The Conversation (0)


Not long after the first personal computers started entering people’s homes, Intel fell victim to a nasty kind of memory error. The company, which had commercialized the very first dynamic random-access memory (DRAM) chip in 1971 with a 1,024-bit device, was continuing to increase data densities. A few years later, Intel’s then cutting-edge 16-kilobit DRAM chips were sometimes storing bits differently from the way they were written. Indeed, they were making these mistakes at an alarmingly high rate. The cause was ultimately traced to the ceramic packaging for these DRAM devices. Trace amounts of radioactive material that had gotten into the chip packaging were emitting alpha particles and corrupting the data.
Once uncovered, this problem was easy enough to fix. But DRAM errors haven’t disappeared. As a computer user, you’re probably familiar with what can result: the infamous blue screen of death. In the middle of an important project, your machine crashes or applications grind to a halt. While there can be many reasons for such annoying glitches—including program bugs, clashing software packages, and malware—DRAM errors can also be the culprit.
For personal-computer users, such episodes are mostly just an annoyance. But for large-scale commercial operators, reliability issues are becoming the limiting factor in the creation and design of their systems.
Big Internet companies like Amazon, Facebook, and Google keep up with the growing demand for their services through massive parallelism, with their data centers routinely housing tens of thousands of individual computers, many of which might be working to serve just one end user. Supercomputer facilities are about as big and, if anything, run their equipment even more intensively.
In computing systems built on such huge scales, even low-probability failures take place relatively frequently. If an individual computer can be expected to crash, say, three times a year, in a data center with 10,000 computers, there will be nearly 100 crashes a day.
Our group at the University of Toronto has been investigating ways to prevent that. We started with the simple premise that before we could hope to make these computers work more reliably, we needed to fully understand how real systems fail. While it didn’t surprise us that DRAM errors are a big part of the problem, exactly how those memory chips were malfunctioning proved a great surprise.
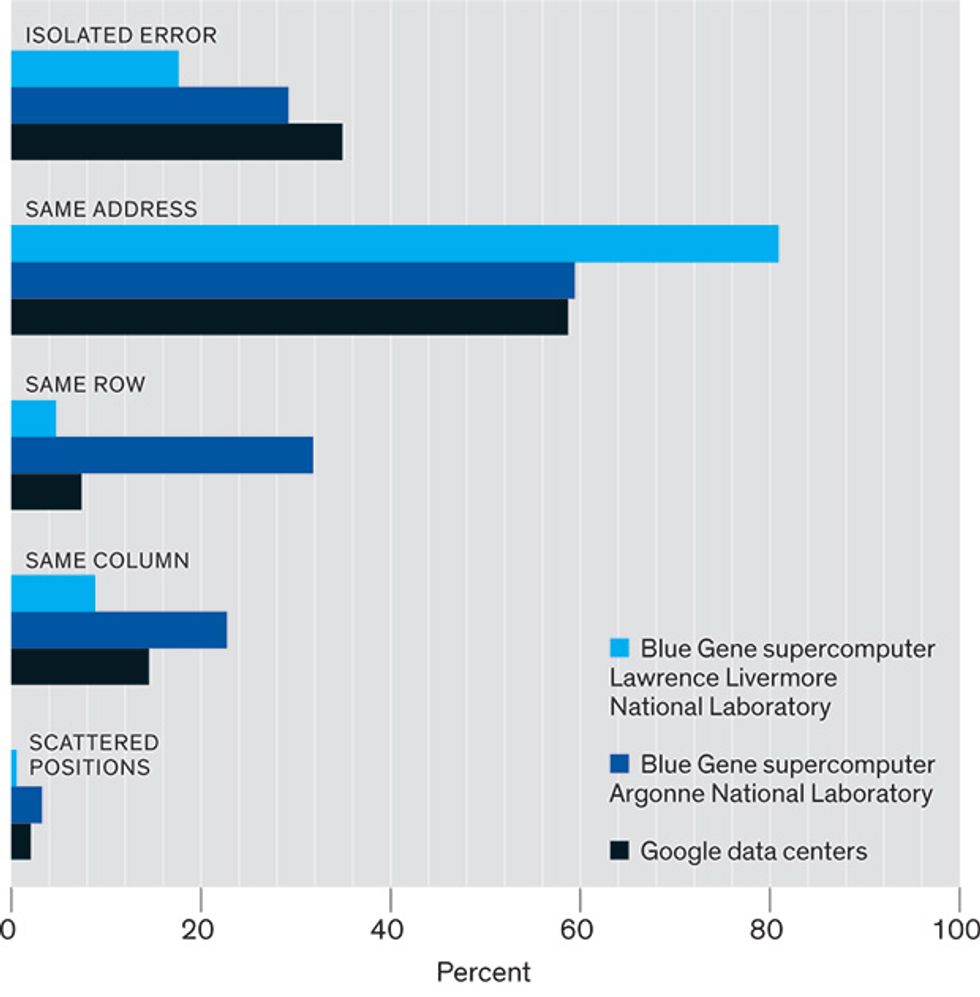 Flavors of Goofs: Most often DRAM errors repeatedly affect the same address—or perhaps just the same row or column—rather than being isolated occurrences.Source: Hwang, Stefanovici, and Schroeder,
Proceedings of ASPLOS XVII, 2012
Flavors of Goofs: Most often DRAM errors repeatedly affect the same address—or perhaps just the same row or column—rather than being isolated occurrences.Source: Hwang, Stefanovici, and Schroeder,
Proceedings of ASPLOS XVII, 2012
To probe how these devices sometimes fail, we collected field data from a variety of systems, including a dozen high-performance computing clusters at Argonne National Laboratory, Lawrence Livermore National Laboratory, and Los Alamos National Laboratory. We also obtained information from operators of large data centers, including companies such as Google, about their experiences.
