The Conversation (0)

Photo-illustration: Sean McCabe
Back in 2011, when the venture capitalist Marc Andreessen said that “software is eating the world,” it was still a fresh idea. Now it’s obvious that software permeates our lives. From complex electronics like medical devices and autonomous vehicles to simple objects like Internet-connected lightbulbs and thermometers, we’re surrounded by software.
And that means we’re all more exposed to attacks on that software than ever before.
Every year, 111 billion lines are added to the mass of software code in existence, and every line presents a potential new target. Steve Morgan, founder and editor in chief at the research firm Cybersecurity Ventures, predicts that system break-ins made through a previously unknown weakness—what the industry calls “zero-day exploits”—will average one per day in the United States by 2021, up from one per week in 2015.
It was to solve this problem that my colleagues and I at Carnegie Mellon University (CMU), in Pittsburgh, spent nearly 10 years building technology that would make software safe, automatically. Then, in 2012, we founded ForAllSecure to bring our product to the world. The one thing we needed was a way to prove that we could do what we said we could do, and we got it in the form of a prize competition.
 The Magnificent Seven: Competing computers glow as they glower at the audience attending the finals of the Cyber Grand Challenge, held in Las Vegas in 2016.Photo: DARPA
The Magnificent Seven: Competing computers glow as they glower at the audience attending the finals of the Cyber Grand Challenge, held in Las Vegas in 2016.Photo: DARPA
Fast-forward to 2016: My team is huddled in a hotel ballroom in Las Vegas, chewing our fingernails and fairly sure that we had just lost a competition we’d spent thousands of hours preparing for. It was the DARPA Cyber Grand Challenge (CGC), one of several such events—like the one for self-driving vehicles back in the early 2000s—staged by the U.S. Defense Advanced Research Projects Agency to stimulate technological breakthroughs for national security. The CGC grew out of DARPA’s recognition that the United States might one day find itself without the manpower or the tools to fend off cyberthreats.
The cybersecurity battleground is populated by hackers who are technically skilled and, at the highest levels, creative in exploiting weaknesses in software to penetrate an organization’s defenses. The criminals who do this for their own gain are commonly called black hats, and they often create tools that legions of amateur “script kiddies” can use to unleash havoc, like the IoT botnets that in 2016 launched a massive attack on the Internet after gaining control over minicams and video recorders in people’s homes. In contrast, “white hats” use their skills to thwart such attacks. But there simply aren’t enough white-hat hackers to protect all the software proliferating in the commercial world, let alone the common infrastructure and the military platforms vital to national and global security.
In 2014, DARPA announced the Cyber Grand Challenge as a two-year project with the goal of testing whether it was possible to develop AI systems that could find, verify, and patch software weaknesses. In 2015, some 100 teams entered the prequalification stage. In 2016, the top seven advanced to the grand championship finale, where they’d need to enter a full cyber-reasoning system—one that would not merely notice a problem but could also infer its nature. The champion would win US $2 million, and the second- and third-place finishers would get $1 million and $750,000, respectively.
After DARPA released details about its competition, it dawned on my colleagues and me that this was a great opportunity to demonstrate that the automated cybersecurity we’d developed was no mere theoretical game. After spinning out ForAllSecure, we’d consistently faced skepticism about how practical our solution could be. We figured that we’d better win the DARPA competition, given that we’d been working on this for a decade.
Our research at CMU had begun with a simple premise: People need a way to check the software they’re buying and ensure that it’s safe. Coders will, of course, make a due-diligence effort to flush out security flaws, but their main concerns are always more basic: They have to ship their product on time and ensure that it does what it’s supposed to do. The problem is that hackers will find ways to make the software do things it’s not supposed to do.
Today’s state of the art for software security involves using special tools to review the source code and to flag potential security weaknesses. Because that process produces a lot of false positives—flagging things that in fact are not weaknesses—a human being must then go through and check every case. To improve the bug-finding rate, some companies rely on white-hat hackers to do a one-time analysis or to participate in “bug bounty” programs, which pay them according to the number and the severity of the bugs they find. But only the most profitable companies can afford the strongest testing of their software. The issue grows more complex as finished software includes ever more components from open-source projects and other third parties.
The system we entered in the competition, Mayhem, automated what white-hat hackers do. It not only pointed to possible weaknesses, it exploited them, thus proving conclusively that they were in fact weaknesses. This was also a key part of the CGC, as demonstrating a proof of vulnerability with a working exploit was part of how your machine scored points. And because Mayhem was a machine that could be scaled up across hundreds or thousands of nodes, the analysis could proceed at a speed no human could match.
 Tower of Power: Like its six rivals in the DARPA competition, Mayhem required water cooling. However, power and temperature statistics showed that Mayhem consistently worked the hardest of them all.Photo: Chelsea Mastilak
Tower of Power: Like its six rivals in the DARPA competition, Mayhem required water cooling. However, power and temperature statistics showed that Mayhem consistently worked the hardest of them all.Photo: Chelsea Mastilak
To build Mayhem, we began with the first software-analysis system we developed at CMU, which is based on the formal analysis of a program. This method can be likened to creating a mathematical formula that represents every path a software program might take, thus producing an ever-branching tree of analysis. Such a tree can quickly get too big to manage, but we have found smart ways to collapse some of the paths, pruning the tree down to just a few branches. We are then able to explore the remaining branches more deeply.
