signal to encode the ones and zeroes of binary code—that performs well against that model. Any design has to be tested in simulations and real-world experiments, and then adjusted and retested until it performs as expected. It’s a slow and laborious process, and it often results in radios with design compromises, such as filter quality. Generally, a radio operating on a narrow band of frequencies can filter out noise very well, but a wider-band radio will have a less effective filter.
Clear signals
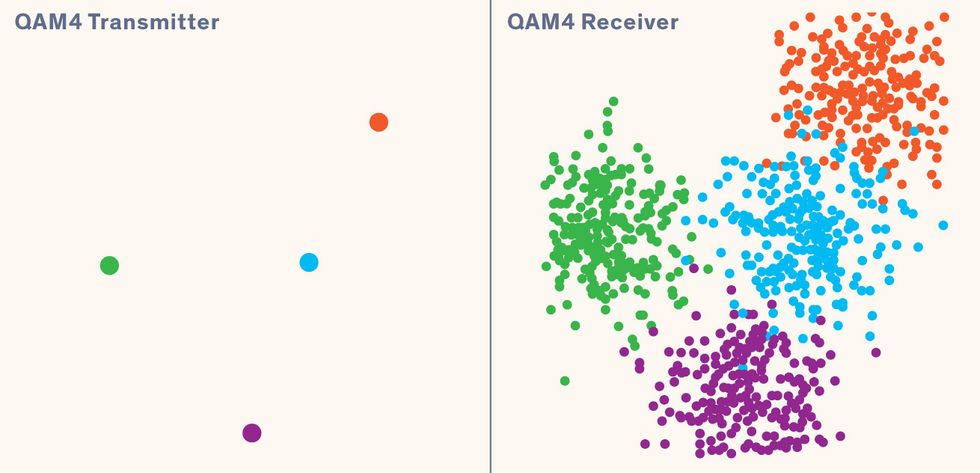
For simpler situations, what we call channel autoencoders design signals much as a person might. In quadrature amplitude modulation using QAM4 [above], data is sent using four different symbols (such as binary 00, 01, 10, and 11) represented by specific signal modulations. The channel autoencoder spaces out those four signal modulations fairly evenly. For the transmitting radio [left], each symbol is sent exactly the same way. After they cross the wireless channel, the receiver [right], sees each symbol arrive as a small cloud of points. That’s because each signal arrives a little differently from the others due to impairments. The channel autoencoder’s goal is to ensure that the clouds don’t overlap, which could cause confusion about what symbol was actually received.
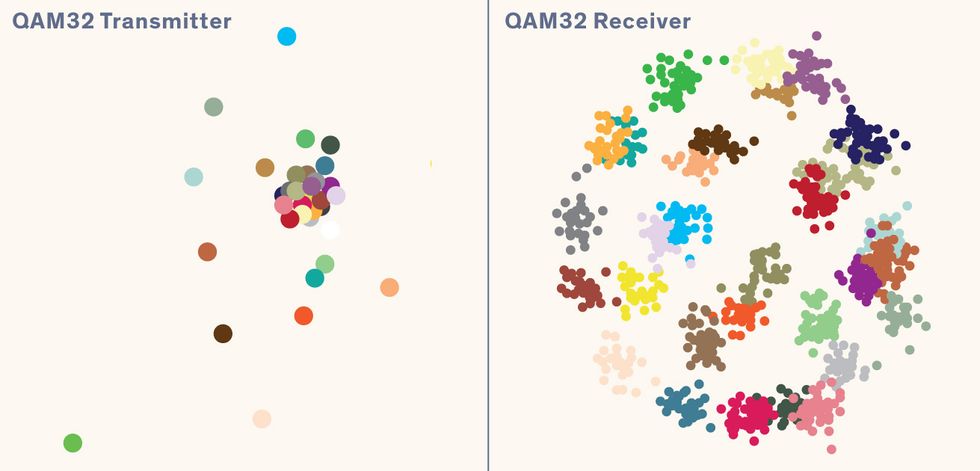
When wireless signals get more complex, channel autoencoders truly shine, using unexpected solutions. In the second example, a QAM32 method [above], data is sent using 32 different symbols. For the channel in question here, the channel autoencoder has learned that for maximum clarity on the receiving end, symbols should be transmitted unevenly, sometimes even nearly on top of one another. But the signal modulations are affected by the impairments in the channel, and the end result shows that the received symbols barely overlap. No human engineer would think to design signals this way, and yet it works well.