We made two key observations: First, although most personal-computer users blame system failures on software problems (quirks of the operating system, browser, and so forth) or maybe on malware infections, hardware was the main culprit. At Los Alamos, for instance, more than 60 percent of machine outages came from hardware issues. Digging further, we found that the most common hardware problem was faulty DRAM. This meshes with the experience of people operating big data centers, DRAM modules being among the most frequently replaced components.
An individual memory cell in a modern DRAM chip is made up of one capacitor and one transistor. Charging or discharging that capacitor stores one bit of information. Unlike static RAM, which keeps its data intact as long as power is applied to it, DRAM loses information, because the electric charge used to record the bits in its memory cells slowly leaks away. So circuitry must refresh the charge state of each of these memory cells many times each second—hence the appellation “dynamic.” Although having to include refresh circuitry complicates the construction of memory modules, the advantage of DRAM is that the capacitors for the memory cells can be made exceedingly small, which allows for billions of bits on a single chip.
A DRAM error arises when one or more bits that are written in one way end up being read in another way. Most consumer-grade computers offer no protection against such problems, but servers typically use what is called an error-correcting code (ECC) in their DRAM. The basic strategy is that by storing more bits than are needed to hold the data, the chip can detect and possibly even correct memory errors, as long as not too many bits are flipped simultaneously. But errors that are too severe can still cause machines to crash.
Although the general problem is well known, what stunned us when analyzing data from Lawrence Livermore, Argonne, and Google (and a few other sites later on) was how common these errors are. Between 12 percent and 45 percent of machines at Google experience at least one DRAM error per year. This is orders of magnitude more frequent than earlier estimates had suggested. And even though the machines at Google all employ various forms of ECC, between 0.2 percent and 4 percent of them succumb to uncorrectable DRAM errors each year, causing them to shut down unexpectedly.
How can a problem whose existence has been known for more than three decades still be so poorly understood? Several reasons. First off, although these failures occur more often than anybody would like, they’re still rare enough to require very large data sets to obtain statistically significant frequency estimates: You have to study many thousands of machines for years. As a result, most reliability estimates for DRAM are produced in the lab—for example, by shooting particle beams at a device to simulate the effects of cosmic rays, which were long thought to be the main cause of these errors. The idea was that a high-energy cosmic ray would hit a gas molecule in the atmosphere, giving rise to a zoo of other particles, some of which could in turn cause bit errors when they hit a DRAM chip.
Another reason it’s so hard to get data on memory failures “in the wild” is that manufacturers and companies running large systems are very reluctant to share information with the public about hardware failures. It’s just too sensitive.
DRAM errors can usually be divided into two broad categories: soft errors and hard errors. Soft errors occur when the physical device is perfectly functional but some transient form of interference—say, a particle spawned by a cosmic ray—corrupts the stored data. Hard errors reflect problems with the physical device itself, where, for example, a specific bit in DRAM is permanently stuck at 0 or 1.
The prevailing wisdom is that soft errors are much more common than hard errors. So nearly all previous research on this topic focused on soft errors. Curiously, before we began our investigations, there were no field studies available even to check this assumption.