Symbolic execution builds an equation to represent all the logic in a program—for example, “x + 5 = 7”—and then solve the equation. Contrast this strategy with another method of software analysis known as fuzzing, in which you feed random permutations of data into a program to crash it, after which you can determine the vulnerabilities that were at fault and how they might be exploited in a more deliberate attack. Fuzzing keeps putting in random data until a particular string of data makes the equation true, finally determining that x =2.
Both approaches have their strengths, but for many years fuzzing had the advantage because it was easier to implement and much faster at trying new inputs. Symbolic execution, meanwhile, held out a vast, untapped potential to whoever could learn to tame it. In the Mayhem system we started building in 2010, we were able to accomplish this feat by combining the two approaches.
Fuzzing is like making intelligent guesses at lightning speed about which inputs might trigger the program to engage in some new behavior, then keeping track of those inputs that actually do so. Symbolic execution is like asking a mathematician to try to formally figure out what inputs may exploit the program. We found that some bugs are best found by rapid guessing, others by the mathematical approach. So we decided to run both methods in parallel. Symbolic execution would reason about one part of the program deeply, coming up with an input to trigger that region of code. The system could then hand off that input to the fuzzing program, to rapidly hammer on that same region and shake out a vulnerability.
Another feature of Mayhem is that it can work directly on binary code, as opposed to human-coded text files—that is, source code. That means the system can analyze a program without the help of the person who developed it, which matters greatly for programs that incorporate third-party components for which the source code may no longer even exist. But reasoning about binary code is tough because, unlike source code, it has no functions, no local variables, and no data abstractions. Binary code has one big memory region and fixed-length bit vectors—a data structure that stores bits efficiently. You’d have to be a machine to work with such code, and indeed it required significant engineering to build a machine that could work under these constraints.
After Mayhem identifies a vulnerability, it generates a working exploit—that is, code of the sort a black-hat hacker might use to break into a program. The point is to demonstrate that the exploit can be used to obtain privileged, or root, access to the operating system. The result is that Mayhem identifies vulnerabilities with absolute certainty, rather than merely flagging possible problems, as most code-analysis tools do.
In 2014 we ran a test of the Mayhem technology on every program in the Debian distribution, a popular version of Linux that’s used on desktops and servers throughout the world. Mayhem found nearly 14,000 unique vulnerabilities, and then it narrowed that list down to 250 that were new and therefore deserved the highest priority. The entire test was done in less than a week by scaling Mayhem across a large number of servers in the Amazon cloud, with practically no human intervention. We submitted the more important findings to the online Debian community. One of the reasons we’ve spun off our research into a company is to be able to work at this scale with developers as we analyze thousands of programs with enormous numbers of vulnerabilities.
 The Mayhem Team: Engineers from ForAllSecure pose with their creation, Mayhem, at the closing ceremony. Author David Brumley is in the front row, third from the left.Photo: DARPA
The Mayhem Team: Engineers from ForAllSecure pose with their creation, Mayhem, at the closing ceremony. Author David Brumley is in the front row, third from the left.Photo: DARPA
On 3 June 2015, the 100-plus competitors entered the qualifying round and were given 131 unique purpose-built challenges, each one containing software security vulnerabilities. The seven teams with the highest security score (based on discovering vulnerabilities and patching them) made it into the Cyber Grand Challenge final event—and ForAllSecure scored more than twice as high as the next-best semifinalists. A temporary moment of joy was quickly succeeded by the realization that the pressure was really on now!
Taking the core Mayhem technology and building a fully autonomous cyber-reasoning system was a massive undertaking. We were able to do it in part because DARPA gave all seven finalists enough funding for a year of development work. Our core components included a tool set that translates executable programs into a language that’s relatively easy to understand and analyze, as well as offensive tools for finding and exploiting the vulnerabilities, defensive tools for automatically patching the defective binary code, and a program to coordinate the work efficiently.
In preparing for the final round, we faced two big challenges. First, although we were happy with how well Mayhem found vulnerabilities, we didn’t think the patches were efficient enough. In the competition, as in real life, you don’t want to install a patch that adds more processing power than solving that one problem is worth. We therefore spent a good deal of time building automated patching for vulnerabilities that had between 0 to 5 percent overhead—in the common case.
Second, we needed a strategy for playing and winning the game. Let’s say you find a vulnerability and make a patch for it. You may not want to field the patch right away if that would mean adding so much overhead that you slow the program down to a crawl. Instead, sometimes it’s better to wait, and patch only when absolutely necessary. We developed an expert system to decide when to patch.