DeepSig’s efforts resulted in a new technique, which we call the channel autoencoder, to create signals. It works by training two deep neural networks in tandem, an encoder and a decoder, which together effectively act as the channel’s modem. The encoder converts the data to be transmitted into a radio signal, and on the other side of the channel—the other side of the corrupting impairments—the decoder reconstructs its best estimate of the transmitted data from the received radio signal.
Let’s take a moment here to break down what the channel autoencoder does, step by step. At the autoencoder’s core are the two neural networks. You’ve probably heard of neural networks for image recognition. As a basic example, a researcher might “show” a neural network thousands of images of dogs and of animals that are not dogs. The network’s algorithms can then distinguish between “dog” and “not-dog” and are optimized to recognize future images of dogs, even if those images are novel to the network. In this example, “dog” would be the image the neural network is trained to recognize.
In this application, the neural network is trained to identify features of input data corresponding to an image. When a new image is presented, if it has input data with similar features, it will result in a similar output. By “feature,” we mean a pattern that exists in the data. In image recognition, it may be an aspect of the images seen. In speech recognition, it might be a particular sound in the audio. In natural-language processing, it might be a paragraph’s sentiment.
You may remember that we said the channel autoencoder uses deep neural networks. What that means is that each neural network is made up of many more layers (often numbering in the hundreds) that enable it to make more detailed decisions about the input data than a simpler neural network could. Each layer uses the results of the previous layers to make progressively more complex insights. For example, in computer vision, a simpler neural network could tell you whether an image is a dog, but a deep neural network could tell you how many dogs there are or where they are located in the image.
You’ll also need to know what an autoencoder is. Autoencoders were first invented in 1986 by Geoffrey Hinton, a pioneer in machine learning, to address the challenge of data compression. In the implementation of an autoencoder, one of its two neural networks is a compressor and one is a decompressor. The compressor, as the name suggests, learns how to effectively compress data based on its type—it would compress PDFs differently than it would JPGs, for example. The decompressor does the opposite. The key is that neither the compressor nor the decompressor can function alone—both are needed for the autoencoder to function.
So now let’s put all of this in the context of wireless signals. The channel autoencoder does the same thing as more traditional autoencoders. But instead of optimizing for different types of data, the autoencoder is optimizing for different wireless channels. The autoencoder consists of two deep neural networks, one on each side of the channel, which learn how to modulate and demodulate types of wireless signals, thus jointly forming a modem. The takeaway is that the channel autoencoder can create better signals for a wireless channel than the generic, one-size-fits-all signals that are typically used in communications.
The neural networks were able to develop signals that are not easily or obviously conceived by people using traditional methods.
Previously we mentioned channel soundings—if you recall, those are the test signals sent through a wireless channel to measure interference and distortion. These soundings are key for the channel autoencoder because they give an understanding of what obstacles a signal will face as it moves across a channel. For example, a lot of activity in the 2.4-gigahertz band would indicate there’s a Wi-Fi network nearby. Or if the radio receives many echoes of the test signal, the environment is likely filled with many reflective surfaces.
With the soundings complete, the deep neural networks can get to work. The first, the encoder, uses the information gleaned from the soundings to encode the data being modulated into a wireless signal. That means the neural network on this side is taking advantage of effects from analog-to-digital signal converters and power amplifiers in the radio itself, as well as known reflective surfaces and other impairments in the soundings. In so doing, the encoder creates a wireless signal that is resilient to the interference and distortion in the channel, and it may develop a complex solution that is not easily arrived at by traditional means.
On the other side of the channel, the neural network designated as the decoder does the same thing, only in reverse. When it receives a signal, it will take what it knows about the channel to strip away the effects of interference. In this case, the network will reverse distortions and reflections along with any redundancy that was encoded to estimate what sequence of bits was transmitted. Error-correction techniques may also come into play to help clean up the signal. At the end of the process, the decoder has restored the original information.
During the training process, the neural networks get feedback on their current performance relative to whatever metric the engineers want to prioritize, whether that’s the error rate in the reconstructed data, the radio system’s power consumption, or something else. The neural networks use that feedback to improve their performance against those metrics without direct human intervention.
Among the channel autoencoder’s advantages is its ability to treat all impairments the same way, regardless of their source. It doesn’t matter if the impairment is distortion from nearby hardware inside the radio or from interference over the air from another radio. What this means is that the neural networks can take all impairments into account at once and create a signal that works best for that specific channel.
