
Artificial-intelligence systems today increasingly determine whether someone gets a job or a loan, how much they’re paid, how they’re treated by doctors and hospitals, and how fairly they’re dealt with by government, law enforcement, and the justice system.
If the AI behind these autonomous decision-making systems is biased—more likely to discriminate against people on the basis of race, religion, sex, or other criteria—then that problem can be very difficult to weed out.
AI’s profound bias problems have become public in recent years, thanks to researchers like Joy Buolamwini and Timnit Gebru, authors of a 2018 study that showed that face-recognition algorithms nearly always identified white males but recognized black women only two-thirds of the time. Consequences of that flaw can be serious if law enforcement used the algorithms to identify suspects, for example. Google’s recent firing of Gebru and Margaret Mitchell (who together led the search giant’s Ethical A.I. team)—as well as at least one more recent resignation of Google AI professionals which may be related to the firings—shows that bias in AI is a prickly topic for tech companies.
“But it is also an opportunity,” says Alexandra Ebert, chief trust officer at the Vienna-based synthetic-data startup Mostly AI: a chance for businesses, data scientists, and engineers to begin the hard but important work of extricating bias from AI data sets and algorithms, and eventually also from society.
Because while users of an AI system can unknowingly introduce bias based on how they use it, developers might carry a bigger burden to reduce that bias in the first place. “If a bridge falls, it may not always be the fault of the designer, but you have to ask if the designer did their best to make sure that failure would not happen,” said Osonde Osoba, a senior information scientist at the RAND Corporation. Plus, acknowledging and addressing bias could “make sense for the bottom line,” he said.
Removing bias from AI is not easy because there’s no one cause for it. It can enter the machine-learning cycle at various points. But the logical and most promising starting point seems to be the data that goes into it, says Ebert. AI systems rely on deep neural networks that parse large training data sets to identify patterns. These deep-learning methods are roughly based on the brain’s structure, with many layers of code linked together like neurons, and weights given to the links changing as the network picks up patterns.
The problem is, training data sets may lack enough data from minority groups, reflect historical inequities such as lower salaries for women, or inject societal bias, as in the case of Asian-Americans being labeled foreigners. Models that learn from biased training data will propagate the same biases. But collecting high-quality, inclusive, and balanced data is expensive.
So Mostly AI is using AI to create synthetic data sets to train AI. Simply removing sensitive features like race or changing them—say, increasing female salaries to affect approved credit limits—does not work because it interferes with other correlations. Instead, the startup uses a deep neural network that learns all the patterns and correlations in a data set and automatically generates a whole new individual—for instance, one “who behaves like a female with higher income would behave, so that all the data points from the person match up and make sense,” Ebert says. The synthetic data sacrifices accuracy slightly compared to that of the original data but is still statistically highly representative.
Other startups like London-based Synthesized have thrown their hats into the synthetic data game. Mostly AI and a few other companies are now in the process of launching an IEEE standards group on synthetic data, Ebert adds.
Researchers have also developed several tools to help reduce bias in AI. Tool kits like Aequitas measure bias in uploaded data sets, while others like Themis–ml also offer a few ways to reduce that bias using bias-mitigation algorithms.
A team at IBM led by Kush Varshney has brought these efforts together to create a comprehensive open-source tool kit called AI Fairness 360, which helps detect and reduce unwanted bias in data sets and machine-learning models (see infographic, below). It brings together 14 different bias-mitigation algorithms developed by computer scientists over the past decade, and is intuitive to use. “The idea is to have a common interface to make these tools available to working professionals,” said Varshney.
Some of the algorithms in the tool kit massage training data in sophisticated ways. For instance, they change how certain inputs and outputs are paired (a zip code with “yes” on loan approval), or the weights that are given to specific pairs. A technique called Reweighing, for instance, gives higher weight to input/output pairs that give the underprivileged group a positive outcome.
Other algorithms tweak the machine-learning process instead of the training data. The goal of machine-learning models is to predict an outcome as accurately as possible. So if the training set has more data on group A than group B, the program will optimize for that group because it boosts accuracy. But there are ways to nudge the models during training to make them return accurate outcomes across groups.
There’s no one size fits all solution, Varshney said. How an algorithm increases fairness depends on the dataset. “We can’t say a priori that this algorithm will work best for your fairness problem or dataset,” he said. “You have to figure out which algorithm is best for your data.” But using the bias-reducing toolkit is not extremely complicated, he said. “There’s some nuance to it, but once you make up your mind to mitigate bias, yes you can do it.”
Yet it’s hard to know how your model will behave in the real world. This makes external audits of an AI system crucial. An AI algorithm can look perfect and yet perform miserably for some stakeholders, says Cathy O’Neil, data scientist and founder of O’Neill Risk Consulting & Algorithmic Auditing. “I test the code as a black box to see how it performs,” she says. “I ask the broad question: Who does your algorithm fail? Soon as you ask that question—boom, there’s all sorts of things that can go wrong.”
Realistically, though, it is almost impossible to fully eliminate bias, Varshney said. Not only because it can enter in several ways during data collection and processing, and in the modeling pipeline, but also because fairness can mean different things to different people. Making a system fairer to all African-Americans might make it unfair for some people in that group.
Plus, there is usually a tension between fairness and accuracy. If a dataset contains 70% from group A and 30% from group B, the ratio of people whose loans are approved should be the same by one definition called demographic parity. But that is unfair if a larger percentage of people in group B have defaulted on their loans.
