The Conversation (0)

This is part of IEEE Spectrum's special report: Always On: Living in a Networked World.
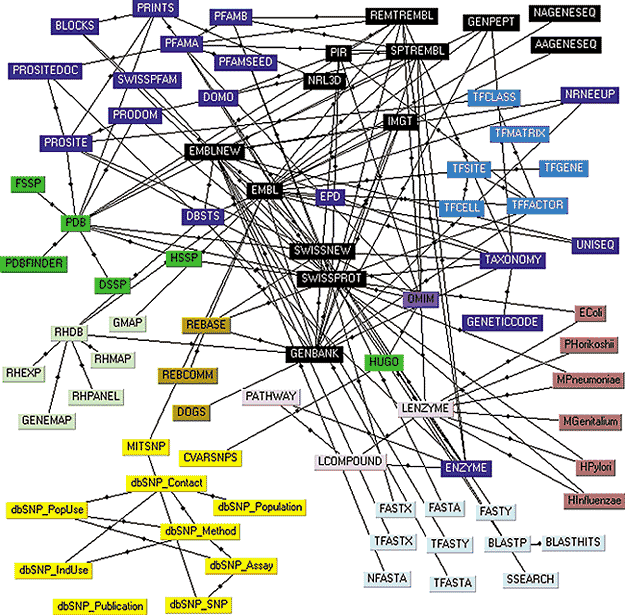
Image: Lion Bioscience AG
Web of Life: Database integration technologies must connect and access a multitude of both public and private databases. These include databases of DNA and protein sequences [black], protein structures [green], sequence patterns [dark blue], gene maps [pale green], single nucleotide polymorphisms [yellow], completed and annotated genomes of particular organisms [dark pink], transcription factors [light blue], literature associating genes with disease [purple], restriction enzymes [gold], and metabolic enzymes and metabolic pathways [pink]. Interconnecting lines indicate where records in one database reference records in another.
Click image to enlarge.
With a working copy of the human genome in hand, the hard task of making sense of the terabytes of data has begun. One way of doing that job is by comparing gene sequences with other types of biological information, including protein sequences and structures or genes identified or expressed in other creatures. The trouble is that this other information is held in hundreds of databases out in research institutions and companies around the world. They are not stored in any common format but use different syntaxes and a variety of sometimes incompatible database technologies, ranging from ad hoc systems to relational databases to object-oriented systems.
The current state of dealing with biological pathways is like trying to use the Internet when Gopher was the only navigation tool
But help is in the offing. Several groups have developed tools to fuse the sprawling horde into distributed-federated systems, collections of otherwise incompatible sets of data that can be searched as if they were one database. For the effort really to succeed, some bioinformatics experts say that standards must eventually be set for how data is stored and retrieved.
Since data comes in different formats, queries must be targeted at each database in ways that are peculiar to each system--an irksome task for the busy biologist. Linking the databases so that they appear to be a single unit is done with software that understands the format of the associated systems and can translate queries into the syntax and schema used by individual databases [see figure above].
One such tool was built by the University of Pennsylvania in Philadelphia. Researchers in its Kleisli Project developed software that lets scientists use a single query interface to compare their data against a variety of collections.
Industrial solutions exist as well. LION Bioscience AG, in Heidelberg, Germany, markets a tool called SRS that drives the integration of databases for many pharmaceutical firms, including Aventis, Sumitomo Pharmaceuticals, and Bayer, as well as the genomics information company Celera Genomics and the European Bioinformatics Institute, which is a major government-sponsored site that integrates a large number of public databases.
In a US $100 million push, IBM Corp. recently began targeting the life sciences with its DiscoveryLink database integration scheme. Celera competitor Incyte Genomics of Palo Alto, Calif., has taken IBM's DiscoveryLink integrator, a generic tool, and made it industry-specific by adding an interface layer designed to handle biological data. That layer also acts to encapsulate and manipulate data as objects--an aggregation of values that has identity independent of those values, as opposed to records in a relational database, which are identified by their values and are thought to be less reflective of biology.
However, keeping object databases up to date with the way biological data is used, derived, and thought about has always been that technology's Achilles' heel. Early versions of biological object databases did not scale well, according to Tim Clark, vice president of bioinformatics at Millennium Pharmaceuticals Inc., Cambridge, Mass. Biological thought and technique moved so quickly that developers were constantly rewriting the rules of their databases to keep up with advances and new types of data. For instance, the activation of multiple genes over time as a cell responds to a drug can now be studied using DNA microarrays, a technology that did not exist a decade ago.
Settling on standards for information storage, retrieval, and categorization should help harmonize the growing number of disparate data types while making objects more useful. But those standards will be moving targets. Several consortia, including the BioPathways Consortium, Genostar in France, and the life sciences arm of the Object Management Group, are working out standards for the retrieval and exchange of biological data, and some recommendations are expected early this year. What may also help speed standardization is the adoption of XML (for Extensible Markup Language) as a language for transferring data, because it clearly tags data passed from one party to the next. A group known as BioXML is currently devising a set of standard tags relevant to many sectors of biology.
"People get religious about ontology"
These standards are based as much on technical considerations as on settling on ontologies--those formal specifications of how to represent biological concepts such as genes and proteins and their relationships with each other. For instance, one relationship that remains largely unchanged is the concept that DNA is translated into ribonucleic acid, which is then translated into a protein. But such standard- setting is slow and sometimes contentious. "People get religious about ontology," said Stephen Lincoln, formerly Incyte's vice president of informatics, now a senior vice president at Informax of Rockville, Md., --"as if God came down from heaven and said what's a subcategory of what."
The need for more standardized handling of biological information is expected to become critical in coming years, as biology and pharmaceutical research shifts from an academic-style pursuit to a high-throughput industrial-scale effort. Right now, most academic databases are built in a researcher's spare time, in an ad hoc manner meant to deal with the particulars of the database's use. But techniques for generating biological data, and the type and amount of data they produce, are multiplying faster than ever before.
What's more, as post-genomic information such as protein structures and chemical interactions piles on, the focus of the information will shift downstream from the gene to the biochemical pathways that detail the interaction of genes and their products to produce a function in an organism. This is a far more involved concept to represent in databases, though collections based on biochemical pathways exist, such as Japan's KEGG, or Kyoto Encyclopedia of Genes and Genomes.
Scientists have high hopes that this shift will lead to better biology and drug development, since such databases will better reflect the fact that most diseases interact with a network of genes rather than a single gene.
Eric Neumann, vice president for life science informatics at the consulting firm 3rd Millennium Inc., in Cambridge, Mass., likens the current state of dealing with biological pathways in databases to trying to use the Internet when Gopher was the only navigation tool. "You had to know a lot about what you were looking for," he said. He suggests that the current Internet structure, with links within its own content, may be the future of biology. The value of the data will be in how it connects with other data, rather than just its own content, he said.
Numbers to ponder: IBM predicts the IT market for life sciences will grow from $3.5 billion to more than $9 billion by 2003. The volume of life science data doubles every six months.
To Probe Further
Minoru Kanehisa's Post-genome Informatics gives a useful overview of the types of data and databases used in bioinformatics. The book was published by Oxford University Press in 2000.