When our team walked into the Las Vegas ballroom for the final competition on 5 August 2016, we saw seven hulking racks with blinking lights sitting atop a huge stage, below which were 180 tons of water to keep each team’s computers cool. Participants had set up the machines the previous night, before the competition began, and then DARPA had cut off all access to them. The machines were air-gapped—they had no connections to the outside world. All we could do was watch Mayhem toiling away, observing the power usage and system temperature stats reported by each system’s rack. Mayhem was consistently working the hardest of the seven competitors—a good sign, or so we hoped.
During nearly 100 rounds of competition, new programs were given to the competing systems, each of which had mere minutes to analyze the code for vulnerabilities and quickly issue patches to protect itself. Each round was scored based on the machine’s ability to find and prove vulnerabilities and on the performance of the patches.
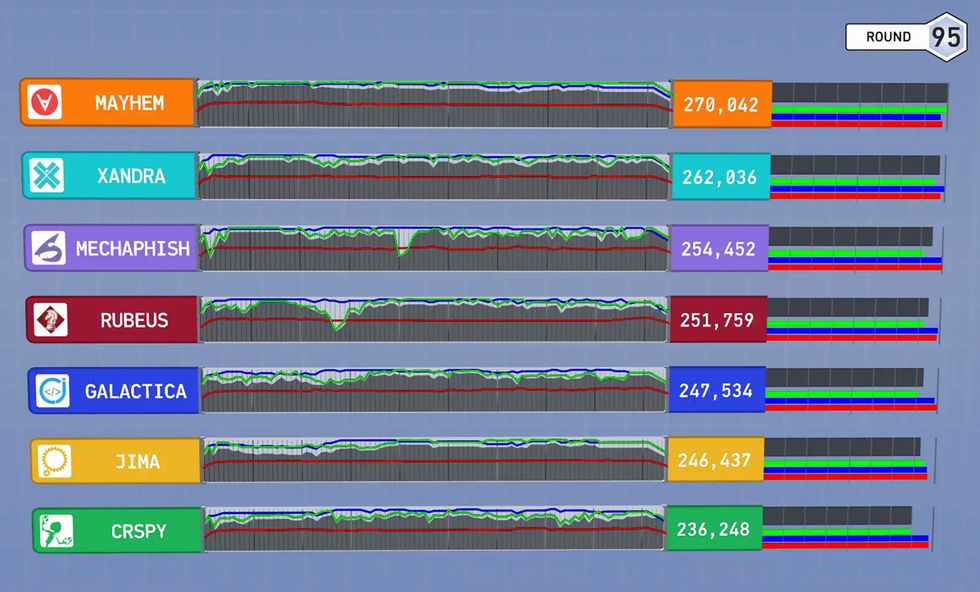 A Comfortable Win: Mayhem managed to build up a huge margin before suffering from a crash after the 40th round. That margin went unreported during the competition, leaving the team members in the dark until the very end.Photo: DARPA
A Comfortable Win: Mayhem managed to build up a huge margin before suffering from a crash after the 40th round. That margin went unreported during the competition, leaving the team members in the dark until the very end.Photo: DARPA
To make the final CGC event more exciting for spectators, the competition organizers had decided to report the scores only at the very end, in a play-by-play summary. That meant we didn’t really know if we were winning or losing, just that Mayhem was making submissions of vulnerabilities it had found. However, several hours into the competition, after round 40, we could tell that Mayhem had simply stopped submitting. The program had crashed.
Our stomachs lurched as our worst nightmare seemingly came true. We asked the organizers for a reboot, but they wouldn’t allow it. With half the competition still remaining, we began to contemplate the humiliation of defeat.
The play-by-play commentary started as the final round wrapped up, with fancy visualizations illustrating how each team’s machine had found and fixed security flaws in seconds, compared with the months or years a human team would have taken. The audience numbered over 5,000, and the guest commentators—an astrophysicist and star hackers—got them riled up. We braced ourselves to see our defeat announced and confirmed onscreen.
However, as we watched the scores come in with each new round, it occurred to us that Mayhem’s lead was great enough to keep it in first place, even though it had stopped playing after round 40. As the final rounds were announced, the weight was lifted from our shoulders. We had won.
Mike Walker, the DARPA program director, said that the event’s demonstration of autonomous cyberdefense was “just the beginning of a revolution” in software security. He compared the results to the initial flights of the Wright brothers, which didn’t go very far but pointed the way to transcontinental routes.
Right now, ForAllSecure is selling the first versions of its new service to early adopters, including the U.S. government and companies in the high-tech and aerospace industries. At this stage, the service mostly indicates problems that human experts then go in and fix. For a good while to come, systems like Mayhem will work together with human security experts to make the world’s software safer. In the more distant future, we believe that machine intelligence will handle the job alone.
This article appears in the February 2019 print issue as “The White-Hat Hacking Machine.”
About the Author
David Brumley is a professor of electrical and computer engineering at Carnegie Mellon University, in Pittsburgh, and cofounder and CEO of ForAllSecure, which creates autonomous cybersecurity tools.