The DeepSig team believed that training neural networks to manage signal processing in a pair of modems would be a titanic shift in how communications systems are designed. So we knew we would have to test the system thoroughly if we were going to prove that this shift was not only possible, but desirable.
Fortunately, at NASA, coauthor Joe Downey and his colleague Aaron Smith had taken notice of DeepSig’s ideas, and had just such a test in mind.
Since the early 1980s, NASA’s TDRSS has been providing communication and tracking services for near-Earth satellites. TDRSS is itself a collection of ground stations and a constellation of satellites that stays in continuous contact with Earth-orbiting satellites and the International Space Station. TDRSS satellites act as relays, transmitting signals between other satellites and ground-station antennas around the world. This system eliminates the need to build more ground stations to guarantee that satellites can stay in contact. Today, 10 TDRSS satellites provide service for the International Space Station, commercial resupply missions, and NASA’s space- and earth-science missions.
When TDRSS first came on line, spacecraft used lower data-rate signals that were robust and resilient to noise. More recent science and human-spaceflight missions have required higher data throughputs, however. To keep up with demand, TDRSS now uses signals that can cram more bits of information into the same amount of bandwidth. The trade-off is that these types of signals are more sensitive to impairments. By the early 2010s, NASA’s demands on TDRSS had become so large that it was difficult to design signals that worked well among the growing impairments. Our hope was that it would not be so difficult for neural networks to do so on their own.

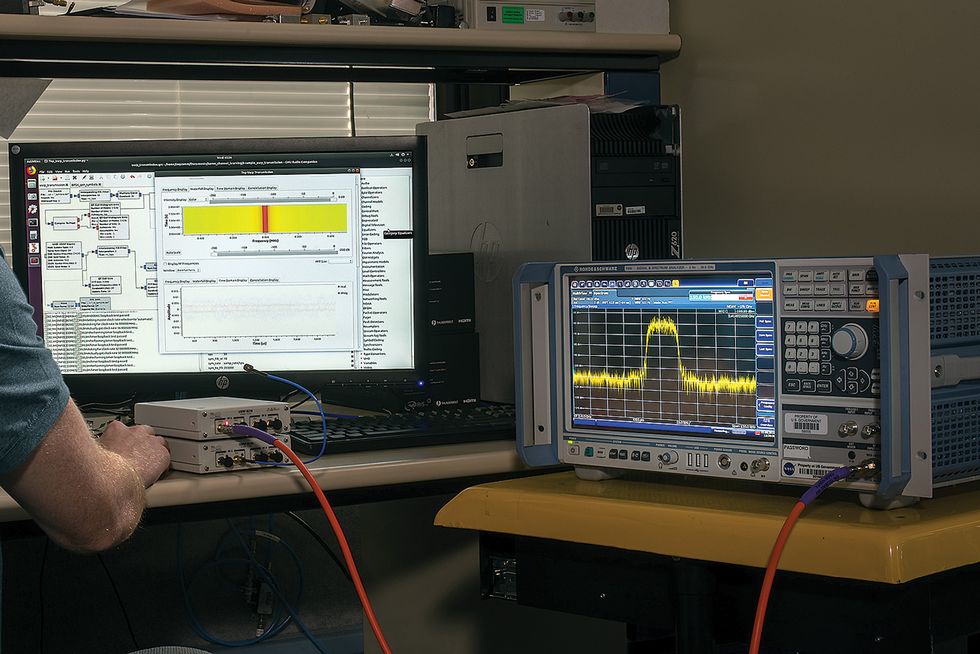 Machine Learning, Machine Testing: NASA engineers Cameron Seidl and Janette Briones run tests over TDRSS from this ground-station control room. During the channel-autoencoder tests, the autoencoder proved its superiority over human techniques by sending data with a lower error rate.Photos: Glenn Research Center/NASA
Machine Learning, Machine Testing: NASA engineers Cameron Seidl and Janette Briones run tests over TDRSS from this ground-station control room. During the channel-autoencoder tests, the autoencoder proved its superiority over human techniques by sending data with a lower error rate.Photos: Glenn Research Center/NASA
A key characteristic of TDRSS for our purposes is that its satellites don’t perform any signal processing. They simply receive a signal from either a ground station or another satellite, amplify the signal, and then retransmit it to its destination. That means the main impairments to a signal transmitted through TDRSS come from the radio’s own amplifiers and filters, and the distortion from interference among simultaneous signals. As you may recall, our neural networks don’t distinguish among forms of interference, treating them all as part of the same external channel that the signal has to travel through.
