The Conversation (0)

Illustration: Shaw Nielsen
As a child, were you ever afraid that a monster lurking in your bedroom would leap out of the dark and get you? My job at Oak Ridge National Laboratory is to worry about a similar monster, hiding in the steel cabinets of the supercomputers and threatening to crash the largest computing machines on the planet.
The monster is something supercomputer specialists call resilience—or rather the lack of resilience. It has bitten several supercomputers in the past. A high-profile example affected what was the second fastest supercomputer in the world in 2002, a machine called ASCI Q at Los Alamos National Laboratory. When it was first installed at the New Mexico lab, this computer couldn’t run more than an hour or so without crashing.
The ASCI Q was built out of AlphaServers, machines originally designed by Digital Equipment Corp. and later sold by Hewlett-Packard Co. The problem was that an address bus on the microprocessors found in those servers was unprotected, meaning that there was no check to make sure the information carried on these within-chip signal lines did not become corrupted. And that’s exactly what was happening when these chips were struck by cosmic radiation, the constant shower of particles that bombard Earth’s atmosphere from outer space.
To prove to the manufacturer that cosmic rays were the problem, the staff at Los Alamos placed one of the servers in a beam of neutrons, causing errors to spike. By putting metal side panels on the ASCI Q servers, the scientists reduced radiation levels enough to keep the supercomputer running for 6 hours before crashing. That was an improvement, but still far short of what was desired for running supercomputer simulations.
 Illustration: Shaw Nielsen
Illustration: Shaw Nielsen
An even more dramatic example of cosmic-radiation interference happened at Virginia Tech’s Advanced Computing facility in Blacksburg. In the summer of 2003, Virginia Tech researchers built a large supercomputer out of 1,100 Apple Power Mac G5 computers. They called it Big Mac. To their dismay, they found that the failure rate was so high it was nearly impossible even to boot the whole system before it would crash.
The problem was that the Power Mac G5 did not have error-correcting code (ECC) memory, and cosmic ray–induced particles were changing so many values in memory that out of the 1,100 Mac G5 computers, one was always crashing. Unusable, Big Mac was broken apart into individual G5s, which were sold one by one online. Virginia Tech replaced it with a supercomputer called System X, which had ECC memory and ran fine.
Cosmic rays are a fact of life, and as transistors get smaller, the amount of energy it takes to spontaneously flip a bit gets smaller, too. By 2023, when exascale computers—ones capable of performing 1018 operations per second—are predicted to arrive in the United States, transistors will likely be a third the size they are today, making them that much more prone to cosmic ray–induced errors. For this and other reasons, future exascale computers will be prone to crashing much more frequently than today’s supercomputers do. For me and others in the field, that prospect is one of the greatest impediments to making exascale computing a reality.
Just how many spurious bit flips are happening inside supercomputers already? To try to find out, researchers performed a study [PDF] in 2009 and 2010 on the then most powerful supercomputer—a Cray XT5 system at Oak Ridge, in Tennessee, called Jaguar.
Jaguar had 360 terabytes of main memory, all protected by ECC. I and others at the lab set it up to log every time a bit was flipped incorrectly in main memory. When I asked my computing colleagues elsewhere to guess how often Jaguar saw such a bit spontaneously change state, the typical estimate was about a hundred times a day. In fact, Jaguar was logging ECC errors at a rate of 350 per minute.
