





















For the next few months, we’ll be taking a new look at the classic era of video games. In our series Back to the Arcade, we'll examine how games like Asteroids, PacMan, and Donkey Kong kicked off a revolution that has blossomed into an industry worth US $45 billion per year worldwide.
In our first installment, we examine arcade-game glitches.
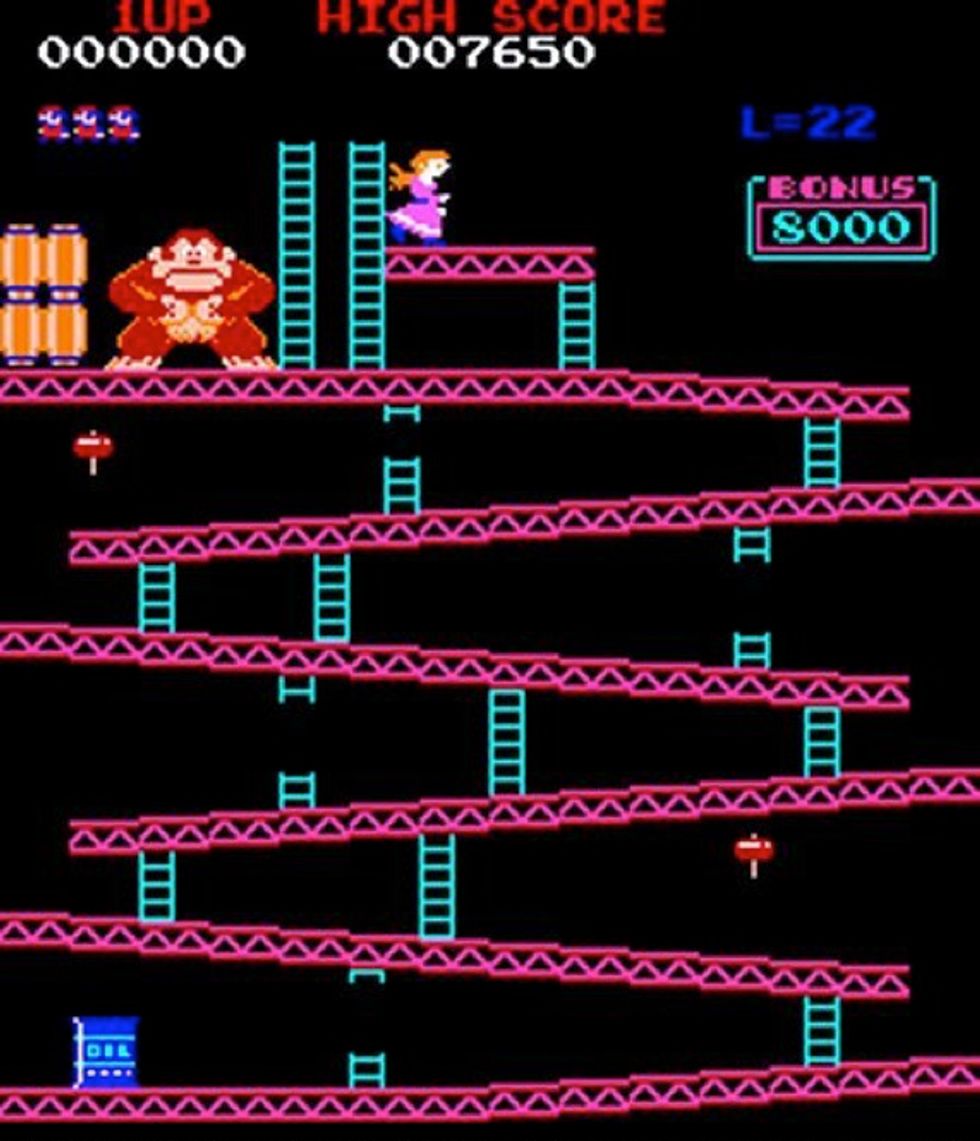
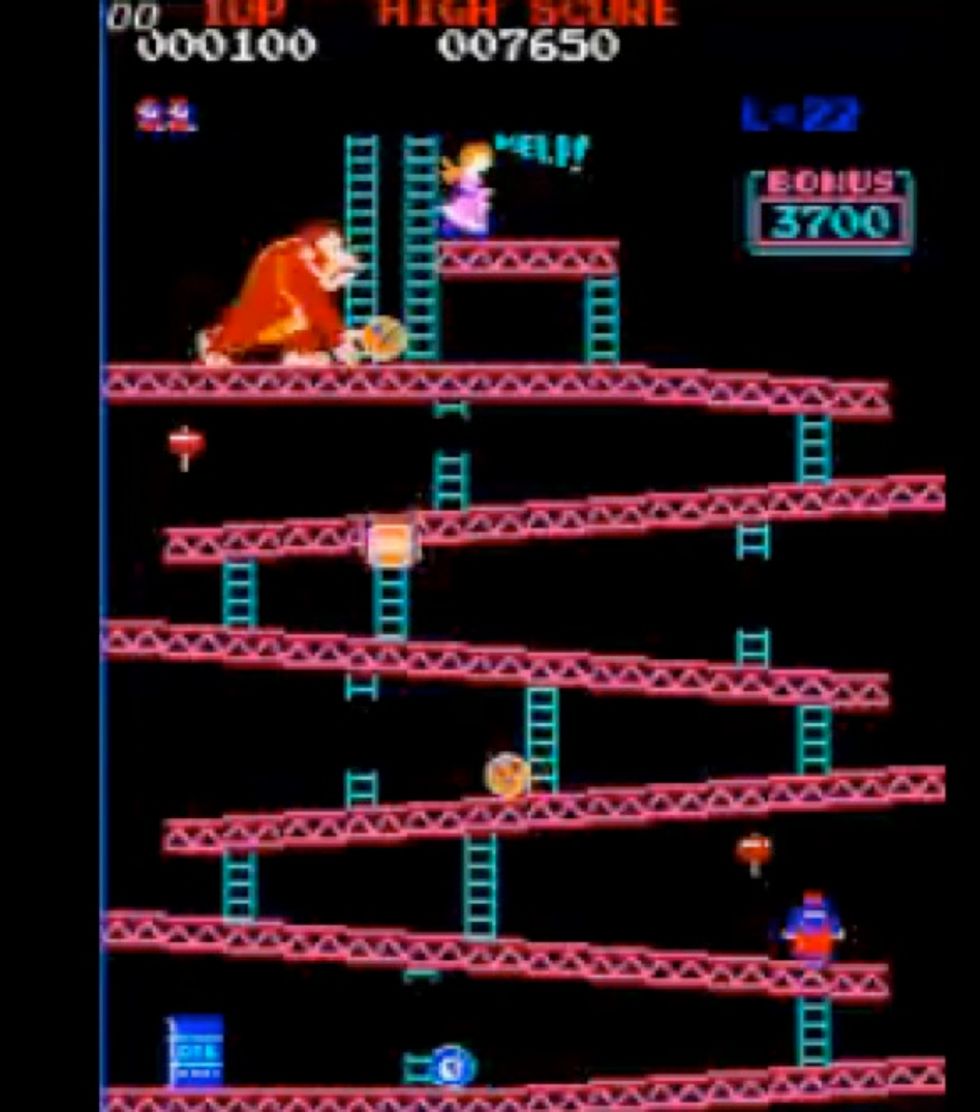