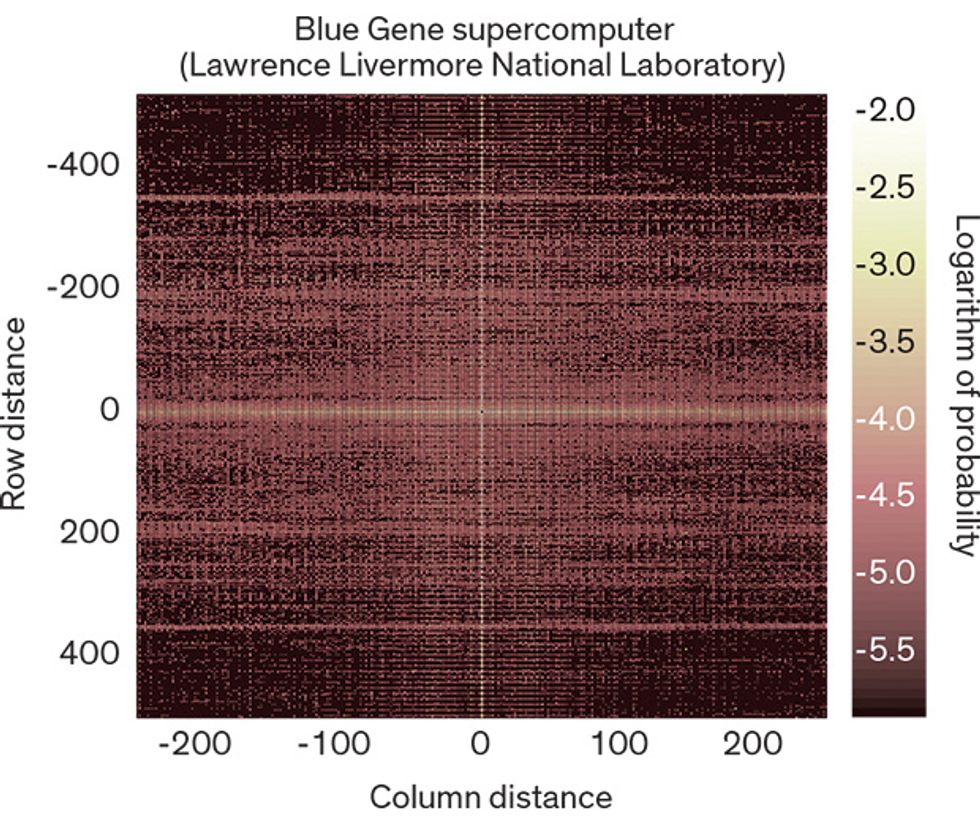 In the Crosshairs: Once a DRAM error occurs, the likelihood of other errors in the same row or column of memory cells increases. The likelihood of errors even grows for nearby rows or columns, as seen in this “heat map” of error correlations.Source: Hwang, Stefanovici, and Schroeder,
Proceedings of ASPLOS XVII, 2012
In the Crosshairs: Once a DRAM error occurs, the likelihood of other errors in the same row or column of memory cells increases. The likelihood of errors even grows for nearby rows or columns, as seen in this “heat map” of error correlations.Source: Hwang, Stefanovici, and Schroeder,
Proceedings of ASPLOS XVII, 2012
To test this widely held belief—indeed, to answer many open questions about memory errors—we examined large-scale computing systems with a wide variety of workloads, DRAM technologies, and protection mechanisms. Specifically, we obtained access to a subset of Google’s data centers, two generations of IBM’s Blue Gene supercomputer (one at Lawrence Livermore and one at Argonne), as well as the largest high-performance cluster in Canada, housed at the SciNet supercomputer center at the University of Toronto. Most of these facilities were already logging the relevant data, although we needed to work with SciNet’s operators on that. In total, we analyzed more than 300 terabyte-years of DRAM usage.
There was some unquestionably good news. For one, high temperatures don’t degrade memory as much as people had thought. This is valuable to know: By letting machines run somewhat hotter than usual, big data centers can save on cooling costs and also cut down on associated carbon emissions.
One of the most important things we discovered was that a small minority of the machines caused a large majority of the errors. That is, the errors tended to hit the same memory modules time and again. Indeed, we calculated that the probability of having a DRAM error nearly doubles after a machine has had just two such errors. This was startling, given the prevailing assumption that soft errors are the dominant failure mode. After all, if most errors come from random events such as cosmic rays, each DRAM memory chip should have an equal chance of being struck, leading to a roughly uniform distribution of errors throughout the monitored systems. But that wasn’t happening.
To understand more about our results, you need to know that a DRAM device is organized into several memory banks, each of which can be thought of as a 2-D array of memory cells laid out in neat rows and columns. A particular cell inside an array can be identified by two numbers: a row index and a column index.