Investing the time and effort to make AI models fairer comes with a cost. So without regulatory pressure, companies find it easier to focus on how accurately their systems reflect the original data. But a Gartner Research study predicted that by 2022, 85 percent of AI projects will deliver wrong outcomes due to bias in data, algorithms, or the teams responsible for managing them. So AI decision-making tools that are both accurate and fair would not only be more useful for a larger group of potential customers, says Mostly AI’s Ebert, but also prevent a reputational hit and customer backlash when bias in proprietary AI shows up. “We need to ensure that AI benefits us,” she says. “But debiased AI can also lead to higher benefits for businesses.”
Teaching Computers to Unlearn
Bias-mitigation algorithms can make predictions of an AI system more fair and less prone to discrimination. Pictured here are results of a ProPublica study of a criminal-sentencing program called (Correctional Offender Management Profiling for Alternative Sanctions). COMPAS scores, as ProPublica pointed out, “inform decisions about who can be set free at every stage of the criminal justice system.” In its predictions of the likelihood of inmates’ reoffending, COMPAS got it wrong twice as often with nonwhite inmates as it did their white fellow prisoners. COMPAS also incorrectly tagged men as high-risk for reoffending three times as often as it did for women.
But as IBM researchers show in a demo associated with their AI tool kit, an algorithm called Reweighing (Algorithm 1 in the chart) greatly mitigates bias related to sex, and even flips the bias with respect to race. Meanwhile, another algorithm called Optimized Preprocessing (Algorithm 2) almost eliminates racial bias—at least according to the present metrics—but fares poorly in debiasing the data related to sex. A third algorithm, Adversarial Debiasing, corrects fairly well for sex-related bias but does not debias the data very well at all with respect to race.
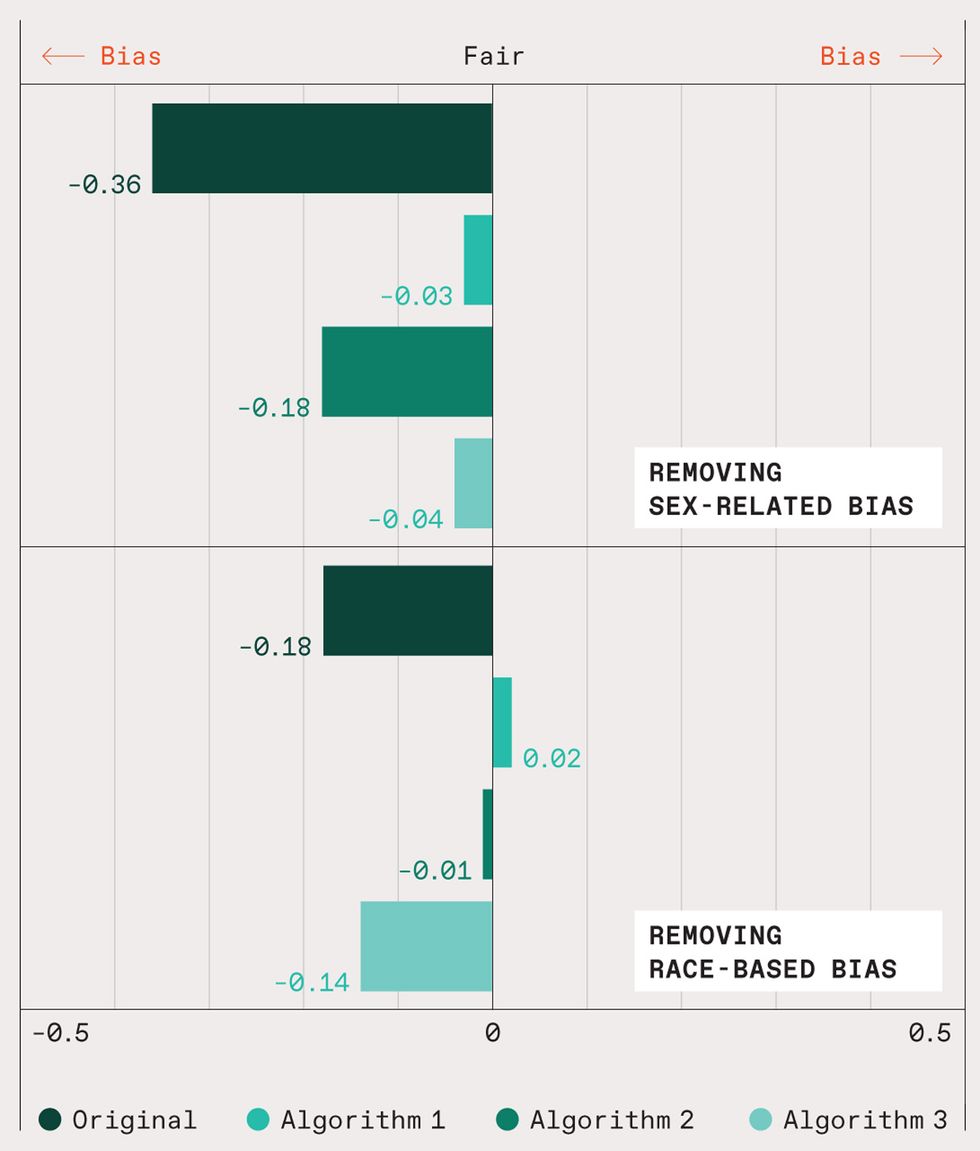 Illustration: Spectrum Staff
Illustration: Spectrum Staff
- Are You Still Using Real Data to Train Your AI? - IEEE Spectrum ›
- Timnit Gebru Is Building a Slow AI Movement ›
- Timnit Gebru Is Building a Slow AI Movement - IEEE Spectrum ›
- Nvidia Is Piloting a Generative AI for its Engineers - IEEE Spectrum ›
- The Battle for Better, Broader, More Inclusive AI - IEEE Spectrum ›