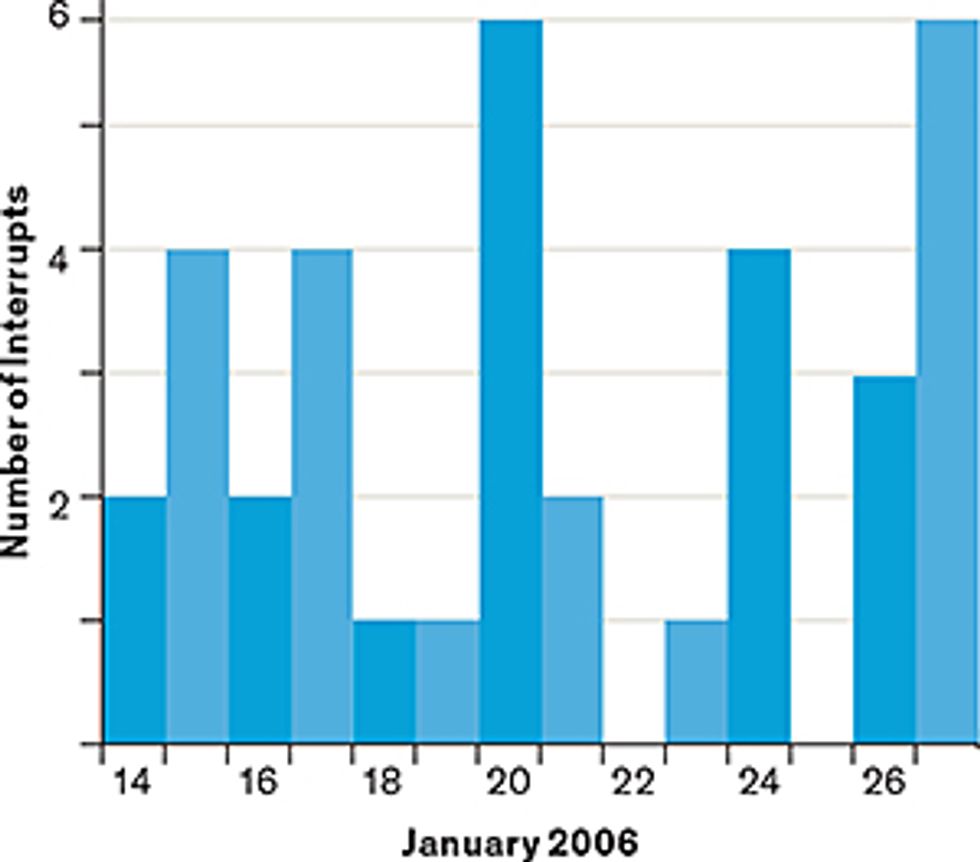 Failure Not Optional: Modern supercomputers are so large that failures are expected to occur regularly. In 2006, the Red Storm supercomputer at Sandia National Laboratories typically suffered a handful of system interruptions each day, for example.Data source: Los Alamos National Laboratory
Failure Not Optional: Modern supercomputers are so large that failures are expected to occur regularly. In 2006, the Red Storm supercomputer at Sandia National Laboratories typically suffered a handful of system interruptions each day, for example.Data source: Los Alamos National Laboratory
In addition to the common case of a single cosmic ray flipping a single bit, in some cases a single high-energy particle cascaded through the memory chip flipping multiple bits. And in a few cases the particle had enough energy to permanently damage a memory location.
ECC can detect and correct a single-bit error in one word of memory (typically 64 bits). If two bits are flipped in a word, ECC can detect that the word is corrupted, but cannot fix it. The study found that double-bit errors occurred about once every 24 hours in Jaguar’s 360 TB of memory.
The surface area of all the silicon in a supercomputer functions somewhat like a large cosmic-ray detector. And as that surface area grows, the number of cosmic-ray strikes also grows. Exascale systems are projected to have up to 100 petabytes of memory—50 times as much as today’s supercomputers—resulting in that much more real estate for a cosmic-ray particle to hit.
But resilience is not all about bit flips and cosmic rays. Even the simplest components can cause problems. The main resilience challenge for Jaguar was a voltage-regulator module. There were 18,688 of them, and whenever one failed, a board carrying two of the machine’s 37,376 hex-core processors powered off.