We found that more than half the memory banks suffering errors were failing repeatedly at the same row and column address—that is, at the location of one iffy cell. Another significant fraction of the errors cropped up in the same row or same column each time, although the exact address varied.
It’s unlikely, of course, that the same location on a device would be hit twice by an errant nuclear particle. Extremely unlikely. This is clear evidence that, contrary to prevailing notions, hard DRAM errors are more common than soft ones.
What are we to make of the unexpected prevalence of hard errors? The bad news is that hard errors are permanent. The good news is that they are easy to work around. If errors take place repeatedly in the same memory address, you can just blacklist that address. And you can do that well before the computer crashes. Remember, the only errors that really matter are the ones that flip too many bits for ECC to correct. So errors that corrupt fewer bits could be used as an early warning that drastic measures should be taken before a crash occurs.
Our investigation showed that this strategy could indeed work well: More than half of the catastrophic multibit errors followed earlier errors that were less severe and thus correctable. So with the proper mechanisms in place, most crash-inducing DRAM glitches could be prevented. Indeed, rather than just relying on ECC or other expensive kinds of correction hardware, computer operating systems themselves could help to protect against memory errors.
 Rows and Columns: This image shows the internal makeup of a typical DRAM chip, in this case Micron Technology’s MT4C1024, which stores 2
20 bits of information (1 mebibit).Image: ZeptoBars
Rows and Columns: This image shows the internal makeup of a typical DRAM chip, in this case Micron Technology’s MT4C1024, which stores 2
20 bits of information (1 mebibit).Image: ZeptoBars
Operating systems typically divide the computer’s main memory into areas known as pages (usually 4 kilobytes in size). And from the operating system’s point of view, the majority of errors come from a very small fraction of the available pages. Indeed, more than 85 percent of the errors come from just 0.0001 percent of all the pages. By removing those problematic pages from use, the operating system could prevent most of the risk of errors without giving up much memory capacity.
Although others have previously proposed this very tactic, known as page retirement, it’s seldom used. None of the organizations we worked with for our DRAM study employed it. One reason might be that people just didn’t realize how often DRAM errors tend to crop up in the same page of memory. After our research brought that fact to light, Facebook adopted page retirement in its data centers. But it’s still not widely used, perhaps because there’s still some confusion about what sort of page-retirement schemes would work best.
To help clarify that issue, we investigated five simple policies. Some were as conservative as “Retire a page when you see the first error on it.” Others involve trying to prevent row or column errors by retiring the entire row or column as soon as one memory cell starts to show problems. We used the data we collected to see how well such policies might protect real computer systems, and we found that almost 90 percent of the memory-access errors could have been prevented by sacrificing less than 1 megabyte of memory per computer—a tiny fraction of what is typically installed.
Sure, a technician could replace the entire memory module when it starts to have errors. But it would probably have only a few bad cells. Page retirement could isolate the regions of memory prone to errors without sacrificing the other parts of an otherwise functional module. Indeed, applying sensible page-retirement policies in large data centers and supercomputing facilities would not only prevent the majority of machine crashes, it would also save the owners money.
The same applies to consumer gadgets. With the growing ubiquity of smartphones, tablets, wearable electronics, and other high-tech gear, the number of devices that use DRAM memory is skyrocketing. And as DRAM technology advances, these devices will contain ever-larger quantities of memory, much of which is soldered straight onto the system board. A hard error in such DRAM would normally require replacing the entire gizmo. So having the software retire problematic parts of memory in such an environment would be especially valuable.
Had we accepted the received wisdom that cosmic rays cause most DRAM errors, we would never have started looking at how these chips perform under real-world conditions. We would have continued to believe that distant events far off in the galaxy were the ultimate cause of many blue screens and server crashes, never realizing that the memory errors behind them usually stem from underlying problems in the way these chips are constructed.
In that sense, DRAM chips are a little like people: Their faults are not so much in their stars as in themselves. And like so many people, they can function perfectly well once they compensate for a few small flaws.
This article originally appeared in print as “Battling Borked Bits”
About the Author
Ioan Stefanovici and coauthor Andy Hwang are computer science grad students at the University of Toronto, studying under third coauthor Bianca Schroeder. The three have worked together to understand errors in dynamic random-access memory. “It’s a fairly rare phenomenon,” says Stefanovici. “You buy DRAM and assume it works.” But as the authors show, sometimes that’s a faulty assumption, particularly for a giant data center or supercomputer.