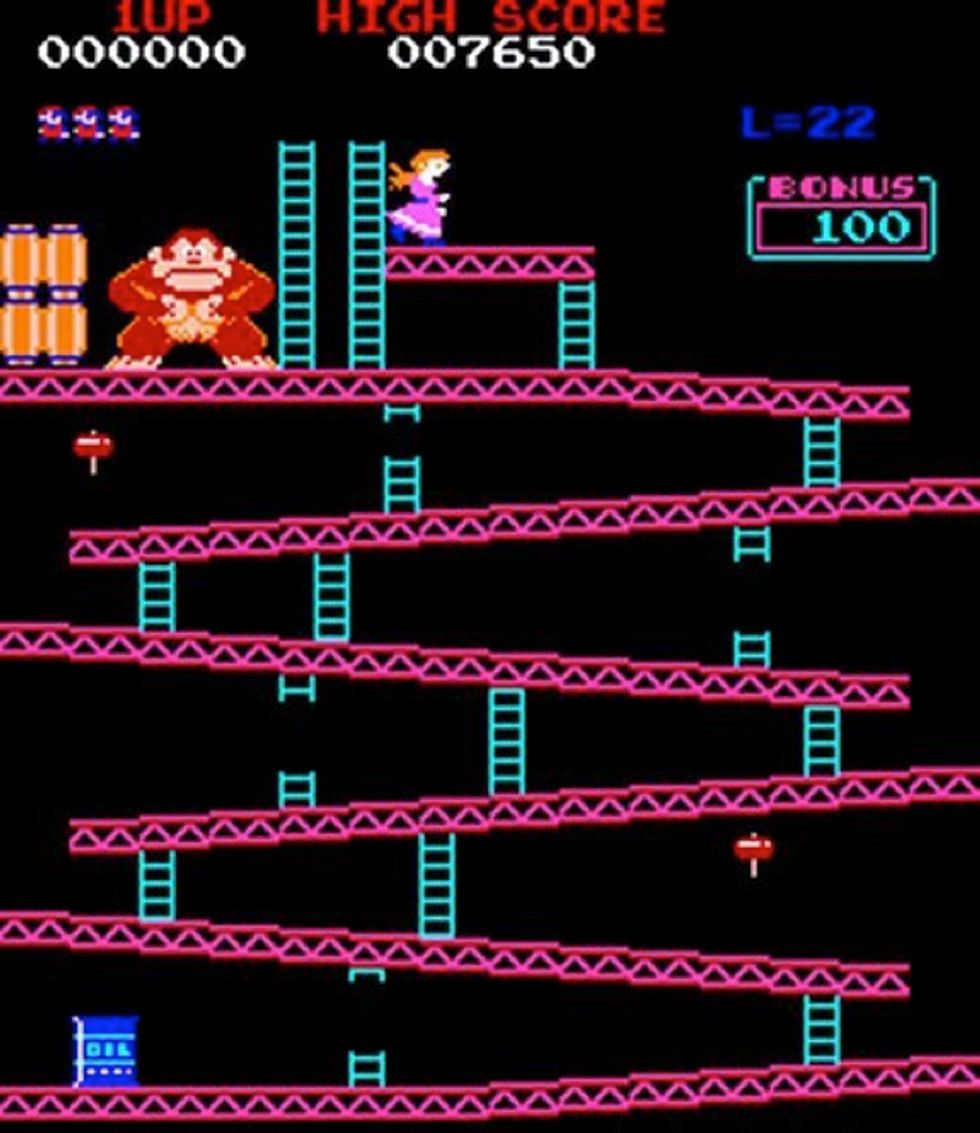
Scott Patterson oversees part of the referee team of Twin Galaxies, the official video-game world-record keepers. He's been keeping track of video-game glitches since the early '80s. Here he describes five classic arcade-game glitches and what made each one significant. What are some of your other favorite arcade glitches? Tell us in the comment section below.
The Conversation (0)