Two lost processors wasn’t the issue—Jaguar would automatically detect the malfunction and reconfigure the system to work without the problematic board. But that board also contained a network-communication chip, which all other such boards in the system depended on to route messages. When this board powered down, the system would continue to run a while, but it would eventually hang, requiring a reboot of the entire supercomputer to reset all the board-to-board routing tables. While today’s supercomputers do dynamic routing to avoid such failures, the growing complexity of these computing behemoths is increasing the chances that a single fault will cascade across the machine and bring down the entire system.

 Reduce, Reuse, Recycle: When your supercomputer starts showing its age, you have to do something or else the cost of the electricity to run it won’t be worth the results you obtain. But that doesn’t mean you need to throw it out. In 2011 and 2012, Oak Ridge National Laboratory upgraded its Jaguar supercomputer, first installed in 2005, transforming it into a far more capable machine called Titan (see table above). The effort, as shown in these photos, was extensive, but it made Titan No. 1 in the world for a time.Photos: Oak Ridge National Laboratory
Reduce, Reuse, Recycle: When your supercomputer starts showing its age, you have to do something or else the cost of the electricity to run it won’t be worth the results you obtain. But that doesn’t mean you need to throw it out. In 2011 and 2012, Oak Ridge National Laboratory upgraded its Jaguar supercomputer, first installed in 2005, transforming it into a far more capable machine called Titan (see table above). The effort, as shown in these photos, was extensive, but it made Titan No. 1 in the world for a time.Photos: Oak Ridge National Laboratory
Supercomputer operators have had to struggle with many other quirky faults as well. To take one example: The IBM Blue Gene/L system at Lawrence Livermore National Laboratory, in California, the largest computer in the world from 2004 to 2008, would frequently crash while running a simulation or produce erroneous results. After weeks of searching, the culprit was uncovered: the solder used to make the boards carrying the processors. Radioactive lead in the solder was found to be causing bad data in the L1 cache, a chunk of very fast memory meant to hold frequently accessed data. The workaround to this resilience problem on the Blue Gene/L computers was to reprogram the system to, in essence, bypass the L1 cache. That worked, but it made the computations slower.
So the worry is not that the monster I’ve been discussing will come out of the closet. It’s already out. The people who run the largest supercomputers battle it every day. The concern, really, is that the rate of faults it represents will grow exponentially, which could prevent future supercomputers from running long enough for scientists to get their work done.
Several things are likely to drive the fault rate up. I’ve already mentioned two: the growing number of components and smaller transistor sizes. Another is the mandate to make tomorrow’s exascale supercomputers at least 15 times as energy efficient as today’s systems.
To see why that’s needed, consider the most powerful supercomputer in the United States today, a Cray XK7 machine at Oak Ridge called Titan. When running at peak speed, Titan uses 8.2 megawatts of electricity. In 2012, when it was the world’s most powerful supercomputer, it was also the third most efficient in terms of floating-point operations per second (flops) per watt. Even so, scaled up to exaflop size, such hardware would consume more than 300 MW—the output of a good-size power plant. The electric bill to run such a supercomputer would be about a third of a billion dollars per year.
No wonder then that the U.S. Department of Energy has announced the goal of building an exaflop computer by 2023 that consumes only 20 MW of electricity. But reducing power consumption this severely could well compromise system resilience. One reason is that the power savings will likely have to come from smaller transistors running at lower voltages to draw less power. But running right at the edge of what it takes to make a transistor switch on and off increases the probability of circuits flipping state spontaneously.
Further concern arises from another way many designers hope to reduce power consumption: by powering off every unused chip, or every circuit that’s not being used inside a chip, and then turning them on quickly when they’re needed. Studies done at the University of Michigan in 2009 found that constant power cycling reduced a chip’s typical lifetime up to 25 percent.
Power cycling has a secondary effect on resilience because it causes voltage fluctuations throughout the system—much as a home air conditioner can cause the lights to dim when it kicks on. Too large of a voltage fluctuation can cause circuits to switch on or off spontaneously inside a computer.