TDRSS provided an ideal scenario for testing how well AI could develop signals for complex, real-world situations. Communicating with a satellite through TDRSS is rife with interference, but it’s a thoroughly tested system. That means we have a good understanding of how well signals currently perform. That made it easy to check how well our system was doing by comparison. Even better, the tests wouldn’t require modifying the existing TDRSS equipment at all. Because the channel autoencoders already include modems, they could be plugged into the TDRSS equipment and be ready to transmit.
In late July of 2018, after months of preparation, the DeepSig team headed to NASA’s Cognitive Radio Laboratory at Glenn Research Center in Cleveland. There, they would test modems using signals created through neural networks in a live, over-the-air experiment. The goal of the test was to run signal modulations used by the TDRSS system side by side with our channel autoencoder system, enabling us to directly compare their performances in a live channel.
At Glenn, the DeepSig team joined NASA research scientists and engineers to replace the proven, human-designed modems at NASA ground stations in Ohio and New Mexico with neural networks created with a channel autoencoder. During the tests, traditional TDRSS signals, as well as signals generated by our autoencoders, would travel from one ground station, up to one of the satellites, and back down to the second ground station. Because we kept the bandwidth and frequency usage the same, the existing TDRSS system and the channel autoencoder faced the exact same environment.
When the test was over, we saw that the traditional TDRSS system had a bit error rate just over 5 percent, meaning about one in every 20 bits of information had failed to arrive correctly due to some impairment along the way. The channel autoencoder, however, had a bit error rate of just under 3 percent. It’s worth mentioning that the tests did not include standard after-the-fact error correction, to allow for a direct comparison. Typically, both systems would see a much lower bit error rate. Just in this test, however, the channel autoencoder reduced TDRSS’s bit error rate by 42 percent.
The TDRSS test was an early demonstration of the technology, but it was an important validation of using machine-learning algorithms to design radio signals that must function in challenging environments. The most exciting aspect of all this is that the neural networks were able to develop signals that are not easily or obviously conceived by people using traditional methods. What that means is the signals may not resemble any of the standard signal modulations used in wireless communications. That’s because the autoencoder is building the signals from the ground up—the frequencies, the modulations, the data rates, every aspect—for the channel in question.
Remember how we said that today’s techniques for signal creation and processing are a double-edged sword? Traditional signal-modulation approaches grow more complex as the available data about the system increases. But a machine-learning approach instead thrives as data becomes more abundant. The approach also isn’t hindered by complex radio equipment, meaning the problem of the double-edged sword goes away.
And here’s the best part: Presented with a new communications channel, machine-learning systems are able to train autoencoders for that channel in just a few seconds. For comparison, it typically takes a team of seasoned experts months to develop a new communications system.
To be clear, machine learning does not remove the need for communications engineers to understand wireless communications and signal processing. What it does is introduce a new approach to designing future communications systems. This approach is too powerful and effective to be left out of future systems.
“This approach is too powerful and effective to be left out of future systems.”
Since the TDRSS experiment and subsequent research, we’ve seen increasing research interest in channel autoencoders as well as promising usage, especially in fields with very hard-to-model channels. Designing communications systems with AI has also become a hot topic at major wireless conferences including Asilomar, the GNU Radio Conference, and the IEEE Global Communications Conference.
Future communications engineers will not be pure signal-processing and wireless engineers. Rather, their skills will need to span a mixture of wireless engineering and data science. Already, some universities, including the University of Texas at Austin and Virginia Tech, are introducing data science and machine learning to their graduate and undergraduate curricula for wireless engineering.
Channel autoencoders aren’t a plug-and-play technology yet. There’s plenty yet to be done to further develop the technology and underlying computer architectures. If channel autoencoders are ever to become a part of existing widespread wireless systems, they’ll have to undergo a rigorous standardization process, and they’ll also need specially designed computer architectures to maximize their performance.
The impairments of TDRSS are hard to optimize against. This raises a final question: If channel autoencoders can work so well for TDRSS, why not for many other wireless systems? Our answer is that there’s no reason to believe they can’t.
This article appears in the May 2020 print issue as “Machine
Learning Remakes Radio.”
About the Author
Ben Hilburn was until recently director of engineering at the wireless deep-learning startup DeepSig. He’s now with Microsoft. Tim O’Shea is CTO at DeepSig and a research assistant professor at Virginia Tech. Nathan West is director of machine learning at DeepSig. Joe Downey works on space-based software-defined radio technology at the NASA Glenn Research Center.