Using a heterogeneous architecture, such as that of Titan, which is composed of AMD multicore CPUs and Nvidia GPUs (graphics processing units), makes error detection and recovery even harder. A GPU is very efficient because it can run hundreds of calculations simultaneously, pumping huge amounts of data through it in pipelines that are hundreds of clock cycles long. But if an error is detected in just one of the calculations, it may require waiting hundreds of cycles to drain the pipelines on the GPU before beginning recovery, and all of the calculations being performed at that time may need to be rerun.
So far I’ve discussed how hard it will be to design supercomputer hardware that is sufficiently reliable. But the software challenges are also daunting. To understand why, you need to know how today’s supercomputer simulations deal with faults. They periodically record the global state of the supercomputer, creating what’s called a checkpoint. If the computer crashes, the simulation can then be restarted from the last valid checkpoint instead of beginning some immense calculation anew.
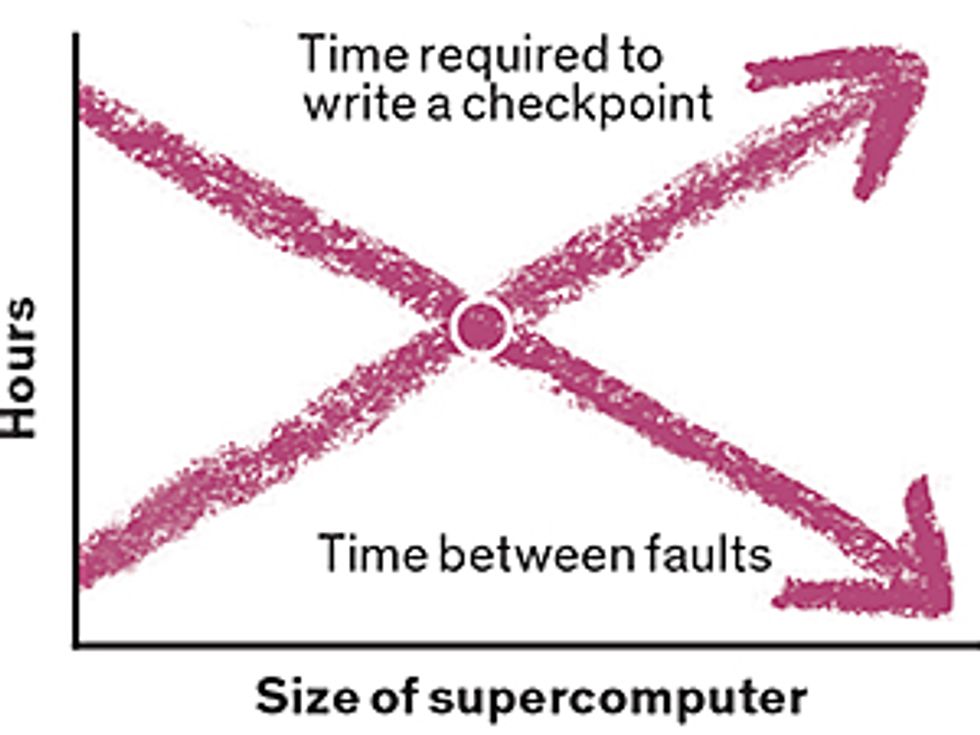 A Looming Crisis: As systems get larger, the time it takes to save the state of memory will exceed the time between failures, making it impossible to use the previous “checkpoint” to recover from errors.Data source: Los Alamos National Laboratory
A Looming Crisis: As systems get larger, the time it takes to save the state of memory will exceed the time between failures, making it impossible to use the previous “checkpoint” to recover from errors.Data source: Los Alamos National Laboratory
This approach won’t work indefinitely, though, because as computers get bigger, the time needed to create a checkpoint increases. Eventually, this interval will become longer than the typical period before the next fault. A challenge for exascale computing is what to do about this grim reality.
Several groups are trying to improve the speed of writing checkpoints. To the extent they are successful, these efforts will forestall the need to do something totally different. But ultimately, applications will have to be rewritten to withstand a constant barrage of faults and keep on running.
Unfortunately, today’s programming models and languages don’t offer any mechanism for such dynamic recovery from faults. In June 2012, members of an international forum composed of vendors, academics, and researchers from the United States, Europe, and Asia met and discussed adding resilience to message-passing interface, or MPI, the programming model used in nearly all supercomputing code. Those present at that meeting voted that the next version of MPI would have no resilience capabilities added to it. So for the foreseeable future, programming models will continue to offer no methods for notification or recovery from faults.
One reason is that there is no standard that describes the types of faults that the software will be notified about and the mechanism for that notification. A standard fault model would also define the actions and services available to the software to assist in recovery. Without even a de facto fault model to go by, it was not possible for these forum members to decide how to augment MPI for greater resilience.
So the first order of business is for the supercomputer community to agree on a standard fault model. That’s more difficult than it sounds because some faults might be easy for one manufacturer to deal with and hard for another. So there are bound to be fierce squabbles. More important, nobody really knows what problems the fault model should address. What are all the possible errors that affect today’s supercomputers? Which are most common? Which errors are most concerning? No one yet has the answers.
And while I’ve talked a lot about faults causing machines to crash, these are not, in fact, the most dangerous. More menacing are the errors that allow the application to run to the end and give an answer that looks correct but is actually wrong. You wouldn’t want to fly in an airliner designed using such a calculation. Nor would you want to certify a new nuclear reactor based on one. These undetected errors—their types, rates, and impact—are the scariest aspect of supercomputing’s monster in the closet.
Given all the gloom and doom I’ve shared, you might wonder: How can an exascale supercomputer ever be expected to work? The answer may lie in a handful of recent studies for which researchers purposely injected different types of errors inside a computer at random times and locations while it was running an application. Remarkably enough, 90 percent of those errors proved to be harmless.
One reason for that happy outcome is that a significant fraction of the computer’s main memory is usually unused. And even if the memory is being used, the next action on a memory cell after the bit it holds is erroneously flipped may be to write a value to that cell. If so, the earlier bit flip will be harmless. If instead the next action is to read that memory cell, an incorrect value flows into the computation. But the researchers found that even when a bad value got into a computation, the final result of a large simulation was often the same.
Errors don’t, however, limit themselves to data values: They can affect the machine instructions held in memory, too. The area of memory occupied by machine instructions is much smaller than the area taken up by the data, so the probability of a cosmic ray corrupting an instruction is smaller. But it can be much more catastrophic. If a bit is flipped in a machine instruction that is then executed, the program will most likely crash. On the other hand, if the error hits in a part of the code that has already executed, or in a path of the code that doesn’t get executed, the error is harmless.
There are also errors that can occur in silicon logic. As a simple example, imagine that two numbers are being multiplied, but because of a transient error in the multiplication circuitry, the result is incorrect. How far off it will be can vary greatly depending on the location and timing of the error.
As with memory, flips that occur in silicon logic that is not being used are harmless. And even if this silicon is being used, any flips that occur outside the narrow time window when the calculation is taking place are also harmless. What’s more, a bad multiplication is much like a bad memory value going into the computation: Many times these have little or no affect on the final result.
So many of the faults that arise in future supercomputers will no doubt be innocuous. But the ones that do matter are nevertheless increasing at an alarming rate. So the supercomputing community must somehow address the serious hardware and software challenges they pose. What to do is not yet clear, but it’s clear we must do something to prevent this monster from eating us alive.
This article appears in the March 2016 print issue as “Supercomputing’s Monster in the Closet.”
To Probe Further
Al Geist is the chief technologist for the computer science and mathematics division at Oak Ridge National Laboratory, in Tennessee, where he’s been studying ways that supercomputers can function in the face of inevitable faults.
From Your Site Articles